各位朋友,大家好,我是 Payne,欢迎大家关注我的博客。我的博客地址是:https://qinyuanpei.github.io。对于今天这篇文章的主题,相信经常关注我博客的朋友一定不会陌生。因为在 2017 年年底的时候,我曾以此为题写作了一篇文章:基于新浪微博的男女择偶观数据分析(上)。这篇文章记录了我当时脑海中闪烁着的细微想法,即当你发现一件事物背后是由哲学或者心理学这类玄奥的科学在驱动的时候,不妨考虑使用数学的思维来让一切因素数量化,我想这是最初数据分析让我感兴趣的一个原因。因为当时对文本的处理了解得非常粗浅,所以在第一次写作这篇文章的时候,实际的工作不过是在分词后绘制词云而已。等到我完成对微信好友信息的数据分析以后,我意识到微博这里其实可以继续发掘。关于微信好友信息的数据分析,可以参考这篇文章:基于 Python 实现的微信好友数据分析。在这样的想法促使下,便有了今天这篇文章,因为工作关系一直没有时间及时整理出来,希望这篇文章可以带给大家一点启示,尤其是在短文本分类方面,这样我就会非常开心啦!:slightly_smiling_face:
故事背景
关于故事背景,我在 基于新浪微博的男女择偶观数据分析(上) 这篇文章中说得非常清楚啦。起因就是我想知道,男性和女性在选择伴侣的时候,到底更为关注哪些因素?在对微信好友信息进行数据分析的时候,我们可以非常直接地确定,譬如性别、签名、头像、位置这四个不同的维度,这是因为我们处理的是结构化的数据。什么是结构化的数据呢?一个非常直观的认识是,这些数据可以按照二维表的方式组织起来。可对于微博这样一个无结构的文本数据类型,我们除了对词频、词性等因素做常规统计分析以外,好像完全找不到一个合理有效的方案,因为我们很容易就明白一件事情,即:在短短的 140 个字符中,人类语言的多样性被放大到淋漓尽致 。为了将种种离散的信息收敛在一个统一的结构里,我们必须为这些文本构建一种模型,并努力使这种模型可以量化和计算。我们通过词云对微博进行可视化分析,更多是针对词频的一种分析方法,这种方法虽然可以帮助我们找出关键字,可是因为最初写作这篇文章时,对数据分析领域相关知识知之甚少,而且在分析的过程中没有考虑停用词,所以我认为在文本分类或者是主题提取层面上,我们都需要一种更好的方法。
常见的技术方法
这篇文章涉及的领域称为文本分类或者主题提取,而针对微博、短信、评论等这类短文本的分类,则被称为短文本分类。为什么要进行文本分类呢?第一,提取出潜在主题以后可以帮助我们做进一步的分析。譬如博主这里想要从相亲类微博中分析男性和女性的择偶观,首先要解决的就是主题建模问题,因为在择偶过程中要考虑的因素会非常多,我们到底要选取哪些因素来分析呢?这些因素在特定领域中被称为特征,所以文本分类的过程伴随着特征提取。第二,**短文本数据通常只有一个主题,看起来这是在简化我们的分析过程,实则传统的基于文档的主题模型算法在这里难以适用。**因为这类主题模型算法都假定一篇文档中含有多个主题,而我们分析的是群体现象,这种个体上的差异必须设法将其统一于一体,比如美元和$属于同一个主题,我们需要一种策略来对其进行整合。
传统主题提取模型通常由文本预处理、文本向量化、主题挖掘和主题表示等多个流程组成,每个流程都会有多种处理方法,不同的组合方法会产生不同的建模结果。目前,人们在传统主题提取模型的基础上,发展起了以CNN和RNN为代表的深度学习方法,在这里我们依然关注传统主题提取模型,因为这个领域对博主而言是个陌生的领域,这里我们更多的是关注传统主题提取模型。按照传统主题提取模型,文本分类问题被拆分为特征工程和分类器两个部分,其中,特征工程的作用是将文本转化为计算机可以理解的格式,并提供强特征表达能力,即特征信息可以用以分类,而分类器基本上是统计学相关的内容,其作用是根据特征对数据进行分类。下面来简单介绍下常见的技术方法。
特征工程
特征工程覆盖了文本预处理、特征提取和文本表示三个流程。文本预处理通常指分词和去除停用词这两个过程,可以说分词是自然语言处理的基本前提。特征提取实际上囊括两个部分,即特征项的选择和特征项权重的计算。选择特征项的基本思路是:根据某个评价指标对原始数据进行排序,然后从中选择分数最高的评价指标,同时过滤掉其余的评价指标。通常可以选择的评价指标有文档频率、互信息、信息增益等,而特征权重的计算主要是经典的TF-IDF算法及其扩展算法。文本表示是指将文本预处理后转化为计算机可以理解的格式,是决定分类效果最重要的部分。传统做法是使用词袋模型(BOW)或者向量空间模型(VSM),比如Word2Vec就是一个将词语转化为向量的相关项目。因为向量模型完全忽视文本的上下文,所以为了弥补这种技术上的不足,业界同时使用基于语义的文本表示方法,比如常见的LDA语义模型。
