终于等到了周末,在经历了一周的忙碌后,终于可以利用空闲写篇博客。其实,博主有一点困惑,困惑于这个世界早已“堆积”起人类难以想象的“大”数据,而我们又好像执着于去“造”一个又一个“差不多”的“内容管理系统”,从前我们说互联网的精神是开放和分享,可不知从什么时候起,我们亲手打造了一个又一个的“信息孤岛”。而为了打通这些“关节”,就不得不去造一张巨大无比的蜘蛛网,你说这就是互联网的本质,对此我表示无法反驳。我更关心的是这其中最脆弱的部分,即:一条数据怎么从 A 系统流转到 B 系统。可能你会想到API或者ETL这样的关键词,而我今天想说的关键词则是Binlog。假如你经常需要让数据近乎实时地在两个系统间流转,那么你应该停下来听我——一个不甘心整天写CRUD换取996福报的程序员,讲讲如何通过Binlog实现数据同步和订阅的故事。
什么是 Binlog
首先,来回答第一个问题,什么是 Binlog?Binlog 即 Binary Log,是 MySQL 中的一种二进制日志文件。它可以记录MySQL内部对数据库的所有修改,故,设计 Binlog 最主要的目的是满足数据库主从复制和增量恢复的需要。对于主从复制,想必大家都耳熟能详呢,因为但凡提及数据库性能优化,大家首先想到的所谓的“读写分离”,而无论是物理层面的一主多从,还是架构层面的CQRS,这背后最大的功臣当属主从复制,而实现主从复制的更底层原因,则要从 Binlog 说起。而对于数据库恢复,身为互联网从业者,对于像“rm -f”和“删库”、“跑路”这些梗,更是喜闻乐见,比如像今年的绿盟删库事件,在数据被删除以后,工程师花了好几天时间去抢救数据,这其中就用到了 Binlog。
可能大家会好奇,为什么 Binlog 可以做到这些事情。其实,从 Binlog 的三种模式上,我们就可以窥其一二,它们分别是:Statement、Row、Mixed,其中Statement模式记录的是所有数据库操作对应的 SQL 语句,如 INSERT、UPDATE 、DELETE 等 DML 语句,CREATE 、DROP 、ALTER 等 DDL,所以,从理论上讲,只要按顺序执行这些 SQL 语句,就可以实现不同数据库间的数据复制。而Row模式更关心每一行的变更,这种在实际应用中会更普遍一点,因为有时候更关心数据的变化情况,例如一个订单被创建出来,司机通过 App 接收了某个运输任务等。而Mixed模式可以认为是Statement模式和Row模式的混合体,因为Statement模式和Row模式都有各自的不足,前者可能会导致数据不一致,而后者则会占用大量的存储空间。在实际使用中,我们往往会借助各种各样的工具,譬如官方自带的mysqlbinlog、支持 Binlog 解析的StreamSets等等。
好了,下面我们简单介绍下 Binlog 相关的知识点。在使用 Binlog 前,首先需要确认是否开启了 Binlog,此时,我们可以使用下面的命令:
SHOW VARIABLES LIKE 'LOG_BIN'
如果可以看到下面的结果,则表示 Binlog 功能已开启。
 Binlog已开启示意图
如果 Binlog 没有开启怎么办呢?此时,就需要我们手动来开启,为此我们需要修改 MySQL 的
Binlog已开启示意图
如果 Binlog 没有开启怎么办呢?此时,就需要我们手动来开启,为此我们需要修改 MySQL 的my.conf文件,通常情况下,该文件位于/etc/my.cnf路径,在[mysqld]下写入如下内容:
# 设置Binlog存储目录
log_bin = /var/lib/mysql/bin-log
# 设置Binlog索引存储目录
log_bin_index = /var/lib/mysql/mysql-bin.index
