前几天,有位朋友问我,你平时都是怎么去排查一个程序的性能问题的啊。不要误会,这位朋友不是我啦,因为我真的有这样一位叫做 Toby 的朋友。说到性能问题,可能大家立马会想到类似并发数、吞吐量、响应时间、QPS、TPS等等这些指标,这些指标的确可以反映出一个系统性能的好坏。可随着我们的系统结构变得越来越复杂,要找到这样一个性能的“损耗点”,同样会变得越来越困难。在不同的人的眼中,对于性能好坏的评判标准是不一样的,譬如在前端眼中,页面打开速度的快慢代表着性能的好坏;而在后端眼中,并发数、吞吐量和响应时间代表着性能的好坏;而在 DBA 眼中,一条 SQL 语句的执行效率代表着性能的好坏。更不用说,现实世界中的程序要在硬件、网络的世界里来回穿梭了,所以,从 80%的功能堆积到 100%,是件非常容易的事情;而从 80%的性能优化到 85%,则不是件非常轻松的事情。想清楚这一点非常简单,因为我们的系统从来都不是简单的1 + 1 = 2。此时,我们需要一个性能分析工具,而今天给大家分享的是 JetBrains 出品的 dotTrace 。
快速开始(Quick Start)
安装软件的过程此处不表,这里建议大家同时安装 dotTrace 和 dotMemery。因为这都是 JetBrains 全家桶中的软件,安装的时候选一下就可以了,可谓是举手之劳。安装好以后的界面是这样的,可以注意到,它可以对进程中的 .NET 应用、本机的 .NET 应用以及远程的 .NET 应用进行检测,因为这里写一个 .NET Core 应用来作为演示,所以,我们选择 Profile Local App:

在这里,我们准备了一个简单的控制台程序:
public class Program
{
static void Main(string[] args)
{
CPUHack();
MemeryHack();
}
public static void MemeryHack() {
Console.ReadLine();
var bytes = GC.GetTotalAllocatedBytes();
