在上一篇 博客 中,我们一起探索和实现了gRPC的健康检查。从服务治理的角度来看,健康检查保证的是被调用的服务“健康”或者“可用”。可即使如此,我们依然会遇到,因为网络不稳定等原因而造成的服务调用失败的情形,就如同我们赖以生存的这个真实世界,本身就充满了各种不确定的因素一样,“世间唯一不变的只有变化本身”。不管是面对不稳定的服务,还是面对不确定的人生,任何时候我们都需要有一个 B 计划,甚至我们人生中的一切努力,本质上都是为了多一份自由,一份选择的自由。在微服务的世界里,我们将这种选择称之为“降级(Fallback)”,如果大家有接触过 Hystrix 或者 Polly 这类框架,就会明白我这里的所说的“降级”具体是什么。在众多的“降级”策略中,重试是一种非常朴素的策略,尤其是当你调用一个不稳定的服务的时候。

引言
在此之前,博主曾经介绍过 HttpClient 的重试。所以,今天这篇博客我们来聊聊gRPC的客户端重试,因为要构建一个高可用的微服务架构,除了需要高可用的服务提供者,同样还需要高可用的服务消费者。下面,博主将由浅入深地为大家分享 4 种重试方案的实现,除了 官方 内置的方案,基本上都需要搭配 Polly 来使用,所以,到这里你可以理解这篇博客的标题,为什么博主会 毁人不倦 地尝试不同的重试方案,因为每一种方案都有它自身的局限性,博主想要的是一种更优雅的方案。具体来讲,主要有:基于 gRPC RetryPolicy、基于 HttpClientFactory、基于 gRPC 拦截器 以及 基于 CallInvoker 4 种方案。如果大家还有更好的思路,欢迎大家在博客评论区积极留言、参与讨论。
基于 gRPC RetryPolicy
所谓的 gRPC RetryPolicy,其实是指 官方 提供的暂时性故障处理方案,它允许我们在创建GrpcChannel的时候,去指定一个重试策略:
var defaultMethodConfig = new MethodConfig {
Names = { MethodName.Default },
RetryPolicy = new RetryPolicy {
MaxAttempts = 5,
InitialBackoff = TimeSpan.FromSeconds(1),
MaxBackoff = TimeSpan.FromSeconds(5),
BackoffMultiplier = 1.5,
RetryableStatusCodes = { StatusCode.Unavailable }
}
};
var channel = GrpcChannel.ForAddress("https://localhost:5001", new GrpcChannelOptions {
ServiceConfig = new ServiceConfig { MethodConfigs = { defaultMethodConfig } }
});
在上面的代码中,MethodConfig可以为指定的方法配置一个重试策略,当传入的方法名为MethodName.Default时,它将应用于该通道下的所有 gRPC 方法。如你所见,在重试策略中我们可以指定重试次数、重试间隔等参数。这个方案本身没有太多心智上的负担,唯一的缺点是,它没有预留出可扩展的接口,以至于我们想要验证它到底有没有重试的时候,居然要通过Fiddler抓包这种方式,换句话讲,我们没有办法自定义整个重试行为,譬如你想在重试过程中记录日志,这种方案就会鸡肋起来,对使用者来说,这完全就是一个黑盒子。
除此之外,官方还提供了一种成为 Hedging 重试策略作为备选方案。类似地,它通过 HedgingPolicy 属性来指定重试策略。对比 RetryPolicy,它可以同时发送单个 gRPC 请求的多个副本,并使用第一个成功的结果作为返回值,所以,一个显而易见的约束是,它要求这个 gRPC 方法是无副作用的、幂等的函数。其实,这是所有重试方案都应该考虑的一个问题,而不单单是 HedgingPolicy。由于这两种策略有着本质上的不同,请记住:RetryPolicy 不能与 HedgingPolicy 一起使用。
var defaultMethodConfig = new MethodConfig {
Names = { MethodName.Default },
HedgingPolicy = new HedgingPolicy {
MaxAttempts = 5,
NonFatalStatusCodes = { StatusCode.Unavailable }
}
};
var channel = GrpcChannel.ForAddress("https://localhost:5001", new GrpcChannelOptions {
ServiceConfig = new ServiceConfig { MethodConfigs = { defaultMethodConfig } }
});
世间的一切都是双刃剑, HedgingPolicy 同样打不破这铁笼一般的人间真实,虽然它可以一次发送多个gRPC请求,可毫无疑问的是,这是一种相当浪费的策略,因为不管有多少个请求,它始终都取第一个结果作为返回值,而剩余的结果都将会被直接抛弃。想想每一年的高考状元,大家是不是都只记住了第一名。也许,人生正是如此呢,程序世界固然是由 0 和 1 构成的虚幻世界,可何尝就不是真实世界的某种投影呢?这里请允许博主安利一部动漫《你好世界》,它用视觉化的方式表达了真实世界与程序世界的某种特殊联系。
