时间终于来到了十二月,据说,《黑客帝国 4:矩阵重生》 将于本月在北美上映,正如同它的片名一样,黑客帝国系列在沉寂了十八年后,终于等来了一次矩阵重生的机会,不可不谓“有生之年”、“爷青回”。提及黑客帝国系列,这是一部公认的、具有划时代意义的科幻电影,除了精彩绝伦的打斗特效,最为影迷所津津乐道的,当属对于人和机器的关系这种颇具哲学意味的问题的探讨。在第二部中,The One 的部分代码被融合到了 Smith 身上,而这使得 Smith 发生变异,成为了可以自我复制的病毒。于是,我们在这里看到了 Neo 和 100 个 Smith 打斗的桥段,类似的桥段还有第三部里的雨中决斗。这些桥段或多或少地影响到了后来的电影,譬如,星爷的 《功夫》 里,阿星与斧头帮、火云邪神打斗的片段;吴京的第一部电影 《狼牙》 里,阿布雨夜大战黑衣人的片段等等。虽然,病毒的自我复制和分布式系统中的复制,是两个完全不同的概念,可当我们试图将电影和现实联系起来的时候,我们还是会不免会心一笑,因为 100 个 Smith ,大概就相当于一个 Smith 的集群;而吞噬了先知能力的 Smith ,大概就相当于这个集群中的 Leader。我们注意到,强如超人般的 Neo,一样架不住越来越多的 Smith ,最后不得不飞走,所谓:“双拳难敌四手”,这足以说明集群的重要性。好了,既然这里聊到了集群,那么我们这次来聊聊 Redis 中的集群模式。
Redis 集群概述
通过上一篇文章,我们了解到,主从复制的作用主要体现在数据冗余、故障恢复、负载均衡等方面。可很多时候,我们讲分布式,并不是说简单的复制就好啦!相信大家都听说过,水平扩展和垂直扩展这两个概念,特别是数据库的水平扩展,它天然地和分片(Sharding)联系在一起,这意味是我们希望在不同地数据库/表里存储不同地数据。此前,博主曾在 《浅议 EF Core 分库分表及多租户架构的实现》 一文里介绍过数据库的分库/表,作为类比,我们可以归纳出 Redis 集群模式的第一个特点,即:它本质上是一种服务器 Sharding 技术。因为纯粹的主从复制意味着,每台 Redis 服务器都存储相同的数据,显然这造成了资源的浪费,而让每台 Redis 服务器存储不同的数据,这就是 Redis 的集群模式。如下图所示,Redis 集群模式呈现出的一种网状结构,完全不同于主从复制间的单向流动:

从图中可以看出,6 台服务器组成了一个网状结构,任意两台服务器间都可以相互通信。也许,大家会好奇一个问题,为什么这里博主就画了 6 台服务器?其实,这一切都是有迹可循的,因为 Redis 官方规定:一个集群中至少需要有 3 个主服务器(Master)。所以,一个 Redis 集群至少需要 6 台服务器。如果从这个角度来审视集群的定义的话,你可以认为 Redis 集群就是由多个主从复制一起对外提供服务。此时,集群中的节点都通过 TCP 连接和一个被称为 Cluster Bus 的二进制协议来建立通信,这里的 Cluster Bus 你可以将其理解为 Kafka 或者 RabbitMQ 这样的支持“发布-订阅”(Pub-Sub)机制的东西,换句话说,集群中的每个节点都可以通过 Cluster Bus 与集群中的其它节点连接起来。节点们使用一种叫做 Gossip 的消息协议,据说,这是一种从瘟疫和社交网站上获得灵感消息传播方式。“六度分割”理论告诉我们,最多通过 6 个人你就能认识任何一个陌生人,同样地,最多通过 6 个节点你就可以把消息传递给任何一个节点。

