各位朋友大家好,我是秦元培,欢迎大家关注我的博客,我的博客地址是http://qinyuanpei.com。在这个系列文章的第一篇中,我们着重认识和了解了 HTTP 协议,并在此基础上实现了一个可交互的 Web 服务器,即当客户端访问该服务器的时候,服务器能够返回并输出一个简单的“Hello World”。现在这个服务器看起来非常简陋,为此我们需要在这个基础上继续开展工作。今天我们希望为这个服务器增加主页支持,即当我们访问这个服务器的时候,它可以向我们展示一个定制化的服务器主页。通常情况下网站的主页被定义为 index.html,而在动态网站技术中它可以被定义为 index.php。了解这些将有助于帮助我们认识 Web 技术的实质,为了方便我们这里的研究,我们以最简单的静态页面为例。
大意失荆州
首先我们可以认识到的一点是,网站主页是一个网站默认展示给访问者的页面,所以对服务器而言,它需要知道两件事情,第一客户端当前请求的这个页面是不是主页,第二服务端应该返回什么内容给客户端。对这两个问题,我们在目前设计的这个 Web 服务器中都可以找到答案的。因为 HTTP 协议中默认的请求方法是 GET,所以根据 HttpRequest 的实例我们可以非常容易的知道,当前请求的方法类型以及请求地址。我们来看一个简单的客户端请求报文:
GET / HTTP/1.1
Accept: text/html, application/xhtml+xml, image/jxr, */*
Accept-Language: zh-Hans-CN,zh-Hans;q=0.5
User-Agent: Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2486.0 Safari/537.36 Edge/13.10586
Accept-Encoding: gzip, deflate
Host: localhost:4040
Connection: Keep-Alive
我们在这里可以非常清晰地看到,客户端当前发出的请求是 GET 类型,而其请求的地址是"/",这表示请求页面为主页,而实际上我们将 Host 字段和这个地址组合起来,就能得到一个完整的地址,这正是我们在 HTML 结构中编写超链接的时候使用相对地址的原因。好了,在明白了这样两件事情具体的运作机理以后,下面我们来继续编写相关逻辑来实现如何向访问者展示一个网站主页。
public override void OnGet(HttpRequest request)
{
//判断请求类型和请求页面
if (request.Method == "GET" && request.URL == "/")
{
//构造响应报文
HttpResponse response;
//判断主页文件是否存在,如存在则读取主页文件否则返回404
if (!File.Exists(ServerRoot + "index.html")){
response = new HttpResponse("<html><body><h1>404 - Not Found</h1></body></html>", Encoding.UTF8);
response.StatusCode = "404";
response.Content_Type = "text/html";
response.Server = "ExampleServer";
} else {
response = new HttpResponse(File.ReadAllBytes(ServerRoot + "index.html"), Encoding.UTF8);