# 删除7天前的Binlog
expire_logs_days = 7
# 集群内MySQL服务器的ID
server_id = 0002
# 设置Binlog日志模式
binlog_format = ROW
除此之外,我们还可以设置下面这些选项:
# 设置Binlog文件最大的大小
max_binlog_size
# 设置当前多少个事务缓存在内存中
binlog_cache_size
# 设置当前多少个事务暂存在磁盘上
binlog_cache_disk_use
# 设置最大有多少个事务缓存在内存中
max_binlog_cache_size
# 设置选取或者忽略的数据库
binlog_do_db/binlog_ingore_db
设置完以后,通过下面的命令重启 MySQL 即可:
service mysql restart
或者
service mysqld restart
通常,我们可以通过下面的命令来获取 Binlog 的当前状态,请注意,该命令必须要在主库上执行:
SHOW MASTER STATUS
此时,我们会得到下面的结果:
 查看Binlog状态
这里可以得到三个重要的信息,即从日志文件
查看Binlog状态
这里可以得到三个重要的信息,即从日志文件mysql-bin.000388的特定位置135586062开始,可以获得一组新的日志信息,而这些日志信息都是来自数据库实例b1328d03-0b5c-11ea-8ee8-005056a1616f:1-27768340。有了这三个信息以后,我们就可以去查看对应的 BinLog,此时,我们需要使用到下面的命令:
SHOW BINLOG EVENTS IN 'MYSQL-BIN.000388' FROM 135586062
此时,ROW 模式下的 Binlog 如下图所示:
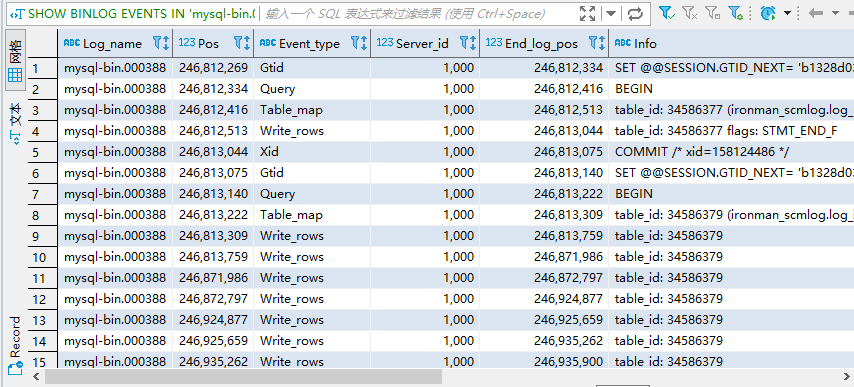 ROW模式下的Binlog
可以注意到,这些 Binlog 由不同的事件构成。如果你是在 MySQL 终端下输入命令,那么,你还可以使用官方自带的工具
ROW模式下的Binlog
可以注意到,这些 Binlog 由不同的事件构成。如果你是在 MySQL 终端下输入命令,那么,你还可以使用官方自带的工具mysqlbinlog,博主这里使用的开源的数据库工具DBeaver,如果你经常需要和不同的数据库打交道,而又不想每一种数据库都去安装一个客户端的话,我认为这是一个非常不错的选择。关于 Binlog 的使用我们就先暂时说到这里,因为还有更重要的事情要做。
Binlog 有什么用
实现数据库审计
你可能觉得我明知故问,你刚刚不是说 Binlog 主要用来做主从复制和增量恢复吗?自然,这是 Binlog 在设计之初的主要用途。可我们都知道,事物有时候并不会想着我们期待的方向发展,譬如原子弹成为战争机器、社交软件成为“约炮神器”、共享单车成为“城市垃圾”等等。还记得博主曾经写过一篇关于数据库审计的[博客](https://blog.yuanpei.me/posts/1289244227/吗?当时,我们是重写了 EF/EF Core 中 DbContext 的 SaveChanges()方法,并借助 ChangeTracker 对获取实体修改前后的值。其实,从现在的角度来看,我们有更好的选择,毫无疑问,Row 模式下的 Binlog 本身就是天然的数据库审计,每一行数据变化前后的情况,我们都可以获得,并且可以区分出它是 Insert ,还是 Update,还是 Delete,所以,Binlog 的第一个用途就是可以用来做数据库审计,因为它发生在数据库层,从某种意义上来讲,消解了 EF 和 Dapper 这种 ORM 间的差异。
实现事件驱动
