最近博主在优化一个爬虫程序,它是博主在 2017 年左右刚接触 Python 时写下的一个程序。时过境迁,当 Python 2.X 终于寿终正寝成为过去,当博主终于一只脚迈进 30 岁的大门,一切都来得猝不及防,像一阵龙卷风裹挟着回忆呼啸而去。和大多数学习 Python 的人一样,博主学习 Python 是从写爬虫开始的,而这个爬虫程序刚好是那种抓取“宅男女神”的程序,下载图片无疑是整个流程里最关键的环节,所以,整个优化的核心,无外乎提升程序的稳定性、提高抓取速度。所以,接下来,我会带大家走近 Python 中的多线程编程,涉及到的概念主要有线程(池)、进程(池)、异步I/O、协程、GIL等,而理解这些概念,对我们而言是非常重要的,因为它将会告诉你选择什么方案更好一点。想让你的爬虫更高效、更快吗?在这里就能找到你的答案。
楔子
现在,假设我们有一组图片的地址(URL),我们希望通过requests来实现图片的下载,为此我们定义了Spider类。在这个类中,我们提供了getImage()方法来完成下载这个动作。我们可以非常容易地写出一个“单线程”的版本,但这显然这不是我们今天这篇博客的目的。此时,我们来考虑一个问题,怎么样实现一个“多线程”的版本?
class Spider:
def __init__(self, urls):
self.session = requests.session()
self.session.headers['User-Agent'] = fake_useragent.UserAgent().random
self.session.headers["Referer"] = "https://www.nvshens.org"
self.urls = urls
# 下载图片
def getImage(self, url, fileName, retries=5):
try:
print(f'{threading.currentThread().name} -> {url}')
response = self.session.get(url,
allow_redirects=False,
timeout=10,
proxies=None
)
response.raise_for_status()
data = response.content
imgFile = open(fileName, 'wb')
imgFile.write(data)
imgFile.close()
return True
except :
while retries > 0:
retries -= 1
if self.getImage(url, fileName, retries):
break
else:
continue
线程与线程池
既然提到了线程,我们会非常自然地想到 Thread 和 ThreadPool ,而这几乎是所有编程语言里都有的通用型概念。可是,Python 中的多线程其实是一种“假”的多线程,这又从何说起呢?答案是全局解释器锁(GIL),原来在设计 Python 解释器的时候,为了保证同时只有一个线程在运行,引入了这样一个锁,你可以类比游戏开发时主循环的概念来辅助理解。那为什么又说 Python 中的多线程是一种“假”的多线程呢?这是因为它没法发挥出多核的优势,每个线程在执行前都要先获得 GIL ,这就导致一个问题,即使你有多个核心,线程永远只能用到其中一个核,因为多线程在 Python 中只能交替执行。以一言蔽之, Python 中 I/O 密集型任务相比 CPU 密集型任务更能充分发挥多线程的好处。所以,像爬虫这种和网络打交道的事物,是非常适合使用多线程来提高效率的。在这里,我们我们要介绍的是 Thread 和 ThreadPool 以及 ThreadPoolExecutor。
Thread
首先,我们需要了解的是,Python 中的 Thread ,实际上先后有thread和threading两种模块,它们的关系有一点像 .NET 里的Thread和Task,考虑到thread的使用频率非常低,这里我们更推荐大家使用threading,它提供了更高级的、完全的线程管理。例如,我们现在面临的这个“多线程”下载的问题,使用threading的话可以这样解决:
# 使用Thread下载
def downloadByThread(self):
threads = []
for index in range(0, len(self.urls)):
thread = threading.Thread(
target=self.getImage,
args=(self.urls[index], f'{str(index)}.jpg',)
)
threads.append(thread)
for thread in threads:
thread.setDaemon(True)
thread.start()
可以注意到,当我们需要构造一个线程时,只需要指定target和args两个参数,其中,前者是指线程执行的方法,后者是指传递给线程所执行的方法的参数。当我们需要启动线程时,只需要调用线程的start()方法,而通过setDaemon()方法则可以设置一个线程为守护线程。关于守护线程,这里简单说明一下,一旦一个线程被设置为守护线程,那么,只要线程执行的方法中存在等待时间譬如time.sleep(1),此时等待时间下面的代码都不会再执行。如果线程中执行的方法是一个耗时的操作,此时,我们还可以通过join()方法来阻塞主线程,以确保主线程再子线程执行完后再结束。除了这种函数式的使用方法以外,我们还可以通过继承Thread类并重写其run()方法的方式,对于这一点可以参考官方文档中的线程对象。