Console.WriteLine($"AllocatedBytes: { bytes } bytes");
var list = new List<byte[]>();
try
{
while (true) {
list.Add(new byte[85000]);
}
} catch (OutOfMemoryException) {
Console.WriteLine(nameof(OutOfMemoryException));
Console.WriteLine(list.Count);
bytes = GC.GetTotalAllocatedBytes();
Console.WriteLine($"AllocatedBytes: { bytes } bytes");
}
Console.ReadLine();
}
public static void CPUHack() {
Parallel.For(0, Environment.ProcessorCount,
new ParallelOptions() {
MaxDegreeOfParallelism = Environment.ProcessorCount
},
i => {
});
}
}
其中,CPUHack()方法来自:打爆你的 CPU; MemeryHack()方法来自:通过代码实现 OutOfMemory。顾名思义,我们将利用这两个方法来分别测试 dotTrace 和 dotMemery。
dotTrace 目前支持以下平台:.NET、.NET Core、WPF、UWP(Universal Windows Platform)、ASP.NET、Windows 服务、WCF、Mono 和 Unity。可以注意到它有四种监测方式,即 Sampling、Tracing、Line by Line 以及 Timeline。按照界面上的描述,Sampling 适用于大多数场景下调用时间的精确测量、Tracing 适用于算法复杂度分析场景下调用次数的精确测量、Line by Line 适用于更高级别的使用场景,Timeline 适用于含多线程在内的数据处理的精确测量。所以,我们这里选择好一个可执行文件,然后选择 Sampling,再点击 “Run”:
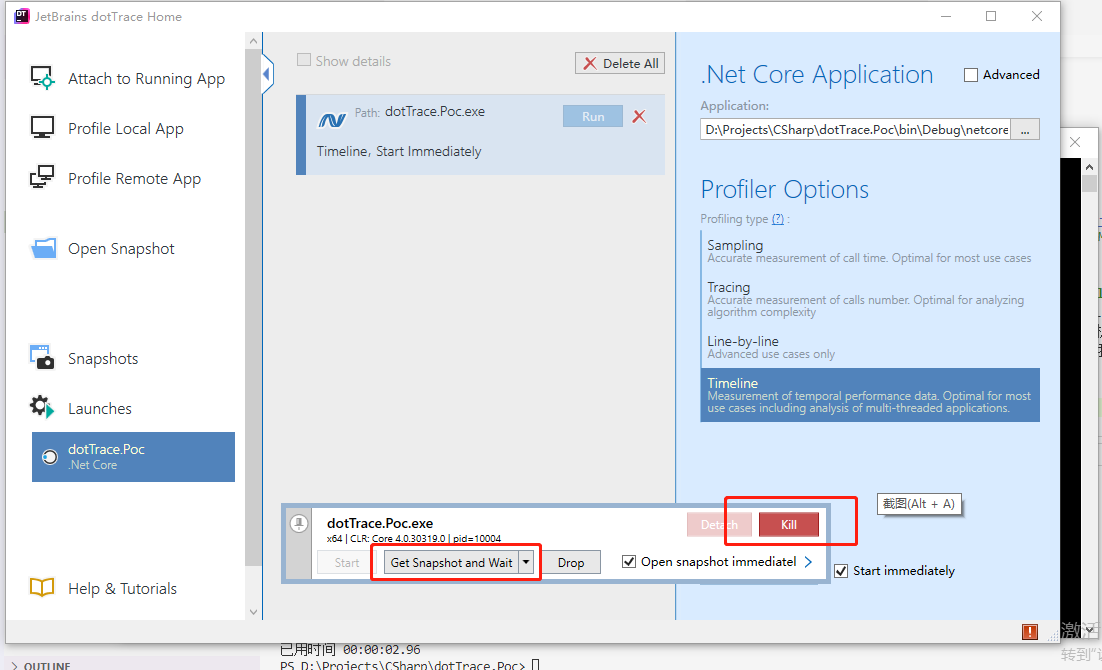
此时,我们会看到对应程序的的工具栏,我们可以点击 “Get Snapshot and Wait” 进行采样,每次采样会生成一个快照,默认情况下会自动打开生成的快照。我们还可以点击 “Start” 重新进行采样,直至采集到满意的样本为止,而在完成采样后,则可以点击 “Kill” 结束采样。下面来看看生成的快照:
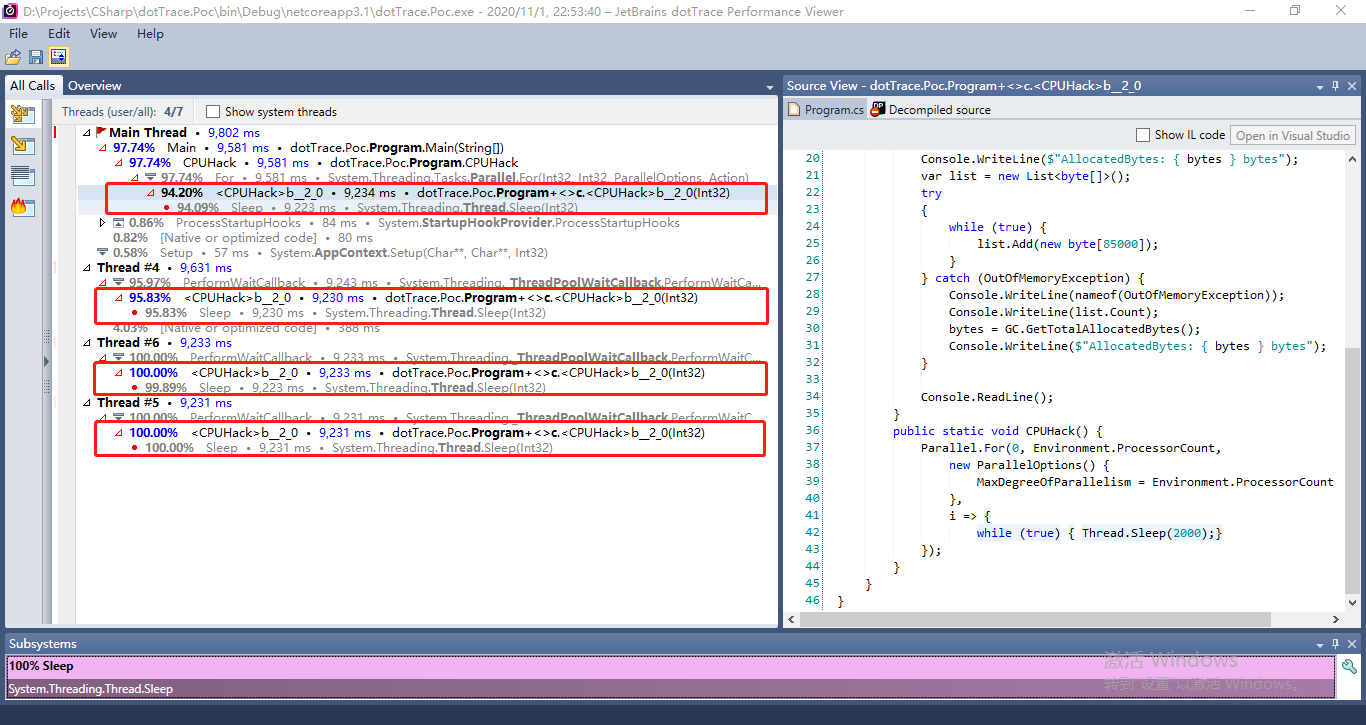
通过这两图,我们可以非常清晰的看到,最耗时的正是我们这里的CPUHack()方法,并且这里一共有四个线程,这是因为博主的计算机使用的是一款 4 核的 i3 处理器,并且在dotTrace中可以直接看到相关的代码片段,当然,这一切的前提是你没有对应用程序做过混淆处理,这样,我们就完成了一个简单的性能分析。类似地,我们启动dotMemery。此时,可以得到下面的结果:
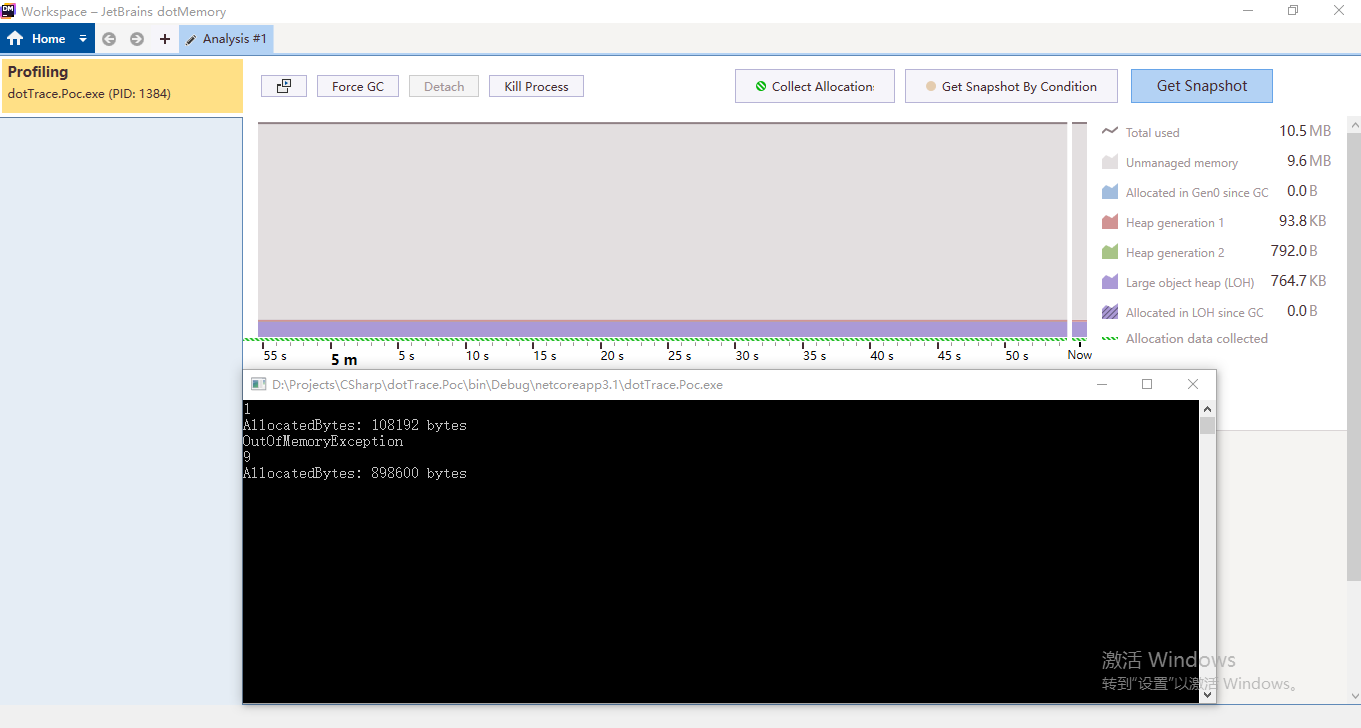
这里,我们通过<YourApp>.runtimeconfig.json文件,设定了 GC 堆的最大值是 1M,而每次向列表中添加超过 85K 的 byte 数组时,当前对象会被分配到大对象堆上。通过这张图我们可以很清楚的看到,整个曲线中蓝色区域的 LOH 占了绝对的比例,换言之,几乎所有的内存都是分配到大对象堆(LOH)上的。此外,有些小对象从 0 代升到了 1 代,在这个例子中,由于可分配的内存不足,最终引发了OutOfMemoryException。而这和我们看到的结果是相符合的:
{
"runtimeOptions": {
"tfm": "netcoreapp3.1",
"framework": {
"name": "Microsoft.NETCore.App",
"version": "3.1.0"
},
