此时此刻,2020 年的最后一个月,不管过去这一年给我们留下了怎样的记忆,时间终究自顾自地往前走,留给我们的怀念已时日无多。如果要说 2020 年的年度日剧,我想《半泽直树》实至名归,这部在时隔七年后上映的续集,豆瓣评分高达 9.4 分,一度超越 2013 年第一部的 9.3 分,是当之无愧的现象级电视剧,期间甚至因为疫情原因而推迟播出,这不能不感谢为此付出辛勤努力的演职人员们。身为一个“打工人”,主角半泽直树那种百折不挠、恩怨分明的性格,难免会引起你我这种“社畜”们的共鸣,即使做不到“以牙还牙,加倍奉还”,至少可以活得像一个活生生的人。电视剧或许大家都看过了,那么,电视剧相对于原著小说有哪些改动呢?今天,就让我们使用 Python 来抽取半泽直树原著小说中的人物关系吧!
准备工作
在开始今天的博客内容前,我们有一点准备工作要完成。考虑到小说人物关系抽取,属于自然语言处理(NLP)领域的内容,所以,除了准备好 Python 环境以外,我们需要提前准备相关的中文语料,在这里主要有:半泽直树原著小说、 半泽直树人名词典、半泽直树别名词典、中文分词停用词表。除此之外,我们需要安装结巴分词、PyECharts两个第三方库(注,可以通过 pip 直接安装),以及用于展示人物关系的软件Gephi(注,这个软件依赖 Java 环境)。所以,你基本可以想到,我们会使用结巴分词对小说文本进行分词处理,而半泽直树人名列表则作为用户词典供结巴分词使用,经过一系列处理后,我们最终通过Gephi和PyECharts对结果进行可视化,通过分析人物间的关系,结合我们对电视剧剧情的掌握情况,我们就可以对本文所采用方法的效果进行评估,也许你认为两个人毫无联系,可最终他们以某种特殊的形式建立了联系,这就是我们要做这件事情的意义所在。本项目已托管在 Github上,供大家自由查阅。
原理说明
这篇博客主要参考了 Python 基于共现提取《釜山行》人物关系 这个课程,该项目已在 Github 上开源,可以参考:https://github.com/Forec/text-cooccurrence。这篇文章中提到了一种称之为“共现网络”的方法,它本质上是一种基于统计的信息提取方法。其基本原理是,当我们在阅读书籍或者观看影视作品时,在同一时间段内同时出现的人物,通常都会存在某种联系。所以,如果我们将小说中的每个人物都看作一个节点,将人物间的关系都看作一条连线,最终我们将会得到一个图(指数据结构中的Graph)。因为Gephi和PyECharts以及NetworkX都提供了针对Graph的可视化功能,因此,我们可以使用这种方法,对《半泽直树》原著小说中的人物关系进行抽取。当然,这种方法本身会存在一点局限性,这些我们会放在总结思考这部分来进行说明,而我们之所以需要准备人名词典,主要还是为了排除单纯的分词产生的干扰词汇的影响;准备别名词典,则是考虑到同一个人物,在不同的语境下会有不同的称谓。
过程实现
这里,我们定义一个RelationExtractor类来实现小说人物关系的抽取。其中,extract()方法用于抽取制定小说文本中的人物关系,exportGephi()方法用于输出 Gephi 格式的节点和边信息, exportECharts()方法则可以使用ECharts对人物关系进行渲染和输出:
import os, sys
import jieba, codecs, math
import jieba.posseg as pseg
from pyecharts import options as opts
from pyecharts.charts import Graph
class RelationExtractor:
def __init__(self, fpStopWords, fpNameDicts, fpAliasNames):
# 人名词典
self.name_dicts = [line.strip().split(' ')[0] for line in open(fpNameDicts,'rt',encoding='utf-8').readlines()]
# 停止词表
self.stop_words = [line.strip() for line in open(fpStopWords,'rt',encoding='utf-8').readlines()]
# 别名词典
self.alias_names = dict([(line.split(',')[0].strip(), line.split(',')[1].strip()) for line in open(fpAliasNames,'rt',encoding='utf-8').readlines()])