ThreadPool
对于线程,我们都知道它是作为一种系统资源而存在的,所以,和这个世界上的大多数资源一样,无法供我们肆意地挥霍和浪费。在 .NET Core 中对象池(Object Pool)的使用 这篇博客中,我曾经大家介绍过“对象池”这种设计,和这篇博客中所提到的原理一样,线程池相对于普通线程而言多了一种可复用的可能性,这意味着我们可以用有限的线程来下载可能无限多的图片资源。在 Python 中我们使用 threadpool 模块来实现线程池的功能,需要注意的是这是一个第三方的模块。下面,我们来一起看看具体的使用方法:
# 使用ThreadPool下载
def downloadByThreadPool(self, poolSize=3):
count = len(self.urls)
# 构造线程参数
args = []
for index in range(0, count):
args.append((None, {'url': self.urls[index], 'fileName': f'{str(index)}.jpg'}))
# 线程池大小
if count < poolSize:
poolSize = count
# 构造线程池
pool = threadpool.ThreadPool(poolSize)
requests = threadpool.makeRequests(self.getImage, args)
[pool.putRequest(req) for req in requests]
pool.wait()
在这里,我们声明了一个指定大小的线程池,通过一个方法getImage()和一组参数args来构造“请求”,再将这些请求全部放进线程池里,此时,线程池会自动等待这些“请求”执行完毕。这里唯一比较难理解的,可能是如何构造参数args,尤其是当被执行的方法需要传递多个参数的时候。其实这里有两种传参的方式,第一种是按数组来解构,此时我们可以写[(['',''], None), (['',''], None)];而第二种则是按字典来解构,此时我们可以写[(None, {'url':'', 'fileName':''}), (None, {'url':'', 'fileName':''})。两者的区别主要在None的位置,不知道大家有没有发现规律。这里我们准备了张图片,而线程池最大线程是 3 个,理论上某个线程会被重复使用,实际结果又是如何呢?
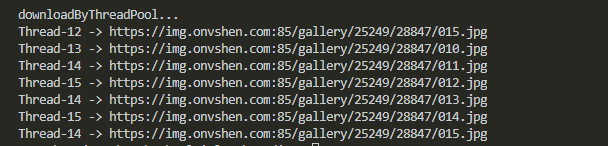
ThreadPoolExecutor
对于ThreadPoolExecutor,相信不用我多说什么,你就能知道它是做什么的吧,这就是博主反复提及的命名规范的问题。简而言之,Python 在 concurrent.futures中为我们提供了 ThreadPoolExecutor 和 ProcessPoolExecutor 两个高级接口,它们都继承自同一个抽象类Executor,它可以让我们在线程池或者进程池中异步地执行回调函数,属于官方提供的标准的“线程池”和“进程池”模块,下面,我们来一起看看具体的使用方法:
# 使用ThreadPoolExecutor下载
def downloadByThreadPoolExecutor(self, poolSize=3):
count = len(self.urls)
# 构造线程参数
args = []
for index in range(0, count):
args.append({'url': self.urls[index], 'fileName': f'{str(index)}.jpg'})
# 线程池大小
if count < poolSize:
poolSize = count
# 构造线程池
pool = ThreadPoolExecutor(max_workers=poolSize)
tasks = []
for arg in args:
task = pool.submit(self.getImage(arg['url'], arg['fileName']), arg)
tasks.append(task)
wait(tasks, return_when=ALL_COMPLETED)
# tasks = pool.map(lambda arg:self.getImage(arg['url'], arg['fileName']), args)
这里需要注意的是,submit()方法和map()方法的区别,前者相当于声明线程后并不立即执行,故而,需要wait()方法来等待所有任务执行结束;而后者则相当于声明线程并理解执行,故而,返回值实际是每一个任务执行的结果的集合,这里就隐隐有一点 .NET 中 Task 的味道啦!同样地,我们给了一个最大线程数:3,它能否得到和threadpool 类似的结果呢?我们拭目以待:

进程与进程池
看到这里,可能有读者朋友会忍不住吐槽,博主你三十岁不到,怎么越来越糊涂了啊,你这博客标题明明写的是多线程,怎么写着写着就写到进程上来了呢?其实,这里是紧接着 GIL 这个话题来讲的。既然 Python 中的多线程更适合 I/O 密集型的任务,那么,是不是说 Python 不适合处理 CPU 密集型的任务呢?答案是否定的,我们这里将多进程理解为并行就会更容易想明白一点。我们都知道操作系统可以同时执行多个任务,而这每一个任务其实就是一个进程,而每个进程内又可以同时执行多个子任务,这每一个子任务其实就是一个线程。这样说,我们或许就能明白,这意味着,如果我们的确需要并行地去处理某些任务,进程(池)或许是个不错的选择。同样地,这里介绍的是,Process、ProcessPool 和 ProcessPoolExecutor。
