最近一段时间,博主感觉到了某种危机感,或者说是每一个不再年轻的人都会面对的问题,即,怎么面对来自更年轻的“后浪”们的压力,自打国内 IT 行业有了 35 岁这个不成文的“门槛”以后,年轻的“后浪”们仿佛有了更多将“前浪”们拍死在岸上的勇气,我辈忍不住要叹一声后生可畏啊!我认识的 Catcher Wong 正是这样一位大佬,此君虽然比我小三岁,可在技术的广/深度以及经验的丰富程度上,足以令我这个”老人”汗颜,单单 EasyCaching 这一项,就令人望尘莫及啦!我看着他的时候,一如当年 Wesley 大哥看着我的时候,可能这就是某种轮回,姑且执浊酒一杯,致我们终将老去的青春。
不正经的 Kimol 君
关注Kimol 君,最早源于他在我博客里留言,作为礼尚往来,我回访了他的博客,然后发现此人人如其名,非常的”不正经”,他的博客访问量出奇地高,在 CSDN 里写博客多年,深知现在不比从前有运营梦鸽和大白两位小姐姐帮忙推荐到首页,普通的内容很少有机会拥有这样的曝光机会,而像 郭霖 这种从 10 年前后开始写移动开发系列博客的“大神”或者是以图形学为主要写作方向的 诗人“浅墨” ,在通篇都是干货的情况下,长期保持着不错的人气。

起初,我以为此君的流量来自于标题党,譬如《学会这招,小姐姐看你的眼神将不一样》 和 《震惊!小伙竟然用 Python 找出了马大师视频中的名场面》这几篇,非常像 UC 编辑部和微信公众号的风格。我是一个擅长学习的人,主动去借鉴了他博客中的优点,比如尝试使用轻松、幽默的文风,在文章开头放入目录,适当“蹭”热点等等,我甚至专门致敬了一篇博客: 《厉害了!打工人用 Python 分析西安市职位信息》。而整个 1 月份,我就只有一篇博客流量高一点,就这还不是特别正经的”技术”博客,而此君的流量则是一个又一个的 1w+ ,可我实在想不通,一个不到 100 行的 Python 脚本,真就值得花那么多的流量,真就值得上百条的评论吗?这里放张图大家感受一下:
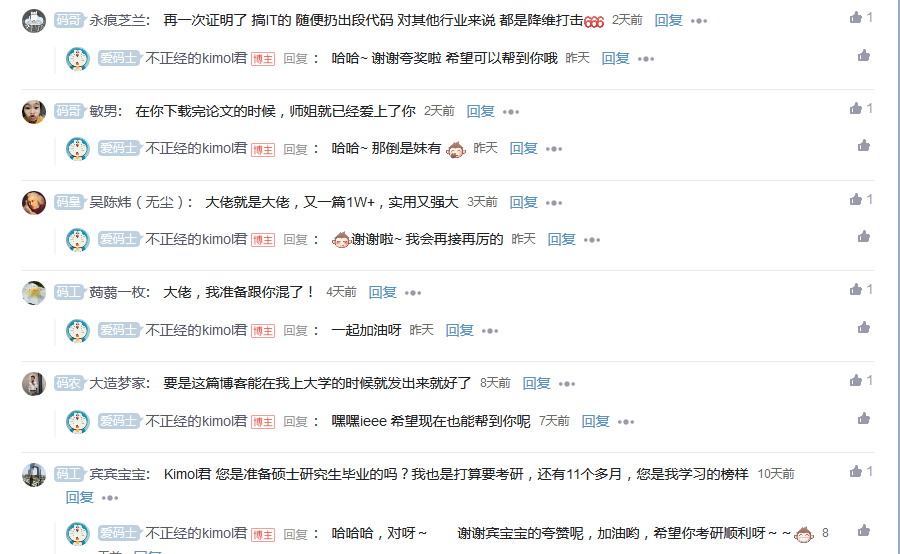
仔细研究了他博客里评论的风格,发现有大量类似“夸夸群”风格的评论,就是那种读起来确实像对方读过了你的文章,可实际一想就觉得这是那种“放之四海而皆准”的话。我最近知道了一位大佬的博客,我惊奇地发现,此君居然在上面留过言,我顺着大佬的博客继续找,发现一个非常有意思的事情,此君曾经给我留言过的内容,居然出现在了别人的博客底下,而从这篇博客的评论里继续找,你会发现好像有一个团队专门在做这种事情,互相点赞、互相评论,甚至这些留言都是来自一篇博客都没有的”新人”,至此,基本可以断定,此君“不讲武德”,用作弊的方式在刷流量!当然,他自己都承认了:

年轻人不讲”武德”
OK,既然现在的年轻人都把心思用到这种事情上,作为一个老年人,必须要让他知道什么叫“耗子尾汁”,我们技术做一点正经事儿不行吗?其实,博客园的博客质量相比 CSDN 是要高出许多的,而正因为如此,CSDN 在全力转在线教育/课程以后,博客这个板块就再无往日的“生气”,如果每个人都像他一样,天天跑别人底下刷评论,发一点不痛不痒的话,甚至是推广某个小圈子里的 QQ 群,那真正优质的内容又如何能被大家看到呢?博主曾经加过这样的 QQ 群,你以为是交流技术的群吗?其实是为了推广某个 Python 课程,博主本想交流一下“半泽直树”,然后就被群管理员给删除了!此君大概是抓取 Python 板块排名靠前的博客,通过程序来刷存在感。
对此,我想说,这玩意儿用 Selenium + Python 简直和闹着玩一样,毕竟在了解网页结构以后,直接上 jQuery 操作 DOM 即可,甚至连抓包都不需要,不信你看:
import requests
from bs4 import BeautifulSoup
import fake_useragent
import os, json, time, random
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class Proxy:
def __init__(self, profile):
os.environ['TEMPDIR'] = os.path.join(os.path.abspath('.'), 'profile')
firefoxProfile = webdriver.FirefoxProfile(profile)
fireFoxOptions = webdriver.FirefoxOptions()
self.driver = webdriver.Firefox(
firefox_options=fireFoxOptions,
firefox_profile=firefoxProfile
)
# 批量点赞
def vote(self, urls):
'''
对指定的一组博客地址批量进行点赞
'''
for url in urls:
self.driver.get(url)
time.sleep(3)
flag = self.driver.execute_script("return $('#is-like-span').text().trim()") == "已赞"
if not flag:
self.driver.execute_script("$('#is-like-span').click()")
time.sleep(1)
# 批量收藏
def collect(self, urls):
'''
对指定的一组博客地址批量进行收藏
'''
for url in urls:
self.driver.get(url)
time.sleep(3)
flag = self.driver.execute_script("return $('#is-collection').text()") == "已收藏"
if not flag:
self.driver.execute_script("$('#is-collection').click()")
self.driver.execute_script("$('.csdn-collection-submit').click()")
time.sleep(1)
# 批量关注
def follow(self, urls):
'''
对指定的一组博客地址批量进行关注
'''