"configProperties": {
"System.GC.HeapHardLimit": 1048576
}
}
}
从 Dump 文件进行分析
到此为止,关于 dotTrace 和 dotMemery 的使用就基本上讲解完啦!可能这时候有些朋友会产生疑问,如果性能问题发生在生产环境怎么办啊。不错,这里我们调试的都是本地的程序,生产环境是没有机会让你这样去搞的。此时,我们可以借助内存转储文件(Dump)文件,它是进程的内存镜像,可以把程序的执行状态通过调试器保存在 Dump 文件中,试想一下,如果程序在前一秒崩溃了,而你在这一瞬间获得了当时程序的状态信息,相当于拿到了“故障”遗留在现场的“罪证”。在 Windows 系统中创建 Dump 文件是非常简单的,通过任务管理器->创建转储文件即可完成,我们继续使用上面提到的例子:
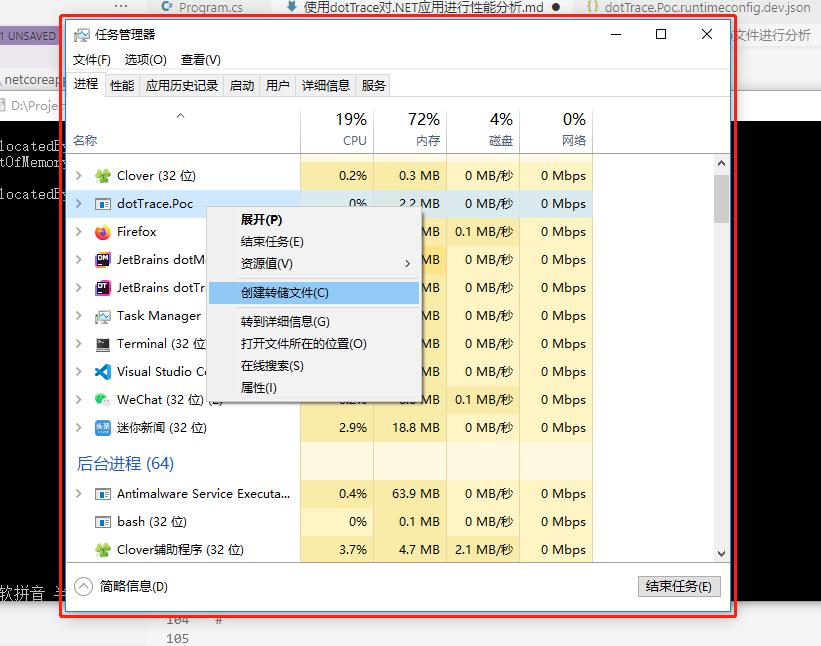
其实,拿到 Dump 文件以后,分析它的工具非常多,比如常见的 WinDBG、DebugDiag 等等,这里我们可以直接使用 dotMemery ,因为它本身就支持 Dump 文件的导入,相比前面两种在使用上要更加友好一点。此时,导入这个 Dump 文件,我们就可以获得下面的结果:


这和我们前面分析出的结论是一致的,即,几乎所有的内存都是分配到大对象堆(LOH)上的。除此以外,针对.NET Core,官方提供了
dotnet-dump和dotnet-gcdump两个命令行工具,可以通过下面的命令安装:
dotnet tool install -g dotnet-dump
dotnet tool install -g dotnet-gcdump
这两个命令同样可以对内存进行分析,关于更多的.NET Core 的诊断教程,请参考:https://docs.microsoft.com/zh-cn/dotnet/core/diagnostics/event-counter-perf,这些细节都是针对.NET Core 的,可能不具有普适性,感兴趣的朋友可以自行前去了解。和大多数JetBrains的应用一样,这些程序都有 Visual Studio 的扩展程序,可以直接集成到 Visual Studio 中,这个同样看个人喜好,不再详细讲解。
