有人说,“男人至死都是少年”,而这句听起来有一点中二的话,其实是出自一部同样有一点中二的动漫——银魂。我个人的理解是,知世故而不世故。也许,年轻时那些天马行空的想法,就像堂吉诃德大战风车一样荒诞,可依然愿意去怀着这样的梦想去生活。正如罗曼罗兰所言,“世上只有一种英雄主义,就是在认清生活真相之后依然热爱生活”。所以,继《浪客剑心》之后,我再次被一部叫做《鬼灭之刃》的动漫吸引,毕竟男人的快乐往往就是这么朴实无华且枯燥。一个快三十岁的人,如果还能被一部热血少年番吸引,大概可以说明,他身体里的中二少年连同中二少年魂还活着。最早的印象来自朋友圈里的一位二次元“少年”,他和自己儿子站一起,有种浑然天成的协调感,整个人是非常年轻的感觉。所以,大概,男人至死都是少年。
漫画的抓取
鬼滅の刃的漫画早已更完,令我不舍昼夜去追的,实际上是动画版的鬼滅の刃。虽然 B 站上提供中配版本,可一周更新两集的节奏,还是让我追得有一点焦灼(PS:我没有大会员呢),甚至熬着夜提前“刷”了无限列车(PS:见文章末尾小程序码)。其实,鬼滅の刃前期并没有特别吸引人的地方,直到那田蜘蛛山那一话开始渐入佳境,鬼杀队和鬼两个阵营所构成的人物群像开始一点一点的展开。它的表达方式有点接近刺客信条,即反派都是在死亡一刹那间有了自我表达的机会,而玩家/观众都可以了解反派的过去。由于鬼是由人转变而来,所以,在热血和厮杀之外,同样有了一点关乎人性的思考。作为一名“自封”的技术宅,我必须要在追番的时候做点什么,从哪里开始好呢?既然漫画版早已更新完毕,我们要不先抓取漫画下来提前过过瘾?
OK,这里博主找了一个动漫网站,它上面有完整的鬼滅の刃漫画。我意识到从网上抓取漫画的行为是不对的,可这家网站提供的漫画明显是通过扫描获得的,因为正常的漫画都是通过购买杂志的方式获得的。所以,如果经济条件允许的情况下,还是希望大家可以支持正版,这里博主主要还是为了研究技术(逃,无意对这些资源做二次加工或者以任何方式盈利,所以,请大家不要向博主索取任何资源,我对自己的定位永远是一名软件工程师,谁让我无法成为尤小右这样的“美妆”博主呢?这一点希望大家可以理解哈!
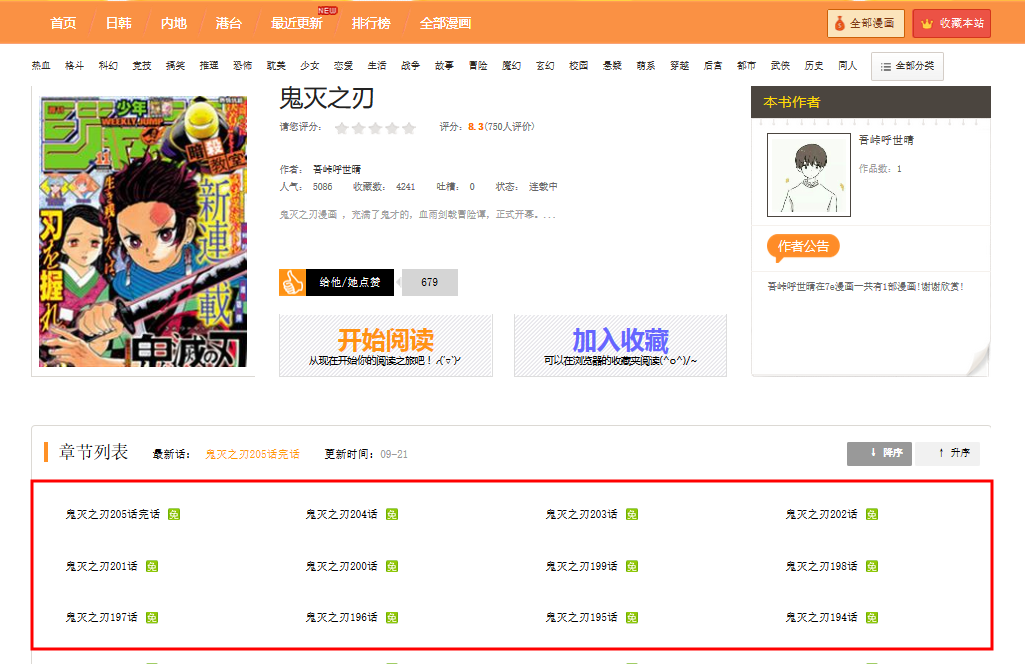
简单分析下动漫网站结构,可以发现,它主要有两种界面,即作品页面和章节页面。作品页面里面会显示所有的章节,而每个章节里会显示所有的图片。所以,我们的思路是,首先,通过作品页面获取所有章节的链接。其次,针对每一个章节,获取总页数后逐页下载图片即可。注意到这个网站有部分内容是通过 JavaScript 动态生成的,所以,requests针对这种情况会有点力不从心。幸好,我们还有Selenium这个神器可以使用,我们一起来看这部分内容如何实现:
import requests
from bs4 import BeautifulSoup
import fake_useragent
import json
import urllib
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os, time
import threading
import threadpool
class DemonSlayer:
def __init__(self, baseUrl):
self.baseUrl = baseUrl
self.session = requests.session()
self.headers = {
'User-Agent': fake_useragent.UserAgent(verify_ssl=False).random
}
# 使用无头浏览器
fireFoxOptions = webdriver.FirefoxOptions()
fireFoxOptions.set_headless()
self.driver = webdriver.Firefox(firefox_options=fireFoxOptions)
# 获取所有章节信息
def getAllChapters(self, opusUrl):