其次,我们在实际业务中,常常需要用到"领域事件“这个概念,即使项目并没有采用**领域驱动设计(DDD)**的思想,即使项目中并没有采用”事件驱动“的业务模式,可事实就是,总有人关心着数据的产生和变更,而能提供给第三方系统订阅自己感兴趣的事件的能力,无疑要比开发一个又一个大同小异的同步接口要好得多,推(Push)模式在大多数情况下要比拉(Pull)模式要好,为什么呢?因为数据传输的压力更小,更能满足数据实时性的要求。然而,由于没有按照领域模型去设计业务,导致事件代码与业务代码耦合非常严重,基于 Binlog 的事件分发机制显然有更好的普适性。以博主最近处理的业务为例,A 系统中的司机、设备、用户在新建/更新更新时,需要把新数据推送到 B 系统,因为这类纯数据类的"变化"没有实际业务意义,所以,人们不舍得为这些变化去分发事件,而要想分发事件,又不得不去面对强耦合带来的阵痛,所以,Binlog 的第二个用途是可以作为事件源来实现事件驱动。
业内主流方案
如果你觉得通过第一节的内容,可以非常容易地实现 Binlog 的解析,那么,我觉得你并没有想清楚 Binlog 处理过程中的难点在哪里?首先,每次读取 Binlog,必须要知道对应的日志文件和位置,而如果在新的 Binlog 产生前,没有处理完原来的 Binlog,就必须要记录对应的日志文件和位置,而且经过博主本人测试,Binlog 无法直接给查询语句追加过滤条件,来达到筛选某些数据库、表以及事件的目的,而且日志文件的格式会因为模式的不同而不同,最主要的一点是,直接在主库上读取 Binlog 会给数据库带来访问压力,所以,主流的方案,是让客户端伪装成“从库”,关于一点,我们可以配合下面的图片来理解。
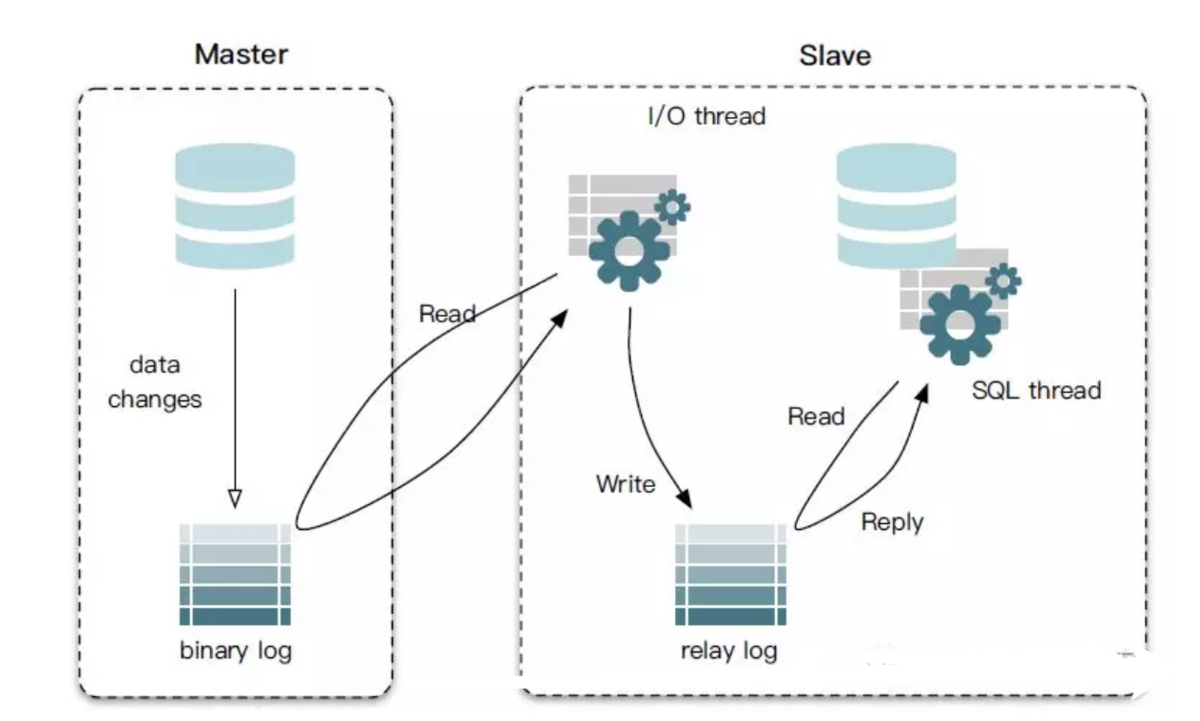 MySQL主从复制原理
可以注意到,完成主从复制需要一个 Relaylog + 两个线程,即,主库产生的 Binlog,首先由从库的 I/O 线程进行读取,这一步会产生 Relaylog,顾名思义,这是一个处在中间状态的中继日志,而中继日志最终会交由从库的 SQL 线程来处理,所以,这是从库执行 SQL 语句的阶段,整个过程是异步化的操作,所以,不会对主库产生太大的压力。如果我们直接读取主库的 Binlog,实际上是把所有压力都转移到主库,不仅需要负责“读”,还需要复杂“写”。主流的方案,目前比较推荐的是阿里的Canal、Zendesk 的Maxwell、以及来自社区的Python-Mysql-Replication,下面是一个简单的对比,方便大家做技术选型。
MySQL主从复制原理
可以注意到,完成主从复制需要一个 Relaylog + 两个线程,即,主库产生的 Binlog,首先由从库的 I/O 线程进行读取,这一步会产生 Relaylog,顾名思义,这是一个处在中间状态的中继日志,而中继日志最终会交由从库的 SQL 线程来处理,所以,这是从库执行 SQL 语句的阶段,整个过程是异步化的操作,所以,不会对主库产生太大的压力。如果我们直接读取主库的 Binlog,实际上是把所有压力都转移到主库,不仅需要负责“读”,还需要复杂“写”。主流的方案,目前比较推荐的是阿里的Canal、Zendesk 的Maxwell、以及来自社区的Python-Mysql-Replication,下面是一个简单的对比,方便大家做技术选型。
| Cancal | Maxwell | Python-Mysql-Rplication | |
|---|---|---|---|
| 开源方 | 阿里巴巴 | Zendesk | 社区 |
| 开发语言 | Java | Java | Python |
| 活跃度 | 活跃 | 活跃 | 活跃 |
| 高可用 | 支持 | 支持 | 不支持 |