# 加载词典
jieba.load_userdict(fpNameDicts)
# 提取指定小说文本中的人物关系
def extract(self, fpText):
# 人物关系
relationships = {}
# 人名频次
name_frequency = {}
# 每个段落中的人名
name_in_paragraph = []
# 读取小说文本,统计人名出现的频次,以及每个段落中出现的人名
with codecs.open(fpText, "r", "utf8") as f:
for line in f.readlines():
poss = pseg.cut(line)
name_in_paragraph.append([])
for w in poss:
if w.flag != "nr" or len(w.word) < 2:
continue
if (w.word in self.stop_words):
continue
if (not w.word in self.name_dicts and w.word != '半泽'):
continue
# 规范化人物姓名,例:半泽->半泽直树,大和田->大和田晓
word = w.word
if (self.alias_names.get(word)):
word = self.alias_names.get(word)
name_in_paragraph[-1].append(word)
if name_frequency.get(word) is None:
name_frequency[word] = 0
relationships[word] = {}
name_frequency[word] += 1
# 基于共现组织人物关系
for paragraph in name_in_paragraph:
for name1 in paragraph:
for name2 in paragraph:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2] = 1
else:
relationships[name1][name2] += 1
# 返回节点和边
return name_frequency, relationships
# 输出Gephi格式的节点和边信息
def exportGephi(self, nodes, relationships):
# 输出节点
with codecs.open("./output/node.txt", "w", "gbk") as f:
f.write("Id Label Weight\r\n")
for name, freq in nodes.items():
f.write(name + " " + name + " " + str(freq) + "\r\n")
# 输出边
with codecs.open("./output/edge.txt", "w", "gbk") as f:
f.write("Source Target Weight\r\n")
for name, edges in relationships.items():
for v, w in edges.items():
if w > 0:
f.write(name + " " + v + " " + str(w) + "\r\n")
# 使用ECharts对人物关系进行渲染
def exportECharts(self, nodes, relationships):
# 总频次,用于数据的归一化
total = sum(list(map(lambda x:x[1], nodes.items())))
# 输出节点
nodes_data = []
for name, freq in nodes.items():
nodes_data.append(opts.GraphNode(
name = name,
symbol_size = round(freq / total * 100, 2),
value = freq,
)),
# 输出边
links_data = []
for name, edges in relationships.items():
for v, w in edges.items():
if w > 0:
links_data.append(opts.GraphLink(