chapters = {}
response = self.session.get(opusUrl, headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.content)
soup = soup.find(name='div', attrs={'class','cy_plist'})
if (soup != None):
for li in soup.ul.children:
chapters[li.a.text] = self.baseUrl + li.a['href']
return chapters
# 获取指定章节信息
def getChapter(self, url):
page = 1
maxPage = self.getPageOfChapter(url)
images = []
while page <= maxPage:
reqUrl = url + '?p={page}'.format(page=page)
self.driver.get(reqUrl)
wait = WebDriverWait(self.driver, 10)
# 等待漫画图片加载完成
wait.until(EC.presence_of_element_located((By.ID, "qTcms_pic")))
html = self.driver.page_source
imgSrc = BeautifulSoup(html).find('img')['src']
# 从网页中提取的图片地址需要做一次解码
realSrc = urllib.parse.unquote(imgSrc.split('?')[1].split('&')[0].split('=')[1])
images.append(realSrc)
page += 1
return images
# 获取指定章节页数
def getPageOfChapter(self, url):
self.driver.get(url)
wait = WebDriverWait(self.driver, 10)
# 等待页数加载完成
wait.until(EC.presence_of_element_located((By.ID, "k_pageSelect")))
html = self.driver.page_source
opts = list(BeautifulSoup(html).find('select').children)
return int(opts[-1]['value'])
# 下载漫画图片
def getImage(self, chapterPath, index, url):
imagePath = os.path.join(chapterPath, str(index) + '.jpg')
with open(imagePath, 'wb') as fp:
response = self.session.get(url)
response.raise_for_status()
fp.write(response.content)
# 公共入口
def run(self, url):
chapters = self.getAllChapters(url)
for chapter, url in chapters.items():
images = spider.getChapter(url)
# 为每一个章节建立文件夹
chapterPath = './download/{chapter}/'.format(chapter=chapter)
if (not os.path.exists(chapterPath)):
os.mkdir(chapterPath)
# 使用多线程下载图片
args = []
for index, url in enumerate(images):
args.append((None,{'chapterPath':chapterPath, 'url':url, 'index':index}))