本文小结
结合一个简单的示例程序,本文简单地介绍了来自 JetBrains 的两款软件 dotTrace 和 dotMemery 的基本使用,以及如何通过内存转储文件(Dump)对生产环境中的内存进行诊断。在以往的关于程序性能优化的经历中,我个人还使用过 ANTS-Performance-Profiler 这个软件,但体验上感觉还是 dotTrace 和 dotMemery 稍微好用一点,而对于更一般的代码角度的性能分析,我推荐一个轻量级的项目MiniProfiler,性能优化不能靠猜,可是从初中就开始学的“控制变量法”未尝不是一个不错的思路。刷 LeetCode 的这段时间,一个最大的感悟就是,程序的性能,真的是一点一点的优化出来的,就拿最简单的排序来说,你真的要在上面提交很多次,才能渐渐地明白为什么说有些排序算法是“不稳定”的。也许,现在硬件水平越来越好,我们不必像前辈们一样“锱铢必较”,可这一切其实很都公平,你写代码的时候有多浪费,你玩游戏的时候就有多心疼,这里要特别表扬育碧对叛变这一作的优化。好了,这就是这篇博客的内容啦,谢谢大家,晚安!
参考链接
- https://www.jetbrains.com/zh-cn/profiler/
- https://www.jetbrains.com/zh-cn/dotmemory
- https://docs.microsoft.com/zh-cn/dotnet/core/diagnostics/debug-linux-dumps
- https://docs.microsoft.com/zh-cn/dotnet/core/diagnostics/debug-memory-leak
- https://docs.microsoft.com/zh-cn/dotnet/core/diagnostics/debug-highcpu?tabs=windows