目前,使用 Gossip 这一协议的项目有 Redis Cluster、Consul、Apache Cassandra 等等, 关于这个协议以及“六度分割”理论更进一步的细节,大家可以通过搜索引擎来获取,对我们而言,我们只需要知道,Redis 集群需要借助这个协议来实现诸如发现新节点、发送 PING 包、发送集群消息这些功能,因为每个节点除了存储自身的数据以外,还需要记录集群的状态,需要知道哪些节点不可用,需要合适的时机推选出主节点。我们在主从复制这一篇文章中提到过故障恢复,这个概念在这里同样适用,如图所示,S1 是 M1 的从节点,它本身并不是为了扩展请求的并发量而存在的,它需要在主节点宕机的情况下能被提拔为主节点,所以,它主要起一个数据备份的作用。因此,Redis 集群中的读和写,实际上都是在M1、M2 和 M3 上进行的。那么,我们不妨来想这样一个问题,如果 M1 和 S1 都宕机了,此时 Redis 集群还能不能正常工作呢?答案是否定的,因为此时显然不满足最少 3 个主节点的要求。
一致性哈希算法
OK,我们知道,在面对数据库的水平拆分问题时,一个最为关键的问题是路由,换句话说,我怎么样可以找到到对应的库或者表。常见的思路有范围、哈希和配置等等,而在 Redis 的集群模式下,我们同样会面临这个问题,更一般地,任何需要负载均衡的场景都需要考虑这个问题,譬如,我们对多台服务器的 IP 地址求余,然后按照余数来进行路由,抑或者是按照不同的权重进行随机等等,这看起来像回到了熟悉的负载均衡算法,对吗?事实上,一般的负载均衡算法都会选择哈希算法,而哈希算法本质上就是一种散列函数,它可以把任意长度的输入转化为确定的、固定长度的输出,以最常见的求余为例,它具体是怎么工作的呢?我们来一起看下面的图:

可以注意到,首先,我们需要对 Key 计算出一个 hash 值,你可以理解为编程语言里的GetHashCode()方法,主要目的是将字符串类型的 Key 转化为整数型方便计算。接下来,按照主节点的数量来进行求余运算(统称为散列运算),例如,这里我们有 3 台主节点服务器,故而在上面的图示中 n 应该等于 3,而这就是经典的哈希算法啦!那么,Redis 的集群有没有采用这个算法呢?答案还是否定的,因为这个方案里最大的变数就是 n。具体来讲,如果你想要扩容,那么 n 会变大,此时 Key 与服务器间的映射关系会被打破,即使不扩容,一旦某台服务器宕机,Key 与服务器间的映射关系还是会被打破,如果出现散列“碰撞”,无疑会让问题变得更复杂。

可以注意到,当从对 3 取模变成对 2 取模以后,必然会出现两个 1,这就是所谓的散列“碰撞”。所以,对于经典的哈希算法而言,它无法抵消因为 n 的变化而带来的重新 hash 的问题。为了解决这个问题,业界普遍使用的是一致性哈希算法,相比经典的哈希算法,最大的变化在于它将 n 的取值固定下来,即按 2^32 取模,此时,结果会落在 0 到 2^32 - 1 这个区间内,一旦我们将这个区间抽象为一个圆环,利用 CRC16 算法计算出来的值就会落在圆环上的某个地方:

如图所示,假设我们有 A、B、C 三个 Redis 节点,它们均按照顺时针方向排列在整个圆环上,当我们对每一个 Redis 节点进行 hash() 运算以后按 2^32 取模,此时,这个值依然会落在 0 到 2^32 - 1 这个区间内,以此类推,理论上对于任意一台服务器 X,我们总能找到对应的一个值,当该值介于区间(m, n)中,表示它分配在节点 n 上,你可以认为,每个服务器节点,它负责的并不是哈希环上的一个点,而是一个范围。基于这种特性,当某一台 Redis 服务器宕机时,对应的这个区间会变大,相当于流量从这个节点转移到了它的下一个节点,这意味着我们只需要移动一部分数据。同理,如果要增加节点,只需要把移动该节点到它上一个节点间的数据。由此可见,它对原来数据的影响非常小,而这就是一致性哈希算法。
Redis 哈希槽
截止到现在,我们知道了,一致性哈希算法相对经典哈希算法的优势,可这个算法真的没有问题吗?我们应该会想到,节点在哈希环上的分布是不均匀的,这意味着,每个节点上对应的 Key 的数量各不相同,更进一步,我们可以说,每台 Redis 上存储的数据量不同,这样,原本期待着负载均衡的我们,此刻被光速地打脸。因此,在实际应用中,为了让哈希环分布更均匀一点,会设置所谓的“虚拟节点”。不过,就算你考虑到了这种地步,Redis 还是没有采用这种哈希一致性的方案,你说这是不是有点气人?事实上,它采用的是一种被称为哈希槽的方案:

如图所示,Redis 集群中总共有 16384 个槽位,它是怎么算出来的呢?因为 CRC16 算法产生的 hash 值有 16 个 bit,因此,它可以产生 2^16 即 65536 个值,理论上我们完全可以分配 65536 个槽位,不过考虑到网络带宽、节点数目,作者觉得 16384 个槽位完全够用了,前提是你集群内的节点不超过 1000 个!是不是听起来觉得非常离谱?可有些时候,工程上的事情,还真不能按科学一板一眼的来,不然,你又怎么会见到各种各样的“敏捷开发”、”项目管理”呢?