pool = threadpool.ThreadPool(max(10, len(images)))
requests = threadpool.makeRequests(self.getImage, args)
[pool.putRequest(req) for req in requests]
pool.wait()
if __name__ == '__main__':
spider = DemonSlayer('http://www.7edm.com/')
spider.run('http://www.7edm.com/rexue/guimiezhiren/')
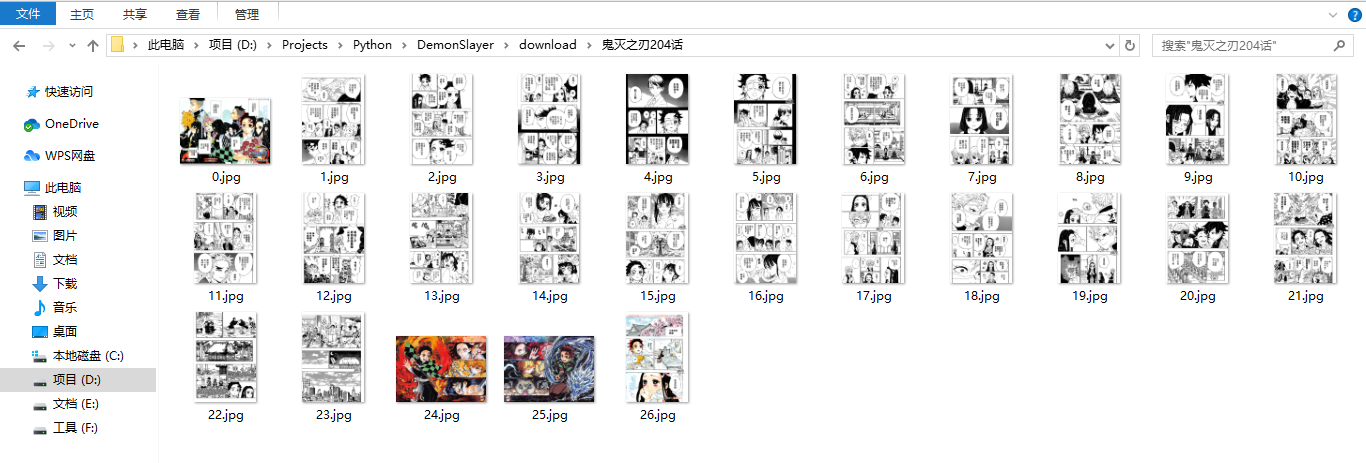
在这里,需要注意的 Firefox 驱动,即GeckoDriver需要提前安装好。同时,确保 Firefox 主程序和驱动程序所在的目录均已配置到环境变量Path中。在有的资料中提到,GeckoDriver需要和 Firefox 主程序在同一个目录底下,不过经过博主的验证,需要放在 Python 主程序的根目录底下。这个驱动程序可以从这里下载:https://github.com/mozilla/geckodriver/releases/。当然,如果你更喜欢使用 Chrome,只需要安装 Chrome 的驱动即可,完全遵从个人意愿即可。在运行这个脚本后,我们就可以获得完整的鬼滅の刃漫画:
在 Kindle 上“追”番
好了,到现在为止,我们实现了本文的第一个小目标,即漫画的抓取。那么,在抓取到漫画以后,我们可以做什么呢?可能会有读者朋友忍不住吐槽,“废话,漫画除了看还能干什么”。话虽如此,可这样一张张图片显然不能让我们方便地看漫画啊!早就听说在 Kindle 上可以看漫画,可一直没有真正尝试过,可能是因为我还不够中二吧!所以,接下来,我们来考虑将这些图片制作成电子书。Kindle 本身支持像 mobi、docx/doc、pdf 等等这样的格式,这里我们选择一种最简单的方式,利用PyMuPDF这个库来生成 PDF 文件,一起来看具体的代码实现:
def createPdf(self, chapterPath):
doc = fitz.open()
pdfPath = './ebook/' + os.path.basename(chapterPath) + '.pdf'
for image in sorted(os.listdir(chapterPath)):
filePath = os.path.join(chapterPath, image)
# 为每一张图片创建一个单独的PDF
imgdoc = fitz.open(filePath)
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
# 插入当前页
doc.insertPDF(imgpdf) # 将当前页插
# 保存PDF
doc.save(pdfPath)
经常使用 Kindle 的朋友,一定对它的邮箱传书功能非常熟悉,这意味着我们此基础上,将生成的 PDF 文件直接推送到 Kindle 上,而在 Python 中发送邮件则是非常简单的,这一点我们不再赘述,那到底能不能实现我们这个想法呢?显然可以,我们一起来看看效果:

我们知道 Kindle 对 PDF 的支持是有点差的,主要体现在它不支持重排,在我们这个例子中,我们可以发现图片是横屏显示的,或许是因为我的 Kindle 屏幕太小,或许是因为我没有一个 Pad,或许是因为图片尺寸无法适配,总之,它给人的体验是有点不舒服。博主注意到,Kindle 官方提供了一个漫画书制作软件Kindle Comic Creator,它可以生成 mobi 格式的电子书。作为对比,我们来看一下它在 Kindle 上的显示效果:

果然还是 Kindle 自家的格式更好一点,有同样需求的小伙伴们,不妨试一试这个软件!现在,我们终于可以在 Kindle 上“刷”漫画了,快乐肥宅水,安排!