分类器
分类器主要是统计学里的分类方法,基本上大部分的机器学习方法都在文本分类领域有所应用,比如最常见的朴素贝叶斯算法(Naive Bayes)、KNN、支持向量机(SVM)、最大熵(MaxEnt)、决策树和神经网络等等。简单来说,假设我们所有的数据样本可以划分为训练集和测试集。首先,分类器可以在训练集上执行分类算法以生成分类模型;其次,分类器可以通过分类模型对测试集进行预测以生成预测结果;最后,分类器可以计算出相关的评价指标以评估分类的效果。这里最常用的两个评价指标是准确率和召回率,前者关注的是数据的准确性,后者关注的是数据的全面性。
TF-IDF 与朴素贝叶斯
TF-IDF(term frequency–inverse document frequency)是一种被用于信息检索与数据挖掘的统计学方法,常常被用来评估某个字词对于一个文件集或者是一个语料库中的一份文档的重要程度。在特征工程这里我们提到,特征工程中主要通过特征权重来对数据进行排序和分类,因此TF-IDF本质上是一种加权技术。TF-IDF的主要思想是:字词的重要性与它在文件中出现的次数成正比上升,与此同时与它在语料库中出现的频率成反比下降。这句话是什么意思呢?如果某个词或者短语在一篇文章中出现的频率(即TF)较高,并且在其它文章中出现的频率(即IDF)较低,那么就可以人为这个词或者短语可以作为一个特征,具备较好的类别区分能力,因此适合用来作为分类的标准。TF-IDF实际上是 TF * IDF,即 TF(term frequency,词频)与 IDF(inverse document frequency,逆文档频率)的乘积,具体我们通过下面的公式来理解:
 term frequency,词频
显然,这里的 TF 表示某一词条在文档中出现的频率。再看 IDF:
inverse document frequency,逆文档频率
这里的 D 表示语料库中文档的数目,而分母表示的是含有指定词的文档的数目,这里两者求商后取对数即可得到 IDF。需要注意的是,当该词语不在语料库中时,理论上分母会变成 0,这将导致计算无法继续下去,因此为了修正这一错误,我们在分母上加 1,这样就可以得到 IDF 更为一般的计算公式。按照这样的思路,我们将两段文本分完词以后,分别计算每一个词的 tf-idf 并按照 tf-idf 对其进行排序,然后选取前 N 个元素作为其关键字,这样我们就获得了两个 N 维向量,按照向量理论的相关知识,两个向量间的夹角越小,其相关性越显著,这就是文本相似度判断的常规做法,在这个过程中,我们覆盖到了文本预处理、特征提取和文本表示三个过程,相信大家会对这个过程有更好的理解。
term frequency,词频
显然,这里的 TF 表示某一词条在文档中出现的频率。再看 IDF:
inverse document frequency,逆文档频率
这里的 D 表示语料库中文档的数目,而分母表示的是含有指定词的文档的数目,这里两者求商后取对数即可得到 IDF。需要注意的是,当该词语不在语料库中时,理论上分母会变成 0,这将导致计算无法继续下去,因此为了修正这一错误,我们在分母上加 1,这样就可以得到 IDF 更为一般的计算公式。按照这样的思路,我们将两段文本分完词以后,分别计算每一个词的 tf-idf 并按照 tf-idf 对其进行排序,然后选取前 N 个元素作为其关键字,这样我们就获得了两个 N 维向量,按照向量理论的相关知识,两个向量间的夹角越小,其相关性越显著,这就是文本相似度判断的常规做法,在这个过程中,我们覆盖到了文本预处理、特征提取和文本表示三个过程,相信大家会对这个过程有更好的理解。
好了,那么什么是特征呢?这里计算出来的 tf-idf 实际上就是一组特征,这个特征是上下文无关、完全基于频率分析的结果,现在这些结果都是计算机可以处理的数值类型,所以特征工程要做的事情,就是从这些数值中分析出某一种规律出来。譬如,我们通过分析大量的气象资料,认为明天有 80%的概率会下雨,那么此时下雨的概率 0.8 就可以作为一个特征值,在排除干扰因素的影响以后,我们可以做一个简单的分类,如果下雨的概率超过 0.8 即认为明天会下雨,反之则不会下雨。这是一个接近理想的二值化模型,在数学中我们有一种概率分布模型称为 0-1 分布,即一件事情只有两个可能,如果该事件会发生的概率为 p,则该事件不会发生的概率为 1-p。如果所有的问题都可以简化到这种程度,我相信我们会觉得这个世界枯燥无比,因为一切非黑即白、非此即彼,这会是我们所希望的世界的样子吗?