OK,对于 Redis 中的每一个 Key,它经过计算以后会落到某个具体的槽位内,至于槽位会路由到哪个机器上,这完全取决于每台 Redis 服务器的配置,硬盘大就多分一点,硬盘小就少分一点,“能者多劳”,听起来就很科学,对吧!所以,从这个角度来看,相比哈希环,哈希槽可以更加灵活地控制槽位的分布。可世间万物,无一不是双刃剑,你选择了自由,那么需要操心的事情就变多了,至少 Redis 集群不会帮你转移和分配槽位;你选择了秩序,一切井井有条,那么你内心又会期盼自由。“小而美”,想要面面俱到;“大而全”,想要细致入微,难怪刺客组织要和圣殿骑士间的斗争永无止息啊,哈哈……因此,Redis 集群的高可用,实际上非常依赖主从节点的主从复制和故障切换,我承认,我点题了,你发现了吗?
Redis 集群实战
好了,和上一篇一样,我们先礼后兵,等所有的理论知识都讲完了,再来着眼实际的过程,因为在博主看来,这是一个互相印证的过程,写流水账、记下每一步的操作步骤,这固然可以让你快速上手,但你真的只愿意到此为止吗?博主以前学过 CAD,近来又开始学习 Blender,一个深刻的感受就是,这些软件都需要大量的重复练习,甚至于形成肌肉记忆。可是我们学习知识的过程,是一个反复提炼、内化的过程,我们并不是为了成为某种“熟练工”,我发现有很多朋友,特别喜欢问某软件/工具怎么安装/配置类似的问题,虽然说这是技术人员日常生活里的一部分,但我觉得这不应该成为你特别关注的问题,所以,如果你发现我越来越不像是在写教程,恭喜你,发现了我的改变,谢谢你啊!回到正题,我们还是准备一个最小的集群,即“三主三从”的一个集群,依然使用 docker-compose 进行服务编排。首先,准备下面的目录结构:
Clusters
|-- docker-compose.yaml
|-- redis-1
| |-- redis.conf
|-- redis-2
| |-- redis.conf
|-- redis-3
| |-- redis.conf
|-- redis-4
| |-- redis.conf
|-- redis-5
| |-- redis.conf
|-- redis-6
| |-- redis.conf
此时,针对集群模式的 Redis 配置文件,相比主从复制模式要精简许多,以其中一台服务器7001为例:
# 端口号
port 7001
# 启用集群
cluster-enabled yes
cluster-config-file nodes_7001.conf
cluster-node-timeout 5000
appendonly yes
照葫芦画瓢,我们准备好剩下的7002、7003、7004、7005、7006 这 5台服务器即可。接下来,我们准备服务编排文件docker-compose.yaml:
version: '3.1'
services:
redis1:
image: redis:latest
container_name: redis-1
restart: always
network_mode: "host"
volumes:
- ./redis-1/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server", "/usr/local/etc/redis/redis.conf"]
redis2:
image: redis:latest
container_name: redis-2
restart: always
network_mode: "host"
volumes:
- ./redis-2/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server", "/usr/local/etc/redis/redis.conf"]
redis3:
image: redis:latest
container_name: redis-3
restart: always
network_mode: "host"
volumes:
- ./redis-3/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server", "/usr/local/etc/redis/redis.conf"]
redis4:
image: redis:latest
container_name: redis-4
restart: always
network_mode: "host"
volumes:
- ./redis-4/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server", "/usr/local/etc/redis/redis.conf"]
redis5:
image: redis:latest
container_name: redis-5
restart: always
network_mode: "host"
volumes:
- ./redis-5/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server", "/usr/local/etc/redis/redis.conf"]
redis6:
image: redis:latest
container_name: redis-6
restart: always
network_mode: "host"
volumes:
- ./redis-6/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server", "/usr/local/etc/redis/redis.conf"]
接下来,我们运行 docker-compose up命令,就可以看到 6 台 Redis 服务器都运行起来,此时,我们需要选择任意一台 Redis 服务器对应的容器内,执行下列命令:
redis-cli --cluster create
127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 \
127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 \
--cluster-replicas 1
该命令表示创建一个由 6 台服务器组成的集群,其中,--cluster-replicas 参数表示每个主节点分配一个从节点。此时此刻,当我们按下回车后,就可以看到下面的画面:

可以注意到,当前集群有 3 台主服务器节点:7001、7002 和 7003,有 3 台从服务器节点:7004、7005 和 7006,这符合我们一开始设想的“三主三从”,Redis 内部会为每个节点分配一个唯一的 Id,这个 Id 会和每个节点的 IP 地址、端口号一起保存下来。当我们没有显式地分配每台服务器对应多少个槽位时,它会按照主节点的数量平均地分割。在这里我们只有 3 台主节点服务器,无法被 16384 整除,所以,7002 这个服务器会多分配一个槽位。显然,Redis 需要我们来确定这个集群划分,此时,我们输入yes即可,这样我们就完成了 Redis 集群的搭建。接下来,我们通过 redis-cli 写入信息来看看集群实际的运行效果:
# 进入 Redis 容器
docker exec -it df5cae3c6004 sh
# 连接 7001 服务器
redis-cli -p 7001 -c
# 写入一个 key
127.0.0.1:7001> set name yuanpei
我们会发现一个现象,就是 Redis 会告诉你这里有一次重定向,如图所示,它从 7001 重定向到了 7002,这是因为按照 CRC16 算法计算出的结果,name 这个键应该被分配到 7002 上存储:

同理,在我们已经知道 name 这个键存储在 7002上的情况下,我们依然可以从集群中的其它节点上读取到这个值:

可以注意到,集群依然可以自动地从 7004 重定向到 7002,这表明,我们可以从集群中的任何一个节点上查询数据,并且每个节点上都存储着不同的数据,这可不就是数据分片吗?这恰恰印证了我一开始的观点,即:Redis 的集群模式,本质上是一种服务器 Sharding 技术。果然,博主诚不欺人也,哈哈!
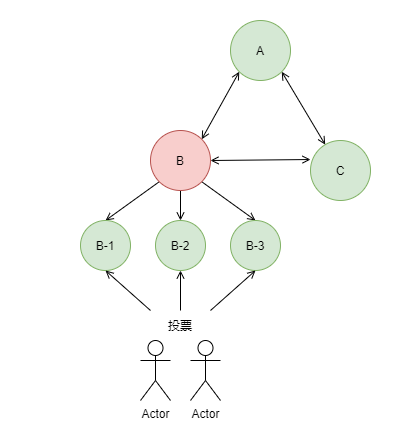
到目前为止,我们已经搭建出了一个基本的 Redis 集群,你可能会问,如果集群中某个节点发生宕机该怎么办呢?此时,我们要注意区分,这是主观宕机还是客观宕机。什么是主观宕机呢?就是某个节点认为你挂了;什么是客观宕机呢?就是集群内超过半数的节点认为你挂了。事实上,只有客观宕机会触发故障转移,而所谓的故障转移,其实就是从故障节点的从节点中挑选一个出来继续提供服务,此时,需要有超过半数以上的主节点给这个从节点投票,这样,Redis 集群就会让它当选为新的主节点,谁能想到,在以绝对理性著称的技术世界里,居然会有如此民主而科学的做法呢?可少数服从多数,真的就是对的吗?
本文小结
坦白讲,这篇文章写起来非常费劲,因为它里面关联的知识点非常密集,从经典哈希算法到一致性哈希算法,再到 Redis 集群里的哈希槽,这是一个循序渐进的认知过程,我们由此认识到,Redis 的集群模式,本质上是由多个主从复制模式组成的服务器分片技术,它通过哈希槽来管理集群内的节点和数据,而节点间则是通过 TCP 协议互相通信,这使得我们可以从任意节点上查询数据,因为 Redis 集群会帮助我们实现连接的重定向。与此同时,Redis 集群内通过投票来实现故障转移,其触发机制是超过半数的节点认为该节点宕机,即客观宕机,此时,就需要从该节点的从节点中筛选一个继续提供服务,当然,这个筛选还是投票决定的,谁能说这不是一种现实世界的投影呢?好了,以上就是这篇博客的全部内容啦,关于 Gossip 协议等更细节的东西,留到以后有机会再写吧…..!