基于 HttpClientFactory
接下来,我们要介绍的是基于 HttpClentFactory 的重试方案。也许,大家会感到困惑,明明这篇博客说的是 gRPC ,为什么 HttpClientFactory 会出现在这里呢?其实,很多时候,我们看到的只有表面,而出奇制胜的招式往往出自你对于本质的理解。如果大家阅读过 gRPC 客户端部分的源代码,就会意识到这样一件事情,即,gRPC 底层依然用到了 HttpClient 这套所谓“管道式”的体系,你可以理解为,最终传输层还是要交给 HttpClient 来处理,而 HttpClientFactory 本来就支持结合 Polly 进行重试,所以,我们其实是针对同一个问题的不同阶段进行了切入处理。一旦想清楚这一点,下面的代码理解起来就没有难度啦:
var services = new ServiceCollection();
services.AddGrpcClient<Greeter.GreeterClient>(opt => {
opt.Address = new Uri("https://localhost:8001");
})
.ConfigurePrimaryHttpMessageHandler(() => new HttpClientHandler {
ClientCertificateOptions = ClientCertificateOption.Manual,
ServerCertificateCustomValidationCallback = (httpRequestMessage, cert, cetChain, policyErrors) => true
})
.AddPolicyHandler(
HttpPolicyExtensions.HandleTransientHttpError()
.OrResult(res => res.StatusCode != System.Net.HttpStatusCode.OK)
.WaitAndRetryAsync(
6,
retryAttempt => TimeSpan.FromSeconds(Math.Pow(2, retryAttempt)) + TimeSpan.FromMilliseconds(new Random().Next(0, 100)),
(result, timeSpan, current, context)=> {
Console.WriteLine($"StatusCode={result.Result?.StatusCode}");
Console.WriteLine($"Exception={result.Exception?.Message}");
Console.WriteLine($"正在进行第{current}次重试,间隔{timeSpan.TotalMilliseconds}秒");
}
)
);
var serviceProvider = services.BuildServiceProvider();
await serviceProvider.GetService<Greeter.GreeterClient>().SayHelloAsync(new HelloRequest() { Name = "长安书小妆" });
在这里,为了模拟网络不畅的这种场景,我们故意指定了一个错误的终结点信息。此时,我们会得到下面的结果:

不过话又说回来,因为我们选择切入的阶段是“传输层”,所以,相对于整个 RpcException 而言,我们其实是找到了一个问题的子集,这意味着这个方案并不能覆盖到所有的场景,如果是在非“传输层”引发了某种异常,我们就没有办法通过这种方式去做重试处理。所以,我在一开始就说过,没有 100% 完美的解决方案,每一种方案都有它自身的局限性,这句话在这里得到了第一次印证。如果大家再回过头去看第一种方案,是不是就会发现,它里面还是使用了HTTP状态码作为是否重试的判断依据。所以,大家觉得呢?欢迎大家在评论区留下你的想法。
基于 gRPC 拦截器
关于 gRPC 的拦截器,博主专门写过一篇 博客 来介绍它,所以,在一开始考虑重试方案的时候,拦截器其实是最容易想到的一种方案,主要思路是利用 Polly 中Policy的Execute()方法,对拦截器中获取gRPC调用结果的过程进行包装,我们一起来看下面的例子:
public override AsyncUnaryCall<TResponse> AsyncUnaryCall<TRequest, TResponse>(
TRequest request,
ClientInterceptorContext<TRequest, TResponse> context,
AsyncUnaryCallContinuation<TRequest, TResponse> continuation
)
{
var retryPolicy =
Policy<AsyncUnaryCall<TResponse>>
.Handle<RpcException>(s => s.StatusCode == StatusCode.Internal)
.Or<WebException>()
.OrResult(r =>
{
var awaiter = r.GetAwaiter();