让漫画“动”起来
一旦看过动画以后,再去看漫画,总觉得没那味儿,果然,“没声音再好的戏都出不来”,除了想念片头 OP 以外,更想念声优们绘声绘色的配音。有人说,博主你可以戴上耳机,放着片头 OP,刷着漫画啊!哎,你可真是小机灵鬼!可作为一名技术宅,我们当然要追求手工耿的无用之美,不就是想看有声音有画面的视频吗?安排!所以,下面我们来通过这些图片生成视频,这里主要用到opencv-python和MoviePy两个库,前者可以通过OpenCV合成视频,而后者则可以对视频进行剪辑,例如加入片头、片尾、背景音乐等等。
def createVideo(self, chapterPath):
# OpenCV创建视频
videoFps = 40
videoSize = (655, 948)
videoPath = './video/' + os.path.basename(chapterPath) + '.avi'
videoWriter = cv2.VideoWriter(videoPath,
cv2.VideoWriter_fourcc('I', '4', '2', '0'),
videoFps,
videoSize
)
for image in sorted(os.listdir(chapterPath)):
# 读取每张图片,并重复写40帧
image_path = chapterPath + '/' + image
bg = cv2.imread('bg.jpg')
max_h, max_w, _ = bg.shape
img = cv2.imdecode(np.fromfile(image_path ,dtype=np.uint8),-1)
img_h, img_w, _ = img.shape
scale = max_h / img_h
new_w = int(img_w * scale)
new_h = int(img_h * scale)
img = cv2.resize(img ,(new_w ,new_h))
offsetX = int((max_w - new_w) / 2)
offsetY = int((max_h - new_h) / 2)
bg[offsetY:offsetY + img.shape[0], offsetX:offsetX + img.shape[1]] = img
for i in range(0, videoFps):
videoWriter.write(bg)
videoWriter.release()
# 为当前视频加入片头/尾
videoClip = VideoFileClip(videoPath)
titleClip = VideoFileClip('./title.mp4')
finalClip = concatenate_videoclips([
titleClip.subclip(0, 12),
videoClip,
titleClip.subclip(70, 72),
titleClip.subclip(85, 89),
])
# 为当前视频增加BGM
audioClip = AudioFileClip('BGM.mp3').subclip(0, finalClip.duration)
finalClip.audio = audioClip
finalClip.write_videofile('output.avi', codec='libvpx')
在使用 OpenCV 合成视频这一步,和大多数第一次接触 OpenCV 的人一样,博主在这里遇到了很多的问题,例如,最典型的问题有:OpenCV 合成的视频无法打开、OpenCV 无法使用中文路径、OpenCV 合成的视频长度较短等等。所以,在这里我简单做一下说明,首先,检查下视频画面的宽/高是否与图片的宽/高一致。其次,选择合适的编码器,在使用 OpenCV 保存视频的时候,需要综合考虑 FOURCC 和视频格式两个因素,前提是当前系统已经安装了对应的编码器,在 Windows 下推荐大家使用 DIVX。最后,关于中文路径,大部分的解决方案都是引入 NumPy,代码片段如下:
# 读取
cv_img = cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), -1)
# 写入
cv2.imencode('.jpg', cv_img)[1].tofile(file_path)
经过博客的验证,这个方案的确可以解决,不过同样有缺点,imdecode()方法读取的是 RGB,而 OpenCV 需要的则是 BGR,需要做一次转换,而转换则意味着会损失图片信息。所以,如果在意生成的视频质量的话,最好还是放在英文的路径下面。