for url in urls:
self.driver.get(url)
time.sleep(3)
flag = '已关注' in self.driver.execute_script(
"return $($('.toolbox-list').children()[6]).find('a').text().trim()"
)
if not flag:
self.driver.execute_script("$($('.toolbox-list').children()[6]).find('a').click()")
time.sleep(1)
# 批量一键三连
def iloveyuou(self, urls):
'''
对指定的一组博客地址批量进行三连
'''
for url in urls:
self.driver.get(url)
time.sleep(3)
self.driver.execute_script("$($('.toolbox-list').children()[7]).find('p').click()")
time.sleep(1)
# 批量留言
def comment(self, urls, texts):
'''
对指定的一组博客地址批量进行评论
'''
for url in urls:
self.driver.get(url)
time.sleep(3)
text = random.choice(texts)
self.driver.execute_script(f"$('#comment_content').text('{text}')")
self.driver.execute_script(f"$('.btn-comment').click()")
# CSDN对评论间隔有要求,那就再睡一会儿
time.sleep(5)
# 热门文章
def hotRank(self, channel):
'''
抓取某个话题下的热门文章
'''
url = f'https://blog.csdn.net/phoenix/web/blog/hotRank?page=0&pageSize=25&child_channel={channel}'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
'Cookie':'uuid_tt_dd=10_220300310-1611402514139-727015; dc_session_id=10_1611402514139.129755; dc_sid=37a633fe075b2698beeae6fb9c306fb4'
}
response = requests.get(url, headers=headers)
response.raise_for_status()
data = json.loads(response.text)
if (data['code'] == 200 and data['message'] == 'success'):
return list(map(lambda x:x['articleDetailUrl'], data['data']))
else:
return []
我们都知道,在通常情况下,Selenium 每次运行时都会打开一个浏览器, 可这个浏览器呢,相对于我们平时使用的浏览器来说是“独立”的,因为细心的朋友一定会发现,虽然我们在 Chrome 或者 Firefox 中早已登录过了某个网站,可此时此刻,当 Selenium 启动浏览器窗口的时候,我们发现这个网站依然是需要登录的。为什么要讨论这个问题呢?因为如果我们希望对 CSDN 实现“一键三连”,登录这一步是必不可少的步骤。那么,有没有一种办法,可以让 Selenium 共享我们本地浏览器中的 Cookie 信息呢?因为只要有了 Cookie,我们就可以专注于实现“一键三连”这部分。相信大家都看过上面的代码啦,答案当然是有的,我们为其指定一个配置文件的路径即可:
# 设置 Firefox 配置文件
# 默认路径:C:\\Users\\<User>\\AppData\\Roaming\\Mozilla\\Firefox\\Profiles\\XXXX.default
# 参考链接:https://support.mozilla.org/zh-CN/kb/用户配置文件
profile_dir = 'C:\\Users\\YuanPei\\AppData\\Roaming\\Mozilla\\Firefox\\Profiles\\xypbnthd.default-release'
firefoxProfile = webdriver.FirefoxProfile(profile_dir)
fireFoxOptions = webdriver.FirefoxOptions()
webdriver.Firefox(firefox_options=fireFoxOptions, firefox_profile=firefoxProfile)
# 设置 Chrome 配置文件
# 默认路径:C:\\Users\\<User>\\AppData\Local\Google\Chrome\User Data
profile_dir = 'C:\\Users\\YuanPei\\AppData\Local\Google\Chrome\User Data'
chromeOptions = webdriver.ChromeOptions()
chromeOptions.add_argument('user-data-dir=' + os.path.abspath(profile_dir))
webdriver.Chrome(chrome_options=chromeOptions)
这样,Selenium 启动的就不再是一个“裸”的浏览器,我们平时使用的各种配置、插件等等都会被原封不动地加载到 Selenium 中,这其中同样了我们的 Cookie,所以,当大家看到我的代码的时候,会发现这里没有做任何登录相关的事情,这其实是在用“时间”换取技术实现的“简单”,因为要额外加载大量的信息,所以,Selenium 启动的时候会变得缓慢起来,经过博主自己测试,Firefox 启动大概需要 1 分钟左右,熬过这 1 分钟接下来就是坦途啦!