为什么在这里我要提到概率呢?因为这和我们下面要提到的朴素贝叶斯有关。事实上,朴素贝叶斯的理论基础,正是我们所熟悉的条件概率。根据概率的相关知识,我们有以下公式,即全概率公式:P(A|B) = P(AB)/P(B)。我们对 A 和 B 进行交换,同理可得:P(B|A) = P(A/B)/P(A)。由此我们即得到了贝叶斯公式:
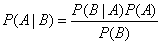 贝叶斯公式
所以,朴素贝叶斯本质上是一种基于概率理论的分类算法。我们知道条件概率成立的前提是各个事件都是独立的,因此在朴素贝叶斯算法中假设所有特征间都是独立的,可当我们逐渐地了解这个世界,就会明白这个世界并不是非黑即白、非此即彼的,甚至一件事情会受到来自方方面面的因素影响,就像我们从前学习物理的时候喜欢用控制变量法一样,总有一天你会明白当时的想法太天真。朴素贝叶斯算法中的“朴素”,通常被翻译为 Naive,而这个词就是表示天真的意思,这正是朴素贝叶斯的名称由来,它简单粗暴地认为各个特征间是相互独立的,有人认为这种假设是相当不严谨的,所以相当排斥这种分类的理论,所幸朴素贝叶斯在实际应用中分类效果良好,尤其是在解决垃圾邮件过滤这类问题上,所以到今天为止,朴素贝叶斯依然是一个相当经典的分类算法,它是一个根据给定特性/属性,基于条件概率为样本赋予某个类别标签的模型。
贝叶斯公式
所以,朴素贝叶斯本质上是一种基于概率理论的分类算法。我们知道条件概率成立的前提是各个事件都是独立的,因此在朴素贝叶斯算法中假设所有特征间都是独立的,可当我们逐渐地了解这个世界,就会明白这个世界并不是非黑即白、非此即彼的,甚至一件事情会受到来自方方面面的因素影响,就像我们从前学习物理的时候喜欢用控制变量法一样,总有一天你会明白当时的想法太天真。朴素贝叶斯算法中的“朴素”,通常被翻译为 Naive,而这个词就是表示天真的意思,这正是朴素贝叶斯的名称由来,它简单粗暴地认为各个特征间是相互独立的,有人认为这种假设是相当不严谨的,所以相当排斥这种分类的理论,所幸朴素贝叶斯在实际应用中分类效果良好,尤其是在解决垃圾邮件过滤这类问题上,所以到今天为止,朴素贝叶斯依然是一个相当经典的分类算法,它是一个根据给定特性/属性,基于条件概率为样本赋予某个类别标签的模型。
数据分析
好了,讲述这些理论知识实在是一件苦差事,因为让读者了解一套新的知识,远远比让自己了解一套新的知识容易,所以在描述这些理论的时候,我努力地避免给大家留下晦涩深奥地印象,可这样难免会让读者觉得我不太专业。可是,谁让我们生活在一个被无数前辈开垦过地世界里呢?作为一个资深的“调包侠”,这些理论我们能理解多少算多少,最终我们需要的只是一个库而已,所以在正式进入下面的内容时,我们首先来梳理侠整体数据分析的思路,这样我们就能对整个过程有一个相对感性的认识了。关于如何从新浪微博抓取数据,这个我们在上篇有详细的介绍,这里不再重复阐述,所有数据我们都存储在数据库里,下面的图示不再展示关于数据库的细节:
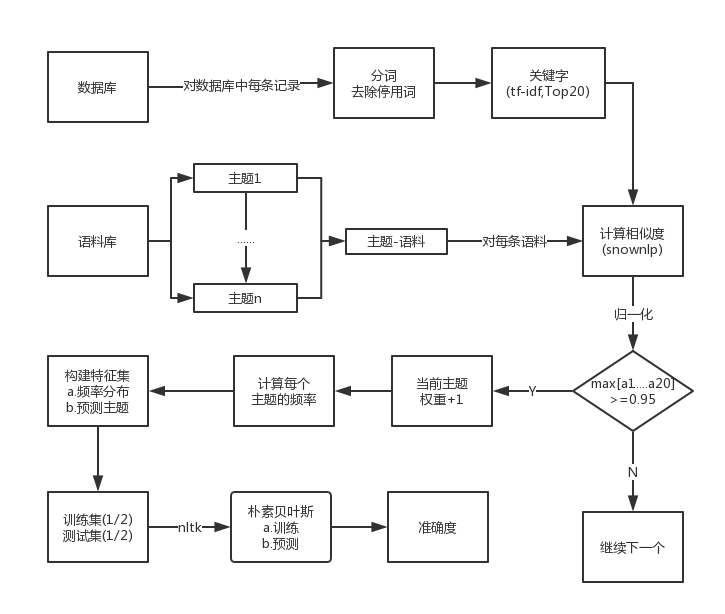 特征分析流程图
简单来讲,这是一个有监督的、使用二元分类的特征提取过程。这里的语料库是由人工进行编制的文本资料,语料库的好坏将直接影响到分类的效果。比如说,我们希望提取的特征是陕西省的地理信息,那么我们就需要准备一个,由陕西省所辖的所有地级市组成的文本文件,这里为了方便后续处理,我们建议每行存放一个短文本信息。
特征分析流程图
简单来讲,这是一个有监督的、使用二元分类的特征提取过程。这里的语料库是由人工进行编制的文本资料,语料库的好坏将直接影响到分类的效果。比如说,我们希望提取的特征是陕西省的地理信息,那么我们就需要准备一个,由陕西省所辖的所有地级市组成的文本文件,这里为了方便后续处理,我们建议每行存放一个短文本信息。
接下来,我们会从数据库中读取所有的数据,然后进行预处理操作,这里的预处理是指分词和去除停用词,停用词表是从网络上下载的,然后根据我们自己的需要再在基础上进行添加,我们会选取前 20 个词语作为关键词,这里使用了结巴分词的相关接口,其算法原理正是 tf-idf。我们会使用这 20 个关键词,和语料库中每一个主题下的内容进行比较,这里的相似度由 SnowNLP 提供支持,其计算结果是一个 20 维的向量,我们对向量进行归一化后,如果其向量中所有维度的值的最大值>=0.95,则认为该文本和这一主题相关,因此该主题的权重会增加 1,否则会继续计算下一个文本的相似度。