好了,现在来看看效果,当片头 OP 响起的时候,有没有觉得,那种熟悉感觉的又回来了(PS:此处可与飞驰人生梦幻联动),虽然没有配音,还是有一点视频的样子的。我经常在 B 站看到那种,黑色背景 + 白色文字的视频,虽然没有特别复杂的转场动画,可搭配上小爱同学或者 Siri 同学的声音后,居然感觉还不错。知乎上同样提供了文章转视频的功能,所以,我在想这是不是可以作为一个思路,作为一个努力寻找流量方向的技术博客,我好累啊(逃……
这个思路,其实还可以用来制作表情包,作为一部拥有大量“名场面”的动漫作品,它为博主带来了不少的“燃点”和“笑点”,下面例举一二供大家欣赏:


对于静态表情包,通常只需要用到PIL库就可以完成,下面是富冈义勇迫害时间(逃:
image = Image.open('鬼灭之刃-09.jpg')
width, height = image.size
textFont = ImageFont.truetype('Deng.ttf', 18)
imageDraw = ImageDraw.Draw(image)
textPos = (width * 0.34, height * 0.8)
text = '我感觉我没有被讨厌'
imageDraw.text(textPos, text, fill='#fff', font=textFont, align='left')
image.save('富岗义勇表情包.jpg','jpeg')
如此,我们就可以得到下面的名场面:


而对于动态表情包,我们可以考虑使用imageio和MoviePy,它们都可以从图片或者视频来生成 GIF,一起来看下面的例子:
def createGif(self, framesPath, gifPath, duration=0.5):
# 读取图片
frames = []
for image_name in sorted(os.listdir(framesPath)):
image_path = os.path.join(framesPath, image_name)
frames.append(imageio.imread(image_path))
# 保存GIF
imageio.mimsave(gifPath, frames, 'GIF', duration=duration)
# 读取一组图片并生成GIF
handler = ImageHandler()
handler.createGif('./frames', '登峰造极.gif')
这里唯一需要注意的就是,imageio依赖于Pillow:

如果使用MoviePy来生成 GIF,则可以通过VideoFileClip或者ImageSequenceClip来分别从视频和图片创建 GIF。同样,这里有一个简单的例子:
# 从一组图片并生成GIF和视频
fps = 0.25
sequence = ImageSequenceClip('./frames', fps)
sequence.write_gif('登峰造极.gif')
sequence.write_videofile('登峰造极.avi', codec='libvpx')
# 从视频中截取指定片段生成GIF
videoClip = VideoFileClip('input.mp4')
videoClip = videoClip.subclip(33, 45)
videoClip.write_gif('霹雳一闪.gif')
在这里,我选取的是,我个人非常喜欢的角色——我妻善逸的名场面“霹雳一闪”:

至此,我们“绞尽脑汁”、“千方百计”、“搜肠刮肚”地想到了各种“刷”鬼滅の刃的方法,总算为这份中二信仰充了值,大家还有什么好的点子吗?欢迎大家在评论区留言、点赞、收藏、一键三连,我仿佛嗅到了 Bilibili 的味道(逃……
本文小结
坦白来讲,这篇博客的确有蹭热度的嫌疑,不过以鬼灭之刃在日本妇孺皆知的火热程度,足以令人们在这颇感失落的疫情背景下为之一振,甚至于连日本首相菅义伟在国会质询时,都引用了“全集中呼吸”这一经典台词。“纵有疾风起,人生不言弃”,热血少年漫告诉我们,在面对一个又一个的挫折的时候,不要沉溺于昨天的回忆,去勇敢地接受现实,直面惨淡的人生,这又何尝不是我们面对生活的态度呢?不管是旷日持久的疫情,还是似曾相识的失业,人生的道路上还有数不尽的“魑魅魍魉”呢!希望你活得像炭治郎一样乐观善良,像我妻善逸一样勇敢坚毅,像伊之助一样“猪”突猛进。如果这篇博客里所介绍的“追”动漫的方式,能让大家感到快乐和有趣的话,欢迎大家在评论区留言、点赞、收藏、一键三连。以上,这就是我,作为一个技术宅,在“追”动漫方面所做出的努力。少年,想加入鬼杀队吗?