其实,除此以外,关于登录这个问题,我们还有一种方案是对 Cookie 进行持久化。简而言之,就是利用 Selenium 的get_cookies() 和 add_cookie() 这一组 API,第一次打开某个网站的时候,首先人为地或者模拟登录,此时可以获得 Cookie 并对其进行序列化,而访问那些需要登陆的资源时,则可以对 Cookie 进行反序列化并将其加载到 Selenium 环境中,基本的代码示例如下:
# 保存Cokie到本地文件
cookies = driver.get_cookies()
with open("cookies.txt", "w") as fp:
json.dump(cookies, fp)
# 从本地文件加载Cookie
with open("cookies.txt", "r") as fp:
cookies = json.load(fp)
for cookie in cookies:
driver.add_cookie(cookie)
下面来做一个简单的演示, CSDN 有一个类似微博热搜的 博客榜单。这里,我们会从中筛选前 5 的博客链接来进行“一键三连”操作。与此同时,博主选取了一部分这些年轻人们喜欢用的评论,就在刚刚,我在这篇博客 《第十二届蓝桥杯模拟赛 Python 组(第一期)》 下面再次发现 Kimol 君 的身影,年轻人你不讲武德啊!我就想起了《开讲啦》里面惹恼易中天教授的那位学生,一个人的文章写得好,大家愿意去读去看,这自然是好事,可正因为梦鸽和大白这些小姐姐们都不在了,这个社区的内容质量完全由点赞、评论、收藏数这些因素在左右着,作为一名博客作者,我更希望别人能真的在读完我的文章后,或者能找出我考虑不周的地方,或者可以就某一个问题深入讨论一番,我发现社区里都喜欢动辄加别人 QQ 或者微信,可如果这种毫无意义地灌水的评论,这一切又有什么意义呢?
# 如果你经常收到这些评论,千万不要“飘”
# 你觉得这些话都是真心的吗?
comments = [
'代码之路任重道远,愿跟博主努力习之。',
'学起来,头秃的那种~',
'写的太好了,很实用',
'好文!希望博主以后多多分享哈!',
'哇,好棒啊,崇拜的小眼神,欢迎回赞,回评哦~~~',
'收藏从未停止,学习从未开始。',
'大佬,看了您的文章,内心的仰慕之情油然而生,赶紧给大佬点个赞!',
'太赞了!666666'
]
proxy = Proxy('C:\\Users\\YuanPei\\AppData\\Roaming\\Mozilla\\Firefox\\Profiles\\xypbnthd.default-release')
# 热搜前5名的文章
urls = proxy.hotRank('python')[:5]
# 批量留言,刷存在感
proxy.comment(urls, comments)
# 一键三连
proxy.iloveyuou(urls)
当然啦,像我这里提供的关于点赞(vote)、收藏(collect)、关注(follow)等等方法,同样是可以使用的,这里就不再一一例举啦!本身都是基于 jQuery 来操作 DOM,理解上应该没有太大难度,虽然我不大喜欢用 jQuery 写业务代码,可对于爬虫这种事情,自然是越简单越好,因为我不想再去学一门操作 DOM 的语言:XPath, 而关于 Selenium 驱动的安装、配置等细节,可以参考博主的这篇文章:
博主最近新开了一个付费专栏:Python 数据挖掘系列,主要介绍关于爬虫、PyECharts、结巴分词、Pandas、Matplotlib、SnowNLP、OpenCV 等数据挖掘相关内容,如果大家喜欢或者感兴趣,欢迎订阅。好了,以上就是这篇博客的全部内容啦,欢迎大家在评论区,就你对于这篇博客的想法或者意见进行讨论,再次谢谢大家!如果 Kimol 君 恰好读至此处,最好能一键三连,我权当作为你打广告的广告费啦,哈哈!