if (awaiter.IsCompleted)
return r.GetStatus().StatusCode == StatusCode.OK;
try {
r.ResponseAsync.Wait();
} catch (AggregateException) {
return true;
}
return false;
})
.WaitAndRetryAsync(3, x => TimeSpan.FromSeconds(5), (result, timeSpan, current, context) =>
{
Console.WriteLine($"正在进行第{current}次重试...");
});
return retryPolicy.ExecuteAsync(() => Task.FromResult(continuation(request, context))).Result;
}
}
基于 gRPC 拦截器的这种方案,它最大的问题在于异常的颗粒度太大,这句话是什么意思呢?简单来讲就是在拦截器这个层面上,你能捕捉到的只有RpcException,这样就使得我们难以捕获更小粒度的异常,譬如网络异常、超时异常等等。其次,gPRC 拦截器中大量使用了,类似AsyncUnaryCall<TResponse>这样的异步的返回值类型,这让我们在编写 Policy 的时候,多多少少会有一点不自在。综上所述,这个最容易想到的方案,本身是没有太大的问题的,最关键的问题是我们能接受什么样的异常颗粒度。而像异步返回值这种问题,只要写过一次以后,博主以为,它并不会成为我们继续探索的阻碍,这一点大家可以自己去体会。
在尝试基于拦截器的重试方案的过程中,博主发现,指定一个错误的终结点信息,gRPC会在进入拦截器前就引发异常。这意味着这种基于拦截器的重试方案,在面对“传输层”的异常时略显乏力,所以,从某种程度上来讲,这个方案同样是一个不完美的方案。可这世上人来人往、本无完人,我们实在没有必要耽于技术方案的绝对完美而不可自拔,当求真、莫求执,所谓“大成若缺”,可以欣赏得来缺憾之美,同样是一种幸福。
基于 CallInvoker
如果说,前面的 3 种方案都属于“见招拆招”的外家功夫。那么,接下来我要分享的思路,绝对可以称得上是“打通任督二脉”的玄门内功。
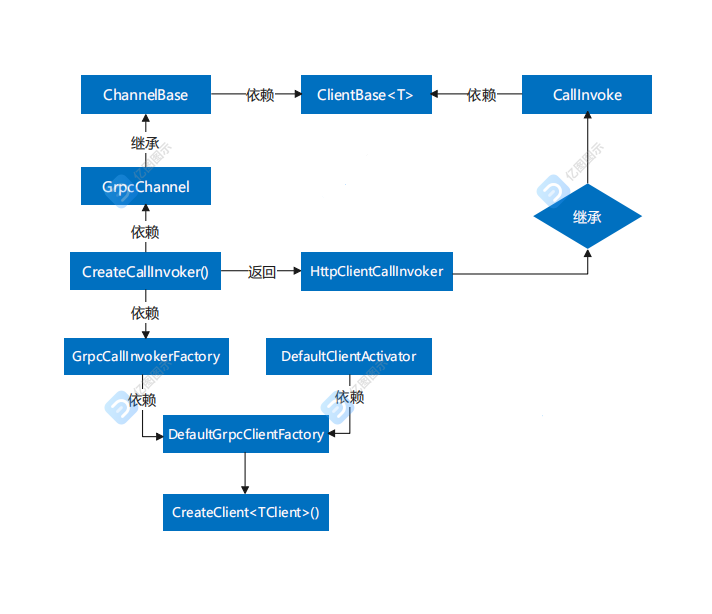
首先,博主想用一张图来讲解 gRPC 客户端的工作原理。从这张图中,我们可以看出,初始化一个gRPC的客户端,主要有GrpcChannel和CallInvoker两种构造形式,而GrpcChannel中的CreateCallInvoker()方法会返回HttpClientCallInvoker的一个实例。此时,我们就会发现,HttpClientCallInvoker是CallInvoker的一个子类。所以,我们基本可以判定CallInvoker是一个扮演着重要角色的类。继续探索,我们就会发现,GrpcCallInvokerFactory内部通过构造GrpcChannel,进而实现了CreateCallInvoker()方法,换句话说,本质上依然是调用了GrpcChannel中的CreateCallInvoker()方法。最终,这个CallInvoker实例会作为参数,传递给DefaultClientActivator的CreateClient()方法,至此我们就完成了整个gRPC客户端的创建工作。
好了,相信现在大家都有一个疑问,这个CallInvoke到底是个什么东西呢?为什么它在整个gRPC的底层中是如此的重要呢?其实,它就是一个平平无奇的抽象类啦,可是一旦配合着gRPC中的Calls类来使用,这个CallInvoker简直就是扩展gRPC的一个重要的桥梁,因为我们不用关心底层是如何处理gRPC请求/响应的,而这丝毫不影响我们对这个过程进行自定义重写。因此,按照这样的思路,我们有了下面的实现:
class GrpcCallInvoker : CallInvoker
{
private readonly Channel _channel;
private readonly GrpcPollyPolicyOptions _pollyOptions;
public GrpcCallInvoker(
Channel channel,
GrpcPollyPolicyOptions pollyOptions
)
{
_channel = channel;
_pollyOptions = pollyOptions;
}
public override AsyncClientStreamingCall<TRequest, TResponse> AsyncClientStreamingCall<TRequest, TResponse>(
Method<TRequest, TResponse> method,
string host,
CallOptions options
)
{
var policy = CreatePollyPolicy<AsyncClientStreamingCall<TRequest, TResponse>>();
return policy.Execute(() => Calls.AsyncClientStreamingCall(CreateCall(method, host, options)));
}
public override AsyncDuplexStreamingCall<TRequest, TResponse> AsyncDuplexStreamingCall<TRequest, TResponse>(
Method<TRequest, TResponse> method,
string host,
CallOptions options
)
{
var policy = CreatePollyPolicy<AsyncDuplexStreamingCall<TRequest, TResponse>>();
return policy.Execute(() => Calls.AsyncDuplexStreamingCall(CreateCall(method, host, options)));
}
public override AsyncServerStreamingCall<TResponse> AsyncServerStreamingCall<TRequest, TResponse>(
Method<TRequest, TResponse> method,
string host, CallOptions options,
TRequest request
)
{
var policy = CreatePollyPolicy<AsyncServerStreamingCall<TResponse>>();
return policy.Execute(() => Calls.AsyncServerStreamingCall(CreateCall(method, host, options), request));
}
public override AsyncUnaryCall<TResponse> AsyncUnaryCall<TRequest, TResponse>(
Method<TRequest, TResponse> method,
string host,
CallOptions options,
TRequest request
)
{
var policy = CreatePollyPolicy<AsyncUnaryCall<TResponse>>();
return policy.Execute(() => Calls.AsyncUnaryCall(CreateCall(method, host, options), request));
}
public override TResponse BlockingUnaryCall<TRequest, TResponse>(
Method<TRequest, TResponse> method,
string host,
CallOptions options,
TRequest request
)
{
var policy = CreatePollyPolicy<TResponse>();
return policy.Execute(() => Calls.BlockingUnaryCall(CreateCall(method, host, options), request));
}
}
我想,经过连续三篇文章的洗礼,大家对这些方法应该都不陌生了吧!下面我们来着重讲解下CreateCall()和CreatePollyPolicy()这两个方法。其中,CreateCall()这个方法会相对简单一点,因为它完全就是返回gRPC的内置类型CallInvocationDetails。
protected CallInvocationDetails<TRequest, TResponse> CreateCall<TRequest, TResponse>(
Method<TRequest, TResponse> method,
string host,
CallOptions options
)
where TRequest : class
where TResponse : class
{
return new CallInvocationDetails<TRequest, TResponse>(_channel, method, options);
}
接下来,CreatePollyPolicy()这个方法就非常的明确啦,通过注入的GrpcPollyPolicyOptions来构造一个Policy。考虑到我们要做的是一个通用的方案,这里预留了断路器、重试、超时三种不同策略的参数。如果希望对构建 Policy 的过程进行自定义,则可以通过重写该方法来实现:
public virtual Policy<TResult> CreatePollyPolicy<TResult>()
{
Policy<TResult> policy = null; ;
// 构造断路器策略
if (_pollyOptions.CircuitBreakerCount > 0)
{
var policyBreaker = Policy<TResult>
.Handle<Exception>()
.CircuitBreaker(_pollyOptions.CircuitBreakerCount, _pollyOptions.CircuitBreakerTime);
policy = policy == null ? policyBreaker :
policy.Wrap(policyBreaker) as Policy<TResult>;
// 断路器降级
var policyFallBack = Policy<TResult>