Process
关于进程,我个人感觉比线程要更好理解一点,因为不论是 Windows 下的任务管理器,亦或者是我们经常听到的“杀进程”,它都不算是一个特别陌生或者抽象的概念,而线程这种东西呢,大概是只有程序员会关注,同时爱之弥深、恨之弥切的一种事物。庆幸的是,在 Python 中线程与进程在代码的编写上是非常相似的,这里我们需要用到的是multiprocessing模块,下面,我们来一起看看 Python 中的进程的的使用方法,你会发现只需要改一下threading.Thread()这部分:
# 使用Process下载
def downloadByProcess(self):
process = []
for index in range(0, len(self.urls)):
proc = multiprocessing.Process(
target=self.getImage,
args=(self.urls[index], f'{str(index)}.jpg',)
)
process.append(proc)
for proc in process:
proc.start()
此时,我们可以得到下面的结果,可以发现它都是在主线程上运行:
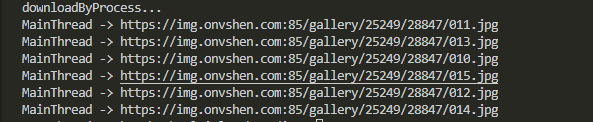
ProcessPool
既然有“线程池”,又怎么能少得了进程池呢?同样地,它位于multiprocessing模块中,通过apply()方法来执行某个任务,下面是一个基本的示例:
# 使用multiprocessing.Pool()下载
def downloadByProcessPool(self, poolSize=3):
count = len(self.urls)
# 构造线程参数
args = []
for index in range(0, count):
args.append((self.urls[index], f'{str(index)}.jpg', ))
# 线程池大小
if count < poolSize:
poolSize = count
# 构造线程池
pool = multiprocessing.Pool(poolSize)
for arg in args:
pool.apply(self.getImage, arg)
有朋友难免会好奇“进程池”和“线程池”有什么不一样,我想,下面这张图会告诉你答案:
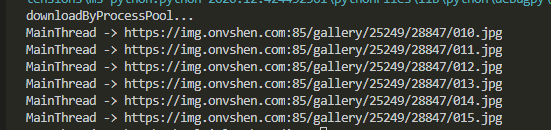
ProcessPoolExecutor
和 ThreadPoolExecutor 类似,我们还可以使用 ProcessPoolExecutor 来实现“进程池”:
# 使用ProcessPoolExecutor下载
def downloadByProcessPoolExecutor(self, poolSize=3):
count = len(self.urls)
# 构造线程参数
args = []
for index in range(0, count):
args.append({'url': self.urls[index], 'fileName': f'{str(index)}.jpg'})
# 线程池大小
if count < poolSize:
poolSize = count
# 构造线程池
pool = ProcessPoolExecutor(max_workers=poolSize)
for arg in args:
pool.submit(self.getImage(arg['url'], arg['fileName']), arg)
可以看到,“进程池”中的代码都是在主线程上执行的,这一点和multiprocessing.Pool()完全一致:

协程与异步 I/O
其实,如果单单从 I/O 密集型和 CPU 密集型两种场景而言,这篇博客到这里就差不多应该结束啦!不过呢,博主好奇 Scrapy 这个爬虫框架的实现原理,发现它是基于 Twisted 这样一个异步网络框架,考虑到目前为止,我们通过 requests 来下载图片都是采用同步的方式,除了任务调度上的优化以外,任务本身还存在一定的优化空间,所以,这里就顺带着一起整理出来,这里主要结合 asyncio 和 requests 来对 Python 中关于异步 I/O 、协程等的使用方法进行演示和说明。
asyncio
asyncio 是用来编写 并发 代码的库,使用 async/await 语法,它是构建 I/O 密集型和高层级 结构化 网络代码的最佳选择。它提供了类似并发地执行协程、网络 I/O 和进程间通信(IPC)、事件循环等等的能力,例如,我们可以通过下面的代码来创建和使用协程:
import asyncio
async def say_after(what, delay):
await asyncio.sleep(delay)
print(what)
async def main():
await say_after('你好', 1)
await say_after('Hello', 2)
# 方式1
# Python 3.7 +
asyncio.rum(main())
# Python 3.7 -
asyncio.get_event_loop().run_until_complete(main())
参考官方文档,我们还可以使create_task()方法来创建asyncio的并发任务:
# 方式2
async def main():
# Python 3.7 +
task1 = asyncio.create_task(say_after('你好', 1))
task2 = asyncio.create_task(say_after('Hello', 2))
# Python 3.7 -
task1 = asyncio.get_event_loop().(say_after('你好', 1))
task2 = asyncio.get_event_loop().(say_after('Hello', 2))
await task1
await task2
asyncio.get_event_loop().run_until_complete(main())
这是因为 Python 中的协程、任务 和 Future 都是可等待对象,故而,凡有 async 处皆可 await ,果然,主流编程语言的最终走向是如此的一致啊,回头想想 .NET 中 Thread 、 ThreadPool 、 Task 的进化历程,是不是有种“天下大势,分久必合”的感觉呢?
requests
好了,当我们对异步 I/O、协程有了一个基本的了解以后,我们就可以考虑结合着 requests 来做一点小小的尝试,我们大多数时候写的 requests 相关的代码,基本上都是博主这里getImage()类似的画风,最多再加上流式传输(Stream) 和 iter_content。为了配合异步 I/O 来使用,我们这里需要定义一个异步的方法getImageAsync(),一起来看下面的代码:
async def getImageAsync(self, url, fileName, retries=5):
try:
print(f'{threading.currentThread().name} -> {url}')
headers = {
'User-Agent': fake_useragent.UserAgent().random,
'Referer': "https://www.nvshens.org"
}
future = asyncio.get_event_loop().run_in_executor(
None,
functools.partial(requests.get, url, headers=headers)
)
response = await future
data = response.content
imgFile = open(fileName, 'wb')
imgFile.write(data)
imgFile.close()
return True
except:
while retries > 0:
retries -= 1
if await self.getImageAsync(url, fileName, retries):
break
else:
continue
接下来,我们还需要定义downloadAsync()方法,这里我们使用了create_task()方法:
async def downloadAsync(self):
count = len(self.urls)
for index in range(0, count):
url = self.urls[index]
fileName = f'{str(index)}.jpg'
await asyncio.get_event_loop().create_task(self.getImageAsync(url, fileName))
此时,我们可以在入口函数中这样调用:
spider = Spider(urls)
loop = asyncio.get_event_loop()
task = loop.create_task(spider.downloadAsync())
loop.run_until_complete(task)
看看结果:
![异步I/O + Requests 实现并行下载]](https://i.loli.net/2021/01/16/mhtcT78dswjgERa.png)
这里,针对本文中提到的各种方法,博主做了一个简单对比:
| 项目 | 时间 |
|---|---|
| Thread | 0:00:01.789790 |
| ThreadPool | 0:00:00.134065 |
| ThreadPoolExecutor | 0:00:06.510224 |
| Process | 0:00:00.100506 |
| ProcessPool | 0:00:11.046871 |
| ProcessPoolExecutor | 0:00:02.226153 |
| AsyncIO | 0:00:04.096083 |
本文小结
本文从线程(池)、进程(池)和异步 I/O 三个方面探讨和尝试了多线程编程在 Python 爬虫领域的简单应用。其实,除了以上这些优化的思路以外,我们还可以借助队列(Queue)这类数据结构来改善现有方案的设计,大家可以注意到我给getImage()方法增加了错误重试的机制,这同样是为了增强爬虫程序的健壮性,而关于这个错误重试机制,考虑通过装饰器来进行改良则又是一个新的努力的方向,所以说,没有 deadline 才能让我们不断地自我改善,而有 deadline 只能让我们赶紧做完赶紧清净。好了,以上就是这篇博客的全部内容啦,最后要送给大家一个福利,本文中援引的爬虫程序已开源,地址是:https://github.com/qinyuanpei/zngirls,感兴趣的朋友可以自己去玩一玩,你懂的哦!



{kind=link}