source = v,
target = w,
value = w
))
# 绘制Graph
c = (
Graph()
.add(
"",
nodes_data,
links_data,
gravity = 0.2,
repulsion = 8000,
is_draggable = True,
symbol = 'circle',
linestyle_opts = opts.LineStyleOpts(
curve = 0.3,
width = 0.5,
opacity = 0.7
),
edge_label = opts.LabelOpts(
is_show = False,
position = "middle",
formatter = "{b}->{c}"
),
)
.set_global_opts(
title_opts = opts.TitleOpts(title="半泽直树原著小说人物关系抽取")
)
.render("./docs/半泽直树原著小说人物关系抽取.html")
)
你可以注意到,在input目录中,博主已经准备好了中文语料。因此,我们可以通过下面的代码来完成任务关系抽取:
extractor = RelationExtractor('./input/停用词词典.txt',
'./input/人名词典.txt',
'./input/别名词典.txt'
)
nodes, relationships = extractor.extract('./input/半泽直树.txt')
extractor.exportGephi(nodes, relationships)
extractor.exportECharts(nodes, relationships)
此时,我们可以分别在output目录和docs目录获得Gephi和ECharts相关的渲染结果。
结果展示
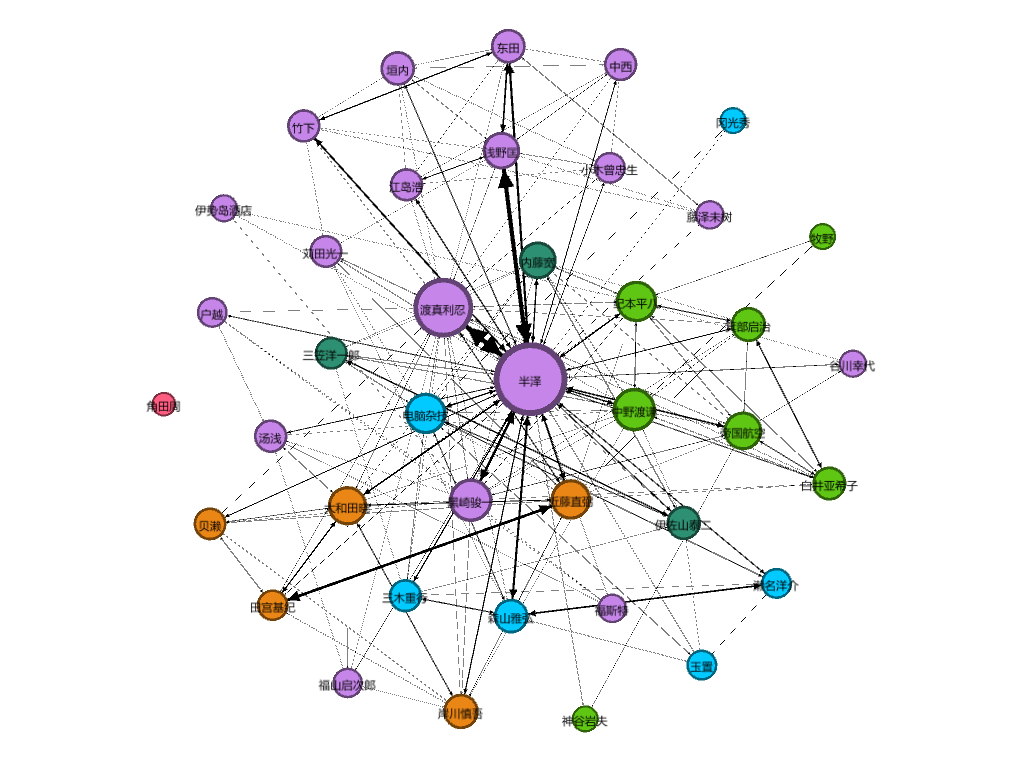
这里,通过 Gephi 软件导入生成的节点和边信息,这两个信息默认情况下在output目录下。如果你熟悉这个软件的使用的话,你可以得到下面的结果:
作为对比,博主这里同时提供了使用 ECharts 渲染的小说人物关系图:
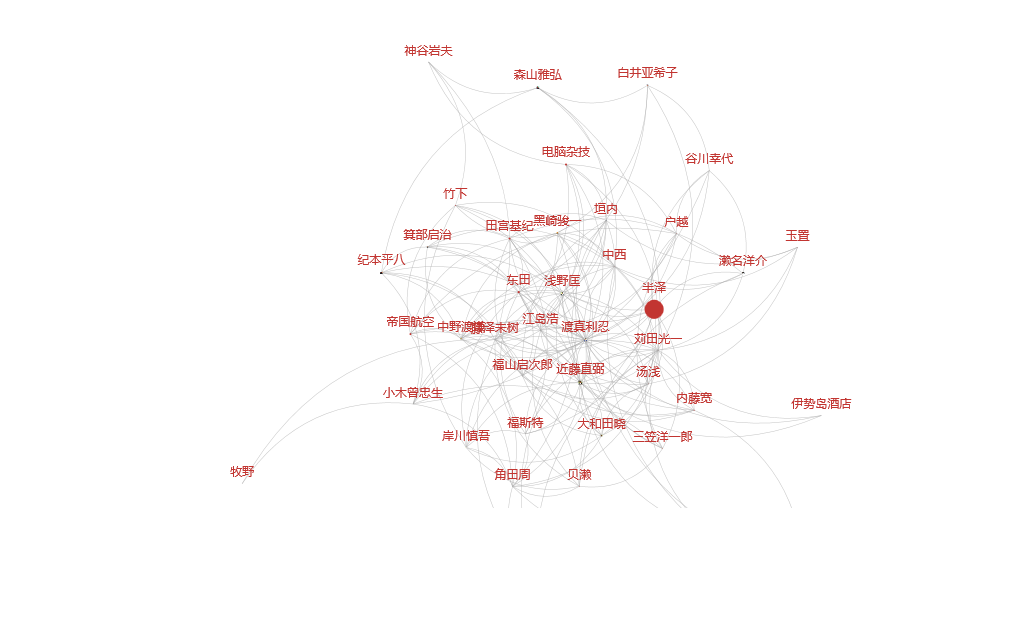
或者,可以直接访问博主托管在 Github Pages 上的 在线版本 。关于 Gephi 软件的使用,请参考: Gephi 网络图极简教程。关于 PyECharts 的使用,请参考: PyECharts。
总结思考
通过生成的人物关系图,可以发现下列规律:
- 大多数人物间的关系是正确的,譬如东田->浅野匡->半泽这条线,对应的是第一季西大阪钢铁 5 亿贷款的事件,而箕部->白井->半泽这条线,显然对应的第二季议员利用“炼金术”敛财的事件。
- 我们发现渡真利拥有仅次于半泽的“连线”数量,这符合他在剧中掌握大量信息来源、职场上八面玲珑的形象设定。相比之下,同样作为半泽好友的近藤和苅田,则没有这样强大的光环。
- 关于大和田,我们都知道他在第二季属于编剧强行“加戏”,一定程度上是在顶替内藤部长的作用,大和田实际上并未参与第二季的剧情,这一点从图中人物节点的联系和大小可以看出。
- 日本人似乎更喜欢使用姓氏,由于妻子要跟随丈夫的姓氏,剧中很多女性角色譬如半泽花、浅野利惠等似乎都不太好提取出来,除非是像白井、谷川、藤泽这些重要的剧情人物。
考虑到,小说中同一个人的称呼通常会有很多种,与之相关联的领域被称为“中文指代消解问题”,使用姓氏作为关键字会造成“女性角色”的缺失,而这种基于“共现”的理论,无法解决 A 在 B 交谈的过程中提到 C 的问题,此时,C 和 A、C 和 B 可能并没有直接的联系,譬如图中的垣内,理论上与西大阪钢铁 5 亿贷款事件并无直接联系,因为剧情中参与融资的主要是新人中西,更不用说老员工角田居然“孤零零”的一个人,而主流的命名实体识别的理论基本都针对三元组,所以,在这里要心疼下角田这位老人。
在目前的人物关系抽取案例中,这种情况称为“无效的人名实体共现句”,所以,更好的做法是,采用文本分类模型,结合依存句法去识别实体间的关系,比如同事关系、朋友关系或者亲属关系等等,它有一个非常专业的名词,称为命名实体识别(NER),而这会让我们的这张图变得更加丰富。在这个方向上,我个人推荐使用哈工大的语言技术平台(LTP)作为进一步改进,因为它可以更好地识别人名。好了,以上就是这篇博客的全部内容啦,欢迎大家在博客下面留言,喜欢我的博客话,请一键三连,点赞收藏,谢谢大家!