.Handle<Polly.CircuitBreaker.BrokenCircuitException>()
.Fallback(() =>
{
return default(TResult);
});
policy = policyFallBack.Wrap(policy);
}
// 构造超时策略
if (_pollyOptions.Timeout > TimeSpan.Zero)
{
var policyTimeout = Policy.Timeout(() => _pollyOptions.Timeout, Polly.Timeout.TimeoutStrategy.Pessimistic);
policy = policy == null ? (Policy<TResult>)policyTimeout.AsPolicy<TResult>() :
policy.Wrap(policyTimeout);
// 超时降级
var policyFallBack = Policy<TResult>
.Handle<Polly.Timeout.TimeoutRejectedException>()
.Fallback(() =>
{
return default(TResult);
});
policy = policyFallBack.Wrap(policy);
}
// 构造重试策略
if (_pollyOptions.RetryCount > 0)
{
var retryPolicy = Policy<TResult>.Handle<Exception>().WaitAndRetry(
_pollyOptions.RetryCount,
x => _pollyOptions.RetryInterval,
(result, timeSpan, current, context) =>
{
Console.WriteLine($"正在进行第{current}次重试,间隔{timeSpan.TotalSeconds}秒");
});
policy = policy == null ? retryPolicy :
policy.Wrap(retryPolicy) as Policy<TResult>;
}
return policy;
}
因为我们无法修改DefaultGrpcClientFactory中关于CallInvoker这部分的逻辑,所以,我们采取了下面的“迂回战术”:
services.AddGrpc();
services.AddTransient<GrpcCallInvoker>();
services.AddTransient<Channel>(sp => new Channel("localhost", 5001, ChannelCredentials.Insecure));
services.AddTransient<GrpcPollyPolicyOptions>(sp => {
return new GrpcPollyPolicyOptions()
{
RetryCount = 10,
RetryInterval = TimeSpan.FromSeconds(1),
CircuitBreakerCount = 5,
CircuitBreakerTime = TimeSpan.FromSeconds(6),
Timeout = TimeSpan.FromSeconds(10)
};
});
var callInvoker = services.BuildServiceProvider().GetService<GrpcCallInvoker>();
var client = (Greeter.GreeterClient)Activator.CreateInstance(typeof(Greeter.GreeterClient), callInvoker);
client.SayHello(new HelloRequest() { Name = "长安书小妆" });
此时,如果我们故意写一个错误的终结点地址,我们将会得到下面的结果:

因为重试 5 次后就会启动断路器,所以,这个接口在重试 5 次后就立即停止了调用,这证明我们设想的这个方案是可以完美工作的!
本文小结
写完以后,突然发现这一篇的信息量有点爆炸,尤其是CallInvoker这一部分,需要花点时间去阅读 gRPC 的源代码。可对于博主而言,其实更加享受的是,探索 gRPC 重试方案的这个过程。起初,因为对拦截器更熟悉一点,所以,我最先想到的是基于拦截器的重试方案。经过博主一番验证以后,发现这是一个有缺陷的方案。这时候,我意外发现,官方提供了重试策略,可这个重试策略对于使用者来说是一个黑盒子。再后来,发现可以在 HttpClient 上做一点文章,虽然它针对的是“传输层”这个阶段。直到从网上查资料,意识到可以重写CallInvoker这个抽象类,这个时候终于找到了最完美的方案。所以,通过这个过程,大家可以发现,我这篇博客的写作过程,其实与我思考过程有着明显的不同。思考的过程中带入“先入为主”的意识,这让我的思考过程走了不少的弯路,而写作过程则是一个由浅入深、由表及里的顺序。也许,下一次遇到类似的问题,我会先了解一下官方有没有提供标准方案,这是我在写完这篇博客以后最大的一个感悟。好了,这篇博客就先写到这里啦,如果大家对文中的内容由意见或者建议,欢迎大家在评论区给我留言,谢谢大家!