response.StatusCode = "200";
response.Content_Type = "text/html";
response.Server = "ExampleServer";
}
//发送响应
ProcessResponse(request.Handler, response);
}
}
可以注意到在这里我们首先根据请求方法和请求地址来判断当前客户端是否在请求主页页面,然后我们判断在服务器目录下是否存在 index.html 文件,如果该文件存在就读取文件并返回给客户端,否则我们将返回给客户端一个 404 的状态,熟悉 Web 开发的朋友应该会知道这个状态码表示的是无法找到请求资源,类似地我们还可以想到的状态码有 200、501 等等,通常来讲,这些状态码的定义是这样的:
- 1XX:指示信息-表示请求已接收,继续处理。
- 2XX:成功-表示请求已被成功接受、理解和处理。
- 3XX: 重定向-表示完成请求需要更进一步的操作。
- 4XX:客户端错误-表示请求错误或者无法实现。
- 5XX:服务端错误-表示服务器未提供正确的响应。
具体来讲,常见的状态代码描述如下:
| 状态码 | 状态描述 |
|---|---|
| 200 OK | 客户端请求成功 |
| 400 Bad Request | 客户端请求错误且不能被服务器所理解 |
| 401 Unauthorized | 请求未经授权需要使用 WWW-Authenticate 报头域 |
| 403 Forbidden | 服务器收到请求但拒绝提供服务 |
| 404 Not Found | 请求资源不存在 |
| 500 Internal Server Error | 服务器发生不可预期的错误 |
| 503 Server Unavailable | 服务器当前不能处理客户端的请求 |
为了简化需求,我们这里假设服务器目录下只有一个主页文件 index.html,实际上像 IIS、Apache 等大型的服务器软件都是支持多个主页文件的,而且同时支持静态页面和动态页面,所以这里就涉及到一个优先级的问题,无论是在 Apache 还是 IIS 中我们可以找到对主页优先级设置的选项。所谓优先级,其实就是对这些主页文件重要性的一种排序,在实际设计的过程中,会优先读取优先级较高的主页文件,如该文件不存在则退而求其次,以此类推。在读取主页文件的时候,我们需要注意的一点是编码类型,因为无论是客户端还是服务端在其各自的头部信息里都声明了它可以接受的编码类型,所以服务器端在响应请求的时候应该注意和客户端保持一致,这样可以避免“鸡同鸭讲”问题的发生,进而提高沟通效率。我们这里在说技术,可是人何尝不是这样啊,我感觉我们生活和工作中 90%的时间都被用来沟通了,可是这恰恰说明了沟通的重要性啊。好了,下面我们来测试下我们编写的主页:
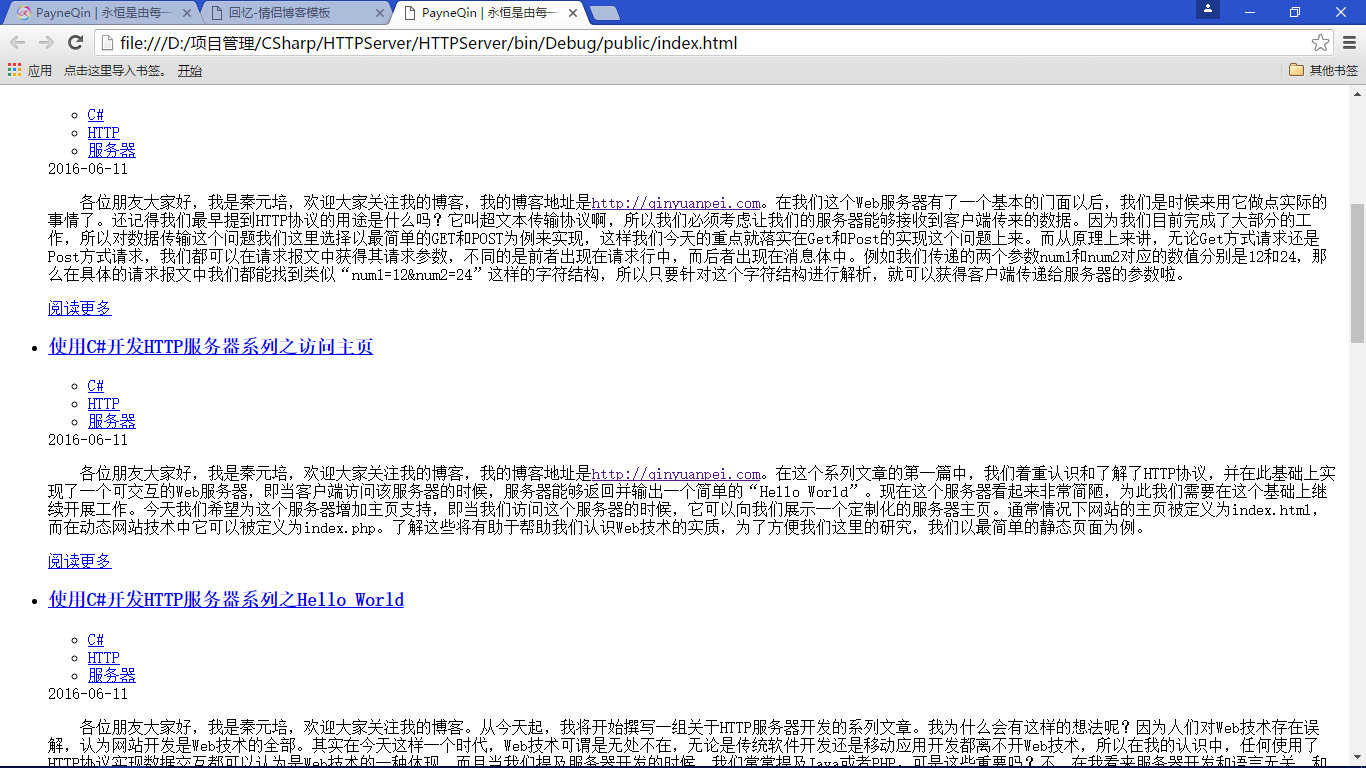
龙潜在渊
咦?这个页面显示的结果怎么和我们期望的不一样啊,看起来这是一个因为样式丢失而引发的错误啊,不仅如此我们发现页面中的图片同样丢失了。首先我们检查下静态页面是否有问题,这个怎么可能嘛?因为这是博主采用 Hexo 生成的静态页面,所以排除页面本身的问题后,我们不得不开始重新思考我们的设计。我们静下心来思考这样一个问题:在浏览器加载一个页面的过程中难道只有静态页面和服务器发生交互吗?这显然不是啊,因为傻子都知道一个网页最起码有 HTML、CSS 和 JavaScript 三部分组成,所以我们决定在 Chrome 中仔细看看浏览器在加载网页的过程中都发生了什么。按下"F12"打开开发者工具对网页进行监听:
