各位朋友,大家好,我是 Payne,欢迎大家关注我的博客。最近读一本并行计算相关的书籍,在这本书中作者提到了 MapReduce。相信熟悉大数据领域的朋友,一定都知道 MapReduce 是 Hadoop 框架中重要的组成部分。在这篇文章中,博主将以函数式编程作为切入点,来和大家聊一聊大数据中的 MapReduce。如今人工智能正成为行业内竞相追逐的热点,选择 MapReduce 这个主题,更多的是希望带领大家一窥人工智能的门庭,更多深入的话题需要大家来探索和挖掘。
MapReduce 的前世今生
MapReduce 最早是由 Google 公司研究并提出的一种面向大规模数据处理的并行计算模型和方法。2003 年和 2004 年,Google 公司先后在国际会议上发表了关于 Google 分布式文件系统(GFS)和 MapReduce 的论文。这两篇论文公布了 Google 的 GFS 和 MapReduce 的基本原理和主要设计思想,我们通常所说的 Google 的三驾马车,实际上就是在说 GFS、BigTable 和 MapReduce。因此,这些论文的问世直接催生了 Hadoop 的诞生,可以说今天主流的大数据框架如 Hadoop、Spark 等,无一不是受到 Google 这些论文的影响,而这正是 MapReduce 由来,其得名则是因为函数式编程中的两个内置函数: map()和 reduce()。
我们常常说,脱离了业务场景去讨论一项技术是无意义的,这个原则在 MapReduce 上同样适用。众所周知,Google 是一家搜索引擎公司,其设计 MapReduce 的初衷,主要是为了解决搜索引擎中大规模网页数据的并行化处理。所以,我们可以说,MapReduce 其实是起源自 Web 检索的。而我们知道,Web 检索可以分为两部分,即获取网页内容并建立索引、根据网页索引来处理查询关键字。我们可以认为互联网上的每个网页都是一个文档,而每个文档中都会有不同的关键字,Google 会针对每一个关键字建立映射关系,即哪些文档中含有当前关键字,这是建立索引的过程。在建立索引以后,查询就会变得简单,因为现在我们可以按图索骥。
互联网诞生至今,网站及网页的数量越来越庞大,像 Google 这样的搜索引擎巨头是如何保证能够对 Web 上的内容进行检索的呢?答案是采用并行计算(Parallel)。硬件技术的不断革新,让计算机可以发挥多核的优势来处理数据,可当数据量庞大到单机无法处理的程度,就迫使我们不得不采用多台计算机进行并行计算。我们知道并行计算的思想是,将大数据分割成较小的数据块,交由不同的任务单元来处理,然后再将这些结果聚合起来。因此,可以将 MapReduce 理解为一种可以处理海量数据、运行在大规模集群上、具备高度容错能力、以并行处理方式执行的软件框架。MapReduce 是分治思想在大规模机器集群时代的集中体现(如图所示),其中,Mapper 负责任务的划分,Reducer 负责结果的汇总。
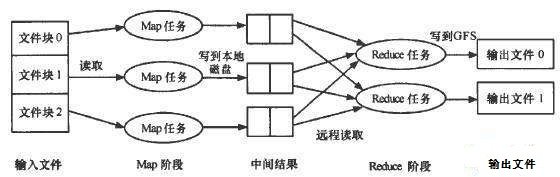
MapReduce 的推出给大数据并行处理带来了巨大的革命性影响,使其成为事实上的大数据处理的工业标准,是目前为止最为成功、最广为接受和最易于使用的大数据并行处理技术。广为人知的大数据框架 Hadoop,正是受到 MapReduce 的启发。自问世来,成为 Apache 基金会下最重要的项目,受到全球学术界和工业界的普遍关注,并得到推广和普及应用。MapReduce 的非凡意义在于,它提出了一个基于集群的高性能并行计算模型,允许使用市场上普通的商用服务器构成一个含有数十、数百甚至数千个节点的分布式并行计算集群,可以在集群节点上自动分配和执行任务以及收集计算结果,通过 Mapper 和 Reducer 提供了抽象的大数据处理并行编程接口,可以帮助开发人员更便捷地完成大规模数据处理的编程和计算工作。今天,Google 有超过 10000 个不同的项目已采用 MapReduce 来实现。
函数式编程与 MapReduce
我们提到,MapReduce 之得名,其灵感来自函数式编程中的两个内置函数:map()和 reduce()。函数式编程中,有一个重要的概念叫做高阶函数,是指函数自身能够接受函数,并返回函数的一种函数。我们所熟悉的 C#和 Java 都是典型的面向对象编程(OOP)的语言,在这类编程语言中类(Class)是第一等公民,即不允许有独立于类的结构出现在代码中。虽然微软从未公开表示 C#支持函数式编程,可从 LINQ 中我们依然可以窥见高阶函数的身影,譬如我们熟悉的 Select()、Where()等扩展方法,就可以让我们按照函数式编程的风格去编写代码,这正是为什么 Java 8 开始支持 Stream API 的原因。最经典的函数式编程语言当属 Haskell 语言,我们今天见到的各种编程语言,在考虑引入函数式编程风格的时候,或多或少地都会受到这门语言影响。当你开始适应函数作为第一等公民、高阶函数、柯里化以及惰性求值以后,你或许就会感受到函数式编程特有的美感。
这里我们选择 Python 来阐述函数式编程与 MapReduce 的关系。Python 可以让我们轻易地在多种不同的编程风格间切换,事实上现在的编程语言都有向着混合式编程风格发展的趋势。我们提到 MapReduce 来自两个内置函数:map()和 reduce()。其中,map()方法可以对指定集合中的元素按照指定函数进行映射,并将映射后的结果以集合形式返回。譬如我们有一个集合**[1,3,5,7,9]**,我们希望对集合中的每一个元素做平方运算。借助 Python 中的 map()方法和 lambda 表达式,这个问题可以通过 1 行代码得到解决。同理,如果我们希望对该集合内的元素做求和运算,我们可以借助于 Python 中的 reduce()方法,该方法位于 functools 模块中。在某些编程语言中该方法又被成为 fold()方法,实际上这两种叫法是等价的,我们关注函数式编程的本质即可。什么是本质呢?当然是函数啦。
list = map(lambda x: x * x, [1,3,5,7,9]) #[1,9,25,49,81]
sum = functools.reduce(lambda x,y: x+y, [1,3,5,7,9]) #25
好了,现在我们来分析下这两个函数,这将帮助我们更好地理解 MapReduce。map()方法在这里被称为映射函数,它可以将一种类型映射为一种新的类型。举一个生活中的例子,譬如我们做菜的时候,必不可少的一个环节是将各种各样的食材切碎, 此时作用在这些食材的这个操作就是一个 Map 操作,你给 Map 一个洋葱就可以得到洋葱丝。同样地 ,你给 Map 一个番茄就可以得到番茄块。所以 Map 处理的原始数据,每条数据间没有相互联系,聪明的你告诉我洋葱和番茄有什么关系。相比 map()方法,reduce()方法复杂的地方在于,它要求 lambda 表达式中必须是两个参数。如果继续沿用做菜这个生活化的例子,reduce()方法是将 Map 操作中切好的食材混合在一起。假设我们要做一份辣椒酱,辣椒酱需要的材料有辣椒、姜和蒜,因此在第一步 Map 的时候,这些食材将具有相同的 Key。对同一类数据,我们就可以使用 reduce()进行左/右折叠操作,这相当于我们将同一道菜的食材一起放到锅里,所以 Reduce 阶段处理的数据是以 Key-Value 形式组织的,同一个 Key 下的 Value 具有相关性。这样,从理论上它就完全符合函数式编程里的 map()和 reduce()啦。
C#并行编程里的 PLINQ
关于 MapReduce 中一个经典案例是,统计不同文章中出现的关键字的频率。对这样一个问题,我们基本上可以想到下面四种方法:
- 写一个单线程程序,顺序地遍历所有文章,然后统计每个关键字出现的频率。
- 写一个多线程程序,并发地遍历所有文章,然后统计每个关键字出现的频率。
- 写一个单线程程序,部署到 N 台不同的计算机上,然后将文章分割成 N 份分别输入,再由人工汇总 N 份结果。
- 使用 MapReduce,程序部署、任务划分、结果汇总全部交给框架去完成,我们定义好任务即可。 通过对比,我们可以非常容易地分析出来,第一种方法最简单同时最耗时;第二种方法理论上比第一种高效,尤其是当计算机是多核或者多处理器的时候,缺点是要解决线程同步的问题;第三种方法初现集群的思想,可无法解决程序部署、任务划分和结果汇总等一系列问题;第四种方法本质上就是第三种方法, 可是 MapReduce 解决了第三种方法全部缺陷,所以它或许是目前最完美的方法。我们下面来考虑,如何模拟这个过程,因为博主不可能为了写一篇科普性质的文章,专门去准备一个 Hadoop 的开发环境啊,哈哈。