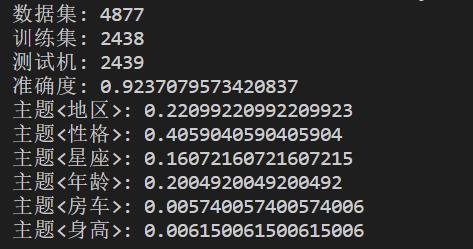
我们汇总所有主题的权重,即可统计出各个主题出现的频率。比如我们这里关注 A、B、C 三个主题,而经过计算这三个主题各自出现的频率为 0.1、0.8 和 0.1,所以我们这里可以理解为:这里有 80%的把握认为文本和 B 主题有关,由此我们选取出了分类的特征,这里我们使用一个元组来表示特征,其表示为([0.1,0.8,0.1],“B”)。依次类推,我们就获得了全部的特征信息。接下来,我们使用 nltk 中提供的朴素贝叶斯分类器对内容进行分类,训练集和测试集合各占 50%,最终通过准确度来评估整个分类的效果。
特征分析
特征分析的难点主要在特征的提取,在这里我们通过不同主题的频率来选取特征:
def buildFeatures(sentence,document):
tokens = jieba.analyse.extract_tags(sentence)
tokens = list(filter(lambda x:x.strip() not in stopwords, tokens))
features = {}
for (subject,contents) in document.items():
for content in contents:
if(similarText(tokens,content)):
if(subject in features):
features[subject]+=1
else:
features[subject]=1
total = sum(features.values())
for subject in features.keys():
features[subject] = features[subject] / total
# 特征归一化
for subject in subjects:
if(subject not in features.keys()):
features[subject] = 0
# 预测结果
max_value = max(features.values())
suggest_subject = ' '
for (key,value) in features.items():
if(value == max_value):
suggest_subject = key
return features, suggest_subject
其中,stopwords 我们从一个指定文件中读取:
stopwords = open('stopwords.txt','rt',encoding='utf-8').readlines()
这里有一个计算句子和主题相似度的方法 similarText(),其定义如下:
# 文本相似度
def similarText(tokens,content):
snow = SnowNLP(tokens)
similar = snow.sim(content)
norm = math.sqrt(sum(map(lambda x:x*x,similar)))
if(norm == 0):
return False
similar = map(lambda x:x/norm,similar)
return max(similar)>=0.95
我们通过下面的代码来构建特征,以及使用朴素贝叶斯分类器进行分类,核心代码如下:
def analyseFeatures():
rows = loadData()
document = loadDocument(subjects)
features = [buildFeatures(row[0],document) for row in rows]
length = len(features)
print('数据集: ' + str(length))
cut_length = int(length * 0.5)
print('训练集: ' + str(cut_length))