| 客户端 | Java/Go/PHP/Python/Rust | 无 | Python |
| 消息落地 | Kafka/RocketMQ 等 | Kafka/RabbitNQ/Redis 等 | 自定义 |
| 消息格式 | 自定义 | JSON | 自定义 |
| 文档详略 | 详细 | 详细 | 详细 |
| Boostrap | 不支持 | 支持 | 不支持 |
说说我的构想
众所知周,我是一个有一点“懒惰”的人,考虑到前面两种方案都比较重,即使通过 Docker 来安装。对我来说,这是一个验证想法的过程,所以,我选择的搭配是 RabbitMQ + .NET Core + Python 的方案,因为 Kafka 需要 ZooKeeper,而在验证想法的阶段,自然是越简单越好。我正打算参考微软的 eShopOnContainers 的项目, 实现一个消息总线(EventBus),恰好这个项目中使用了 RabbitMQ,而且从某种意义上来说,RabbitMQ 更接近传统意义上的消息队列,它提供的重试、确认、死信等这些机制都比较完善,可以让我把精力集中在快速实现上,毕竟你看到这些博客,都是我挤出时间来完成的。选择 Python 就更直接了,因为安装、运行都非常容易,或许 Kafka 的吞吐性能更好,但我觉得掌握核心思想才是最重要的吧!
总而言之,在这里,我选择了自己最熟悉的技术栈。整体思路是,首先,.NET Core + RabbitMQ 实现一个消息总线,并对外提供发布事件的 API 接口。其次,利用 Python-Mysql-Replication 实现一个读取 Binlog 的后台程序,这些 Binlog 最终会以 JSON 的形式发布到 RabbitMQ 上。最后,实现针对特定事件的 IEventHandler接口,消息总线会自动调用这些 Handler 去处理消息。至此,就实现了针对 Binlog 的订阅和消费。众所周知,消息总线的一大优点就是解耦,我们就可以摆脱以往定时轮询 + 打标记(Flag)的宿命轮回,只需要编写对应的 Handler 即可,其实我觉得这是一种思维上的转变,就是"主动"到"被动"的转变,并不是说我们帮客户做得越多越好,而是我们能让客户意识到它可以做哪些事情。同样的,我绘制了一个简单的流程图来作为说明:
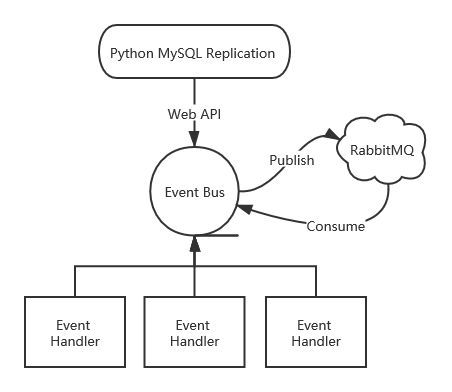 基于RabbitMQ的EventBus实现
基于RabbitMQ的EventBus实现
本文小结
其实,重复的工作做久了都会感到厌烦的,所以,真正让你摆脱“体力劳动”的只能是换一种高度来看问题。这几年做 2B 业务下来,最大的体会是企业级软件最难的是,如何在各种种类繁多的软件,譬如 OA 、金蝶、用友、SAP 、ERP 、CRM 等中做好一个“配角”,数据如果无法在这张网络中流通,则永远都是一潭死水,而如果要打通各个系统间的数据,则免不了写一个又一个的同步接口。这篇博客以 MySQL 的 Binlog 为切入点,试图通过 Binlog 来实现特定业务的“事件驱动”。Binlog 是实现主从复制的重要机制,而基于这一机制,业界普遍的做法是利用 MySQL 的交换协议,让客户端"伪装"成一个从库,在比较了 Canal 、Maxwell 以及 Python-Mysql-Replication 后,博主选择了. NET Core + RabbitMQ + Python 的方案,目标是让 Binlog 可以发布到消息总线(EventBus)中供消费者订阅和消费。在下一篇博客中,我们讲介绍基于 RabbitMQ 实现一个消息总线(EventBus)的相关细节,欢迎大家继续关注我的博客,今天这篇博客就先写到这里,大家晚安!


