如果说,单体架构系统是坐在家里悠闲地喝着下午茶,那么,毫无疑问,分布式系统将会是一场永远充满惊喜的丛林冒险。从踏上这条旅程的那一刻起,此间种种都被打上分布式的烙印,譬如分布式锁、分布式事务、分布式存储、分布式配置等等,这些词汇拆开来看,“似曾相识燕归来”,每一个我都认识,而一旦放到分布式的场景中,一切就突然变得陌生起来,从过去的经典三层架构、到时下流行的微服务、再到更为前沿的服务网格,一路跌跌撞撞地走过来,大概只有眼花缭乱和目不暇接了。前段时间在做 FakeRpc,这是一个基于 ASP.NET Core 的轻量级 RPC 框架,其间接触了 ZooKeeper、Nacos,后来工作中又接触到了 Kafka、Saga,虽然这些都是不同领域里的分布式解决方案,但是我隐隐觉得它们之间有某种内在的联系,就像所有的分布式系统都存在选举 Leader 的协调算法一样。于是,“喜新厌旧”的双子座,决定新开一个专栏,既然分布式系统是一场永远充满惊喜的丛林冒险,那么,这个专栏就叫做 「分布式丛林冒险系列」好了。一切该从哪里开始呢?我想,还是从 Redis 开始,今天这篇文章,我们来聊一聊 Redis 里的主从复制。
主从复制概述
从某种意义上来讲,主从复制并不是一个新的概念,因为此前博主介绍过数据库里的主从复制,在 利用 MySQL 的 Binlog 实现数据同步与订阅(上):基础篇 这篇文章中,博主和大家分享过利用数据库 Binlog 实现数据同步的方案,而 Binlog 正是实现数据库主从复制的重要机制之一,甚至在更多的时候,我们更喜欢换一种说法,即 读写分离。和数据库类似,Redis 中的主从复制,其实,就是指将一台 Redis 服务器中的数据,复制到其它 Redis 服务器。其中,前者被称为主节点(Master),后者被称为从节点(Slave),通常情况下,每一台 Redis 服务器都是主节点,一个主节点可以有多个从节点,而一个从节点只能有一个主节点,并且数据只能从主节点单向流向从节点,如下图所示:

虽然 Redis 在缓存上的应用做到了家喻户晓的地步,可这并不代表我们能真正得用好 Redis,譬如,博主的上一家公司,基本上没有用到 Redis 的高可用,最多就是一主一从这样的搭配。所以,当时公司里很多人都知道哨兵、集群这些概念,而真正搭过环境的人则是寥寥无几,这正是博主要写这个系列的原因之一。那么,从实用性的角度来看,Redis 的主从复制有哪些实际的作用呢?个人认为,主要有以下几点:
- 数据冗余:主从复制相当于实现了数据的热备份,是除了数据持久化以外的一种数据冗余方案。
- 故障恢复:主从复制相当于一种灾备措施,当主节点主线故障的时候,可以暂时由从节点来提供服务。
- 负载均衡:主从复制搭配读写分离,可以分担主节点的负载压力,在“读多于写”的场景中,可以显著提高并发量。
- 高可用:主从复制是高可用的基础,无论是集群模式还是哨兵模式,都建立在主从复制的基础上。
相信大家都听过 CAP 定理,这是分布式系统中的重要理论之一,其基本思想是,一致性(Consistence)、可用性(Availability) 和 分区容忍性(Partition Tolerance),最多只能同时实现两点,而无法做到三者兼顾,如下图所示:

事实上,对分布式系统的设计而言,本质上就是“鱼和熊掌不可兼得”,关键看你想要做出一个怎么样的选择。例如,同样是注册中心,ZooKeeper、etcd 以及 Consul 都选择了 CP,而 Euraka 则选择了 AP。对于 Redis 而言,单机版的 Redis 可以看作是 CP,因为它牺牲了 A,即可用性。而集群化的 Redis,则可以看作是 AP,通过自动分片和数据冗余,来换取可用性。这其实印证了我们一开始的观点,为什么我们需要 Redis 的主从复制、集群、哨兵这些东西呢?本质上还是为了提高 Redis 的可用性。可能有朋友会问,难道一致性在 Redis 里就不重要了吗?我想,这要从 Redis 主从复制的原理说起。
主从复制原理
首先,我们要明确一点,Redis 里的主从复制是异步的,这样就回到了一个老生常谈的话题,即:实时一致性 和 最终一致性,显然,在 AP 的场景下,最终一致性这种“弱一致性”实现起来要更容易一点,因为实时一致性这种“强一致性”的方案,意味着所有人都要在这个时间点停下来,等实现一致性以后再继续进行下面的工作。我们甚至都不用钻研那些高深莫测的分布式理论,单单从日常生活的角度来切入,你一定会觉得这样子做事情效率低到爆炸,所以,追求实时一致性并不是说不可取,而是感觉这样有一点得不偿失,难道你要为了一致性而牺牲可用性吗?博主曾经接触过一个基于 Ignite 构建的缓存组件,对方声称数据的一致性比可用性更重要。所以,作为一个被很多项目依赖的基础设施,虽然隔三差五地出各种问题,可大家竟然能一直容忍下去,可能这就是爱吧。直到后来引进 Saga 做分布式事务,我意识到这是通过柔性事务来实现最终一致性,而如此前后矛盾的做法,只能成为此刻用来调侃的谈资,其实人更是如此,世间的一切你都可以去追逐,可你终将会失去它,这大概是人生的最终一致性。
好了,言归正传,事实上,Redis 的主从复制可以分为连接建立、数据同步、命令传播三个阶段,下面我们来分别讲解各个部分的相关细节。
连接建立阶段
连接建立阶段,主要目的是主从双方建立 Socket 连接,此时,双方都需要知道对方的 IP 地址和端口号,其基本交互流程如下图所示:

可以注意到,在连接建立阶段,首先,由从节点发出指令slaveof <IP> <Port>,这里的 IP 地址和端口号都是指主节点的 IP 地址和端口号。事实上,该指令还可以有下面两种形式,即:
- 服务器启动参数:在
redis-server命令后附加参数,即redis-server -slaveof <masterip> <masterport> - 服务器配置文件:在
redis.conf文件中配置主节点信息,即slaveof <masterip> <masterport>
接下来,一旦主节点收到了该指令,就会对从节点做出响应,此时,从节点就可以获得主节点的 IP 地址和端口号,在 redis-cli 环境下,我们可以通过 info Replication 来验证这个观点。如图所示,是某个 Redis 从节点中存储的主节点信息:

此时,从节点和主节点会打一场“乒乓球”,从节点会定期发送PING指令,此时,如果主节点返回了PONG指令,则表示连接到主节点的 Socket 可用,你可以将其理解为一种健康检查或者心跳机制,目的是确定主节点还“活”着,否则,作为客户端的从节点就会断开 Socket 连接并尝试重连。如果主节点要求提供密码,那么从节点还需要发送以下指令:auth password,这个时候主节点会对从节点提供的身份信息进行验证,一旦验证通过,从节点就会开始监听主节点的端口,与此同时,主节点会保存从节点的 IP 地址和端口号。同样地,我们可以在主节点中通过 info Replication 来验证这个观点:

至此,主从双方的互相“试探”结束,双方正式建立连接,是为连接建立阶段。
数据同步阶段
如果我们把建立连接看作是两个人“握手”,也许,你的脑海中此刻会浮现出诺基亚的经典开机画面,毫无疑问,下面两个人的“会话”才是真正的重头戏。于是,我们来到了数据同步阶段,这一阶段的主要目的是,完成从节点的数据初始化。在连接建立阶段,从节点是主节点的客户端;而到了这一阶段以及命令传播阶段,双方互为彼此的客户端,因为,此时主节点需要主动向从节点发送命令。按照主从节点的状态不同,可以分为:全量复制 和 部分复制。
如果你接触过 Kafka,应该会有这样一种认知,即 Kafka 里面维护着一个始终追加的日志文件,而每一条消息则是这个日志文件中的一部分,Kafka 利用偏移量来定位某一条消息。在 Redis 的主从复制中,存在着类似的概念,它被称为:复制偏移量,事实上,参与复制的主从节点都会自身的复制偏移量,其中,主节点在处理完写入命令后,会将该命令的对应字节长度累加和记录,该信息可以在主节点的 info Replication 中的 master_repl_offset 字段上找到,我们还是用前面的图做例子来说明:

实际上,在数据同步阶段,主节点内部会维护一个固定长度的、先进先出(FIFO)的队列作为复制积压缓冲区,其默认大小为 1 MB,主节点在响应写命令的时候,不但会把命令发送给从节点,还会写入到复制缓冲区,如下图所示:
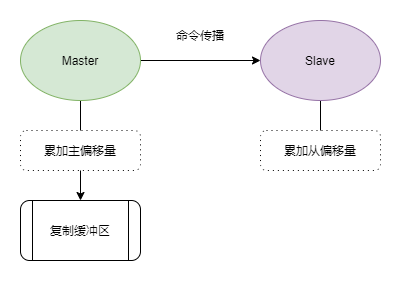
这个复制缓存区的作用是保留主节点最近执行的写命令,因为它是一个先进先出的队列,所以,时间较早或者偏移量较大的命令会在一段时间后被挤出缓冲区,这样,我们就有了更进一步的结论,即:当主从节点 offset 的差距过大超过缓冲区长度时,将无法执行部分复制,只能执行全量复制。所以,选择全量复制还是部分复制,还是要有实际的使用场景来决定。主从配置第一次启用的时候,因为从库没有对应的复制偏移量,所以,第一次复制一定是全量复制,对于全量复制而言,其基本流程如下图所示:

而对于部分复制而言,其得以实施的前提是,复制偏移量之后的数据依然存在于复制缓冲区,那么,如何判断复制偏移量在不在复制缓冲区里呢?在 Redis 中主要是通过 PSYNC 命令来实现,请注意,在 Redis 2.8 之前的版本中,只有 SYNC 命令,而 PSYNC则是 Redis 2.8 版本之后推出的替代命令,它提供了 完整重同步 和 部分重同步 的功能,主要解决了老版本中断线以后重新复制带来的低效率问题。这里,我们以 PSYNC 命令为例来进行说明。事实上,无论主从节点,都会被分配一个唯一的 runid,所以,对于部分复制而言,实际上是从节点告诉主节点,它的 runid 和 offset,然后由主节点来判断这个 offset 是否在它的复制缓冲区里,如下图所示:

因为复制缓冲区中持久化了写入命令,所以此时我们只需要从复制缓冲区中找到对应区间的数据,发给从节点即可,在这种情况下,主节点不需要生成 RDB 快照,所以,部分复制的效率会比全量复制要高很多。以上就是 Redis 数据同步阶段的基本流程,其实在这这个过程中,我们还有很多问题没有说到,譬如 Redis 的两种持久化方案 RDB 和 AOF 应该如何去选择,全量复制过程中主要的性能损耗点,以及 从节点如何利用 RDB 快照更新数据等等,考虑到篇幅,这些话题等以后有机会了再专门来说吧!
命令传播阶段
前面提到过,主节点内部会维护一个复制缓冲区,其主要作用是持久化最近执行的写命令,可是你把命令都放到这个复制缓冲区里了,那些从节点又怎么知道这个具体动作呢?实际上,这一工作是由命令传播程序来完成的,所以,命令传播阶段实际上就是指主节点在写入复制缓冲区以后,通知从节点的这个过程。下面是一个简单的示意图:

我承认,这些偏理论的内容,不单单看起来挺费劲,我写起来更费劲,所以,我只能尽可能地去画这些流程图,这样能更好地帮助大家理解这些内容。其实,有很多的东西,你对它的理解,是一种潜移默化、层层递进的过程,就像这里的复制缓冲区,你压根说不上来,到底是 Kafka 帮助你理解了 Redis,还是 Redis 帮助你理解了 Kafka。有时候,我挺不理解人类变幻莫测的情感,那东西对我来说有时像一门玄学,显然,科学对我而言会更容易一点,那么,我不妨选择去相信科学、相信唯物主义。也许,屏幕前的你,会不置可否地批评我说“光说不练假把式”,好了,下面我们来看一个全量复制的简单实例。
主从复制实战
这里,我们按照“一主两从”的方案来实施 Redis 的主从复制,前面提到过,我们有三种方式来配置主从复制。在这里,博主是使用第三种方式来进行配置的,如下图所示,准备三个文件夹及一个 docker-compose.yaml文件:
MasterSlave
|-- docker-compose.yaml
|-- redis-1
| |-- redis.conf
|-- redis-2
| |-- redis.conf
|-- redis-3
| |-- redis.conf
其中,redis-1为主节点,对应端口号为:7001;redis-2 和 redis-3为从节点,对应端口号分别为:7002 和 7003。首先,主节点的配置项定义如下:
bind 0.0.0.0
protected-mode no
port 7001
timeout 5000
# 900 秒内 1 个更改
save 900 1
# 300 秒内 10 个更改
save 300 10
# 60 秒内 10000 个更改
save 60 10000
rdbcompression yes
dbfilename dump.rdb
dir /data
# 开启 AOF 模式
appendonly yes
# 每秒一次 fsync
appendfsync everysec
requirepass 12345678
接下来,对于redis-2 和 redis-3 这两个从节点而言,主要多了 slaveof 和 masterauth 这两行配置,这是因为我们在主节点中配置了密码:
bind 0.0.0.0
protected-mode no
port 7002
timeout 5000
save 900 1
save 300 10
save 60 10000
rdbcompression yes
dbfilename dump.rdb
dir /data
appendonly yes
appendfsync everysec
requirepass 12345678
slaveof 127.0.0.1 7001
masterauth 12345678
同理,可以对 redis-3 进行配置:
bind 0.0.0.0
protected-mode no
port 7003
timeout 5000
save 900 1
save 300 10
save 60 10000
rdbcompression yes
dbfilename dump.rdb
dir /data
appendonly yes
appendfsync everysec
requirepass 12345678
slaveof 127.0.0.1 7001
masterauth 12345678
以上配置文件,均可以在 Github 获取。接下来,我们会使用 Docker-Compose 进行服务编排:
version: '3.1'
services:
redis1:
image: redis:latest
container_name: redis-master
restart: always
network_mode: "host"
volumes:
- ./redis-1/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server", "/usr/local/etc/redis/redis.conf"]
redis2:
image: redis:latest
container_name: redis-slave-1
restart: always
network_mode: "host"
volumes:
- ./redis-2/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server", "/usr/local/etc/redis/redis.conf"]
redis3:
image: redis:latest
container_name: redis-slave-2
restart: always
network_mode: "host"
volumes:
- ./redis-3/redis.conf:/usr/local/etc/redis/redis.conf
command: ["redis-server", "/usr/local/etc/redis/redis.conf"]
此时,当我们执行docker-compose up命令,如下图所示,它就会自动建立主从关系,这意味着我们在主节点写入的值,均可以通过从节点来进行读取:

为了印证我们的想法,下面我们通过 Redis 的命令行工具redis-cli 来向主节点写入值,为此我们需要进入到容器内部并执行相应的命令。

# 进入主 Redis 容器
docker exec -it 8574d93eeaf4 sh
# 通过 redis-cli 连接 master
redis-cli -p 7001 -c
# 身份认证
127.0.0.1:7001> auth 12345678
# 写入一个 key:name
127.0.0.1:7001> set name yuanpei
同样地,我们进入从节点,从 7002 和 7003 中任选一个即可:
# 进入从 Redis 容器
$ docker exec -it 0b19237b7e58 sh
# 通过 redis-cli 连接从节点
redis-cli -p 7002 -c
# 身份认证
127.0.0.1:7002> auth 12345678
# 读取一个 key:name
127.0.0.1:7002> get name
可以注意到,我们从 7002 中读取出了 7001 中写入的值,这表明我们搭建的 Redis 主从复制起作用了,这样,如果主节点某一天遭遇不幸,这个时候从节点可以临时提供服务,而这恰好印证了我们一开始的观点,为什么需要主从复制呢?我们肉眼可见的效果就是数据冗余和故障恢复,而负载均衡和高可用更多的是一种战略上的考量,它完全取决于你所处的高度。截至到此刻,Redis 的主从复制,你学会了吗?

本文小结
本文是 #分布式丛林探险系列# 的第一篇文章,主要分享了 Redis 主从复制模式的相关内容。首先,主从复制可以为 Redis 带来数据冗余、故障恢复、负载均衡以及高可用等方面的收益,单机版的 Redis 是一个符合 CP 的系统,而集群化的 Redis 则是一个符合 AP 的系统,其一致性正是由这篇文章中描述的复制来保证。根据主从节点状态的不同,Redis 中的主从复制,可以分为 全量复制 和 部分复制 两种,全量复制是主节点生成一个快照然后发送给从节点,而部分复制则是从复制缓冲区中筛选出命令然后发给从节点,在此基础上,我们用 Docker-Compose 构建了一个“一主两从”的主从复制方案。这个世界上没有 100% 完美的方案,Redis 的主从复制在实际使用中可能会遇到,诸如延迟与不一致、数据过期、故障切换等等的问题,特别是故障切换,虽然从节点可以在主节点挂了的时候临时顶上去,但这依赖于研发人员去切换项目中使用的连接字符串,如果希望更好的实现主从切换,可能还是需要大家去做进一步的工作,常言道,“实践出真知”,这篇文章充其量只能作为一个引子,更深入的话题、玩法,需要大家在实践中不断总结。好了,以上就是这篇文章的全部内容啦,如果大家对文章中的内容和观点有什么意见或者建议,欢迎大家在评论区留言,谢谢大家!