train_set = features[0:cut_length]
print('测试集: ' + str(length - cut_length))
test_set = features[cut_length:]
classifier = nltk.NaiveBayesClassifier.train(train_set)
train_accuracy = nltk.classify.accuracy(classifier,train_set)
print('准确度: ' + str(train_accuracy))
counts = Counter(map(lambda x: x[1],test_set))
for key, count in counts.items():
freq = count/len(test_set)
print("主题<{0}>: {1}".format(key,freq))
下面是特征提取相关的结果,因为最近对语料库进行了调整,所以准确度只有 92%,用一位前辈的话说,数据分析就像炼丹,在结果没有出来以前,没有人知道答案会是什么。这里使用的是 nltk 内置的朴素贝叶斯分类器,而 nltk 是一个自然语言处理相关的库,感兴趣的朋友可以自行了解,这里推荐一本书:《NLTK 基础教程(用 NLTK 和 Python 库构建机器学习应用)》。下图中展示了各个主题在整个微博文本中所占的比重:
年龄分布
对于男女性的年龄分布,我们通过正则来提取微博中年龄相关的数值,然后统计不同年龄出现的频数,并将其绘制为柱形统计图,相关代码实现如下:
def analyseAge():
ages = []
rows = loadData()
pattern = re.compile(r'\d{2}\年|\d{2}\岁')
for row in rows:
text = row[0].decode('utf-8')
matches = pattern.findall(text)
if(len(matches)>0):
match = matches[0]
if(u'年' in match):
now = datetime.datetime.now().year
birth = int(''.join(re.findall(r'\d',match)))
ages.append(now - 1900 - birth)
else:
ages.append(int(''.join(re.findall(r'\d',match))))
ages = list(filter(lambda x: x>10 and x<40, ages))
freqs = Counter(ages).items()
freqs = sorted(freqs,key=lambda x:x[0],reverse=False)
freqs = dict(freqs)
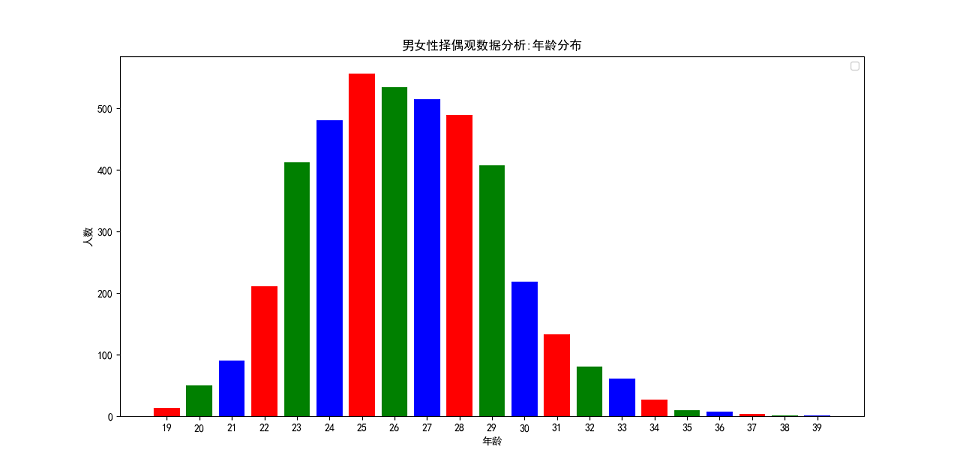
drawing.bar('男女性择偶观数据分析:年龄分布',freqs,'年龄','人数',None)
通过图表,我们可以发现:择偶年龄重点集中在 24~28 岁之间,并且整个年龄区间符合正态分布。每年过年的时候,我们都会听到年轻人被催婚的声音,甚至作为一个单身的人,每一个节日都像是我们的忌日,因为无论在哪里,你都可以被秀恩爱或者被撒狗粮。“哪有人会喜欢孤独呢?不过是不喜欢失望”,当这句话出现在我的 Kindle 屏幕上,出现在村上春树的《挪威的森林》里,我突然有种扎心的感觉。有一天,当我不在视爱情为必需品时,我突然意识到生命里有太多比感情重要的事情。我不希望我们因为一句年龄到了就去结婚,如果人生的一切都有期限都要按部就班,那么为什么我们不能平静地面对衰老和死亡呢?人天生起点就是不一样的,所以你不必努力去迎合别人定制的标准,就像学生时代大家面对的是同一张考卷,有的人交卷交得早,有的人交卷交得晚,有的人考试成绩好,有的人考试成绩差,可这不过是一场考试而已,不是吗?如果我的时间不能浪费在我喜欢的人身上,我宁愿永远将时间浪费在自己的身上,除了生与死以外,结婚和繁衍并不是必答题,我可以不结婚啊,一如我可以交白卷啊!