PLINQ,即 Parallel LINQ,是.NET 4.0 中增加的任务并行库(TPL)中的一部分。并行编程中有两个基本的概念,任务并行和数据并行。前者是指,将程序分割成一组任务并使用不同的线程来运行不同的任务,这种方式被称为任务并行;而后者是指,将数据分割成较小的数据块,对这些数据进行并行计算,然后聚合这些计算结果,这种编程模型称为数据并行。伴随着并行算法的出现,并行集合相继而来,显然 LINQ 的并行版本就是 PLINQ。这里我们来看一个使用 PLINQ 实现的词频统计代码,这将作为我们实现 MapReduce 的一个示例:
//Origin Texts
string strTarget = @"";
//Map
string[] words = strTarget.Split(' ');
ILookup<string, int> map = words.AsParallel().ToLookup(p => p, k => 1);
//Reduce
var reduce = from IGrouping<string, int> wordMap in map.AsParallel()
where wordMap.Count() > 1
select new { Word = wordMap.Key, Count = wordMap.Count() };
//Show Results
foreach (var word in reduce)
Console.WriteLine("Word: '{0}' : Count: {1}", word.Word, word.Count);
本文小结
今天 Google 发布了全新的 AI 服务工具 Cloud AutoML,从这个产品的名字就可以看出,这是一个试图将人工智能大众化的产品。目前 AI 是行业中不容置疑热点,国外的科技巨头如 Google、微软,国内的科技巨头如腾讯、阿里和百度等,无一不在积极布局 AI 的上下游产业链。最近 CSDN 发布了人工智能方向的发展规划,整个产品线的基本都在做战略上调整,我们这些曾经的老用户被新的社区 运营搞得非常郁闷,因为所有的资源都在向着人工智能和区块链倾斜。上周在知乎上看到一篇讽刺国内区块链发展乱象的文章,大概就是说国人喜欢拿一个 Token 当做加密货币来买,实则连底层技术、分布账本、钱包等基础设施都没有。对于这一点我深有体会,任何新的商业模式在中国都火不过 1 年,譬如在 2017 年里被发扬广大的共享经济,有多少共享单车是靠技术和产品赢得市场的,我相信大部分都是沾了人口基数大的光。目前的人工智能,核心算法及技术都掌握在科技巨头手上。我们所追逐的人工智能,有多少是需要靠不断调整参数反复去训练来达到的呢?我觉得找到切实可靠的需求落脚点,比追逐一个又一个热点要更现实,我们大部分工程师都是在科学家工作的基础上做集成应用,所以拨开泡沫看清方向比盲目跟风更重要呀。
这篇文章蹭了人工智能的热点,其实它对 MapReduce 并没有做多少深入的研究。我们从 Google 的业务场景着手分析,思考为什么 Google 需要 MapReduce,即提出 MapReduce 是为了解决一个什么样的问题?答案是为了适应 Google 在大规模 Web 检索业务方面的需要。通过梳理 Web 检索的一般流程,我们意识到,Web 检索可以分为两部分,即获取网页内容并建立索引、根据网页索引来处理查询关键字,从而引出了 Mapper 和 Reducer 两个基本的数据处理单元,MapReduce 是分治思想在大规模机器集群时代的集中体现,其中,Mapper 负责任务的划分,Reducer 负责结果的汇总。接下来,我们顺着函数式编程的思路,分析了函数式编程中的 map()和 reduce(),这两个核心的函数同 MapReduce 在思想上的一致性,这正是为了印证前文中 MapReduce 得名的由来。考虑到 C#中提供了 PLINQ,而在阅读《C#多线程编程》这本书时,同样提到了 MapReduce 这种并行计算模型,所以在这里将这两者进行结合,提供了一个通过并行计算统计单词频率的简单示例。以上就是这篇文章的所有内容了,如果大家对文章有什么意见或者建议,可以在文章评论区留言,这篇文章就是这样了,谢谢大家,晚安!