 男女性择偶观数据分析:年龄分布
男女性择偶观数据分析:年龄分布
性别组成
性别组成,我们主要从微博中的关键字入手,因为这些微博明确了择偶的是男嘉宾还是女嘉宾,我们通过这些特征就可以分析出男女性别比例。相关代码实现如下:
def analyseSex():
rows = loadData()
sexs = {'male':0, "female":0}
for row in rows:
text = row[0].decode('utf-8')
if u'男嘉宾[向右]' in text:
sexs['male']+=1
elif u'女嘉宾[向右]' in text:
sexs['female']+=1
drawing.pie('男女性择偶观数据分析:男女性别比例',sexs,None)
通过下面的图表,我们可以非常直观地看到,男性数量是超过女性数量的,两者比例接近 1.38:1。这和目前中国的实际基本相符,考虑到人们有更多的相亲渠道可以选择,我认为实际的比例应该会更大,媒体称适婚男性比女性多出 3000 万,性别比例的失衡难免会让男生找不到对象。可找不着对象有什么关系呢?人生短短一世,活着时候能见到最多不过四世同堂,血缘关系并不能让后辈替你完成未竟之事,当一个离开了这个世界,它与世界的关联就变得微乎其微,时间会让记忆逐渐模糊直至遗忘,你无法将这点微弱的安全感寄托在某一个人身上,人生而有涯,而知无涯,能在这个世界里流传下去的只有思想,我不想和任何人去攀比,因为生而为人,我很抱歉。
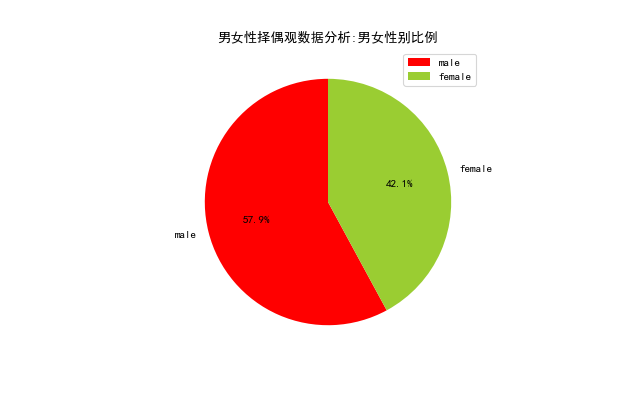 男女性择偶观数据分析:男女性别比例
男女性择偶观数据分析:男女性别比例
身高分布
身高分布,同样采用关键字匹配的方式实现,不同的是,择偶者通常会在微博中给出自己的身高以及对伴侣期望的身高,由此我们对微博中的身高进行了提取,分别获得了男性、女性身高分布及其身高差分布。这是我最开始研究这个问题的初衷,现在的结果印证了当时的想法,我内心其实是特别开心的,这正是为什么要花时间和精力写这篇文章的原因所在。这里,相关的代码实现如下:
# 身高分布
def analyseHeight():
heights = []
rows = loadData()
pattern = re.compile(r'1\d{2}|\d{1}\.\d{1,2}|\d{1}\米\d{2}')
for row in rows:
text = row[0].decode('utf-8')
matches = pattern.findall(text)
if(len(matches)>1):
matches = map(lambda x:int(''.join(re.findall(r'\d',x))),matches)
matches = list(filter(lambda x: x<190 and x>150, matches))
if(len(matches)>1):
height = {}
height['male'] = max(matches)
height['female'] = min(matches)
heights.append(height)
# 男性身高分布
male_heights = list(map(lambda x:x['male'],heights))
male_heights = Counter(male_heights).items()
male_heights = dict(sorted(male_heights,key=lambda x:x[0],reverse = False))
drawing.bar('男女性择偶观数据分析:男性身高分布',male_heights,'身高','人数',None)
# 女性身高分布
female_heights = list(map(lambda x:x['female'],heights))
female_heights = Counter(female_heights).items()
female_heights = dict(sorted(female_heights,key=lambda x:x[0],reverse = False))
drawing.bar('男女性择偶观数据分析:女性身高分布',female_heights,'身高','人数',None)
# 男女身高差分布
substract_heights = list(map(lambda x:x['male']-x['female'],heights))
substract_heights = Counter(substract_heights).items()
substract_heights = dict(sorted(substract_heights,key=lambda x:x[0],reverse = False))
drawing.bar('男女性择偶观数据分析:男女身高差分布',substract_heights,'身高差','人数',None)
虽然女生都希望男生 180 以上,据说这样可以举高高、有安全感,可是作为一个成年人,我们必须勇敢地打破这种不切实际的幻想,因为身高和外貌都是父母给我们的,那些基因里决定的东西,往往是我们无法通过后天努力来弥补的。如果可以的话,我希望自己再长高 5 厘米,可如果我再无法长高,我希望你能接受现在的我,接受一个人身高上的缺陷,和接受一个人人性中的缺点,在我看来是一模一样的。可人类最大的问题, 就在于愿意相信自己眼睛看到的,耳朵听到的,并且这是两个人建立联系的前提,人家愿意了解你有趣的灵魂,前提是你有一副好看的皮囊,人类啊,说到底是一种比较高级的动物而已,就像动物用皮毛、肤色去吸引同类一样,如你所见,男生平均身高其实只有 175 而已!
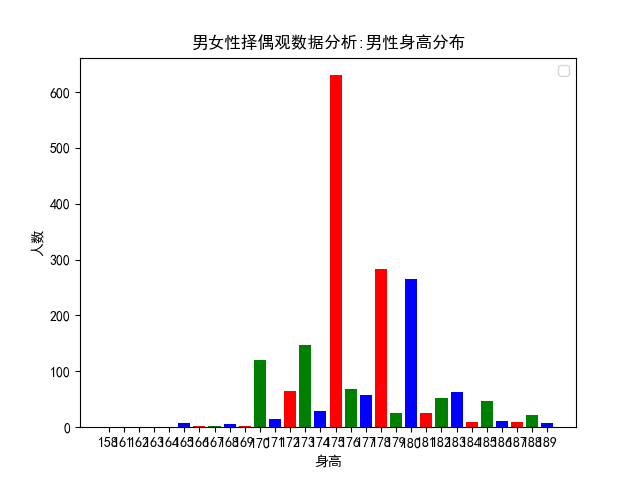 男女性择偶观数据分析:男性身高分布
男女性择偶观数据分析:男性身高分布
女性的身高通常不会被作为筛选条件,正如社会群体通常都是对男性提出各种要求一样,两个同等条件下的男、女性,人们理所当然地对男性提出了更高的要求,可其实大家都是母亲十月怀胎而来,同样地都在这个世界里生活了 20 多年。所以这个世界上有太多地问题,其实都是人们自己造成的。比如女性一定要找一个穿高跟鞋后还要比她高的男性,而男性一定要找一个身高上和他相差不大的女性,男性的身高不足 175,同女性的身高不足 165 一样,都是人们眼中比较尴尬的身高,可你看这图表中女性的平均身高是 160,那么,就让大家一起尴尬吧,不知道当年小平爷爷和拿破仑将军的夫人心里是怎么想的啦!
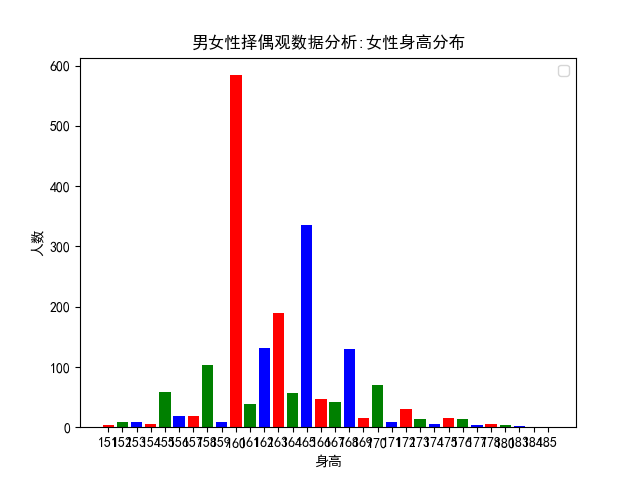 男女性择偶观数据分析:女性身高分布
男女性择偶观数据分析:女性身高分布
最初我研究这个问题的时候,我发现微博上有好多身高不足 160 的女性,要求伴侣期望身高都是 175 以上,作为一个身高只有 170 的男生,我感到绝望和悲伤啊,后来和一位朋友聊天,他说他觉得我连 170 都没有,我想说人类为什么要这般奇怪,譬如体重一定要说得比实际轻、身高一定要说得比实际高、年龄一定要说得比实际小……难道这样不感觉累吗?那么到底有多少人希望两个人的身高差超过 20 厘米呢?网络上流传的所谓最萌身高差到底萌不萌呢?你看孟德尔通过豌豆杂交试验来研究遗传问题,两个身高差超过 20 厘米的人的后代,平均下来难道不是只有 170 吗?图表表明,男女性之间最佳的身高差是 15 厘米。
 男女性择偶观数据分析:男女身高差分布
男女性择偶观数据分析:男女身高差分布
地理分布
因为在这些微博中会出现相亲者的地理信息,所以我们整理了陕西省各县市的名称作为关键字,试图分析出这些相亲者的地理分布,这里我们简单绘制了一个柱形图,相关代码实现如下:
# 地区分析
def anslyseLocation():
freqs = { }
citys = [u'西安',u'铜川',u'宝鸡',u'咸阳',u'渭南',u'延安',u'汉中',u'榆林',u'安康',u'商洛']
rows = loadData()
for row in rows:
text = row[0].decode('utf-8')
for city in citys:
if(city in text):
if(city in freqs.keys()):
freqs[city]+=1
else:
freqs[city]=1
drawing.bar('地区分布图',freqs,'地区','人数',None)
这里的结果令人出戏,因为西安作为陕西省的省会城市,在所有地区中一骑绝尘。考虑到在这些微博中"西安"存在干扰,所以这个结果并不是非常严谨,不能作为一个有效的分析指标,而且这里存在同义词,比如"本地"和"土著"其实都表示西安,而我们统计的时候并没有考虑这种情况,所以这里绘制的地区分布图表,大家看看就好啦!
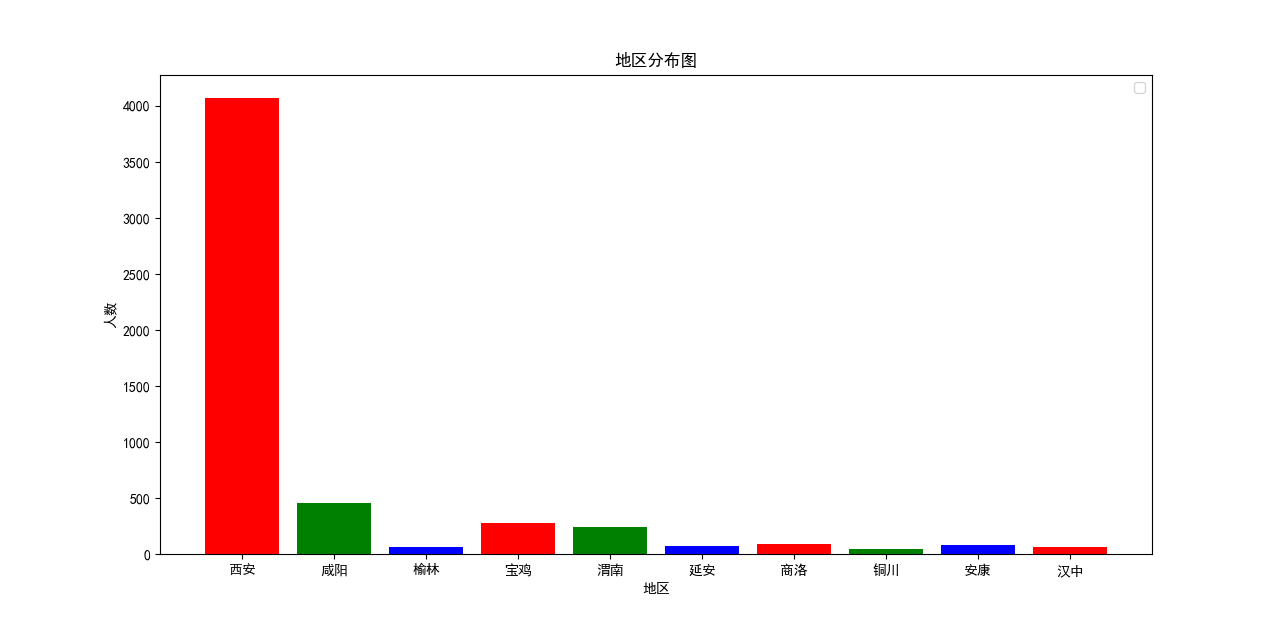 男女性择偶观数据分析:地区分布图
男女性择偶观数据分析:地区分布图
星座分布
这里为什么要分析星座呢?理论上来讲,我是不大相信这些东西的,可当你经历的事情多了以后,你就会下意识地认为这些东西说得很对,我想古代的占卜算卦基本上是同样的东西,其实世间好多事情之间应该是没有直接的联系的,无非是在千百年的历史积淀中,逐渐地形成了一套建立在经验上的理论体系,这就像我们今天所追捧的机器学习,我们有千百年的历史长河去收集数据,每一个相信这些理论的人都是一个数据样本,这些理论体系通过不断地训练和模拟,逐渐可以正确地预测某些事情,让我们相信万事万物间存在某种联系。可即便如此,人类依旧免不了对各种事物存在偏见,比如星座中经常无辜躺枪的处女座、双子座和天蝎座,人类最擅长的认知方式,就是用一个群体现象来预测个人现象,可讽刺的是朴素贝叶斯就是这样的思想,所以这里我们简单地统计了下各种星座的频数分布:
# 星座分析
def analyseStar():
stars = ['白羊','金牛','双子','巨蟹','狮子','处女','天秤','天蝎','射手','摩羯','水瓶','双鱼']
freqs = {}
rows = loadData()
for row in rows:
text = row[0].decode('utf-8')
for star in stars:
if(star in text):
if(star in freqs.keys()):
freqs[star]+=1
else:
freqs[star]=1
for star in stars:
if(star not in freqs.keys()):
freqs[star] = 0
freqs = Counter(freqs).items()
freqs = dict(freqs)
drawing.pie('男女性择偶观数据分析:星座分布',freqs,None)
这个结果相对客观些,因为 12 个星座基本上平分秋色啦,并不存在某种星座独领风骚的情况,简直是人与自然的大和谐了呢?
 男女性择偶观数据分析:星座分布
男女性择偶观数据分析:星座分布
本文小结
这篇文章写到这里,我其实已经非常疲惫啦,因为这篇文章的上篇与下篇中间相隔了差不多三个月,而且我写作上篇的时候,并没有打算写这一篇文章出来,再者两篇文章写作时的心境完全不同,所以现在写完这篇文章,终于有种如释重负的感觉,一来没有因拖延症而放弃这篇文章,二来为了了解相关的理论以及训练数据花费大量精力,我必须对自己的过去有一个总结,这是我今年年初给自己制定的目标,不管有没有喜欢我,我总要去做这些事情,不是因为我想要证明什么或者做给谁看,而是我认为这件事情比某些事情有趣而且重要。这篇文章首先承接上文,交待故事的背景,即为什么要做这样的数据分析;然后我们简单介绍了文本分类的常用的技术方法,主要以特征工程和分类器为主;接下来我们介绍了两个经典的理论:tf-idf 和朴素贝叶斯,这是本文文本分类的理论基础;在数据分析这部分,我们对特征、年龄、性别、身高、地区和星座等进行了分析,并借助 Python 中的图表模块完成了数据的可视化工作。好啦,以上就是这篇文章的全部内容啦,欢迎大家积极留言和评论,晚安!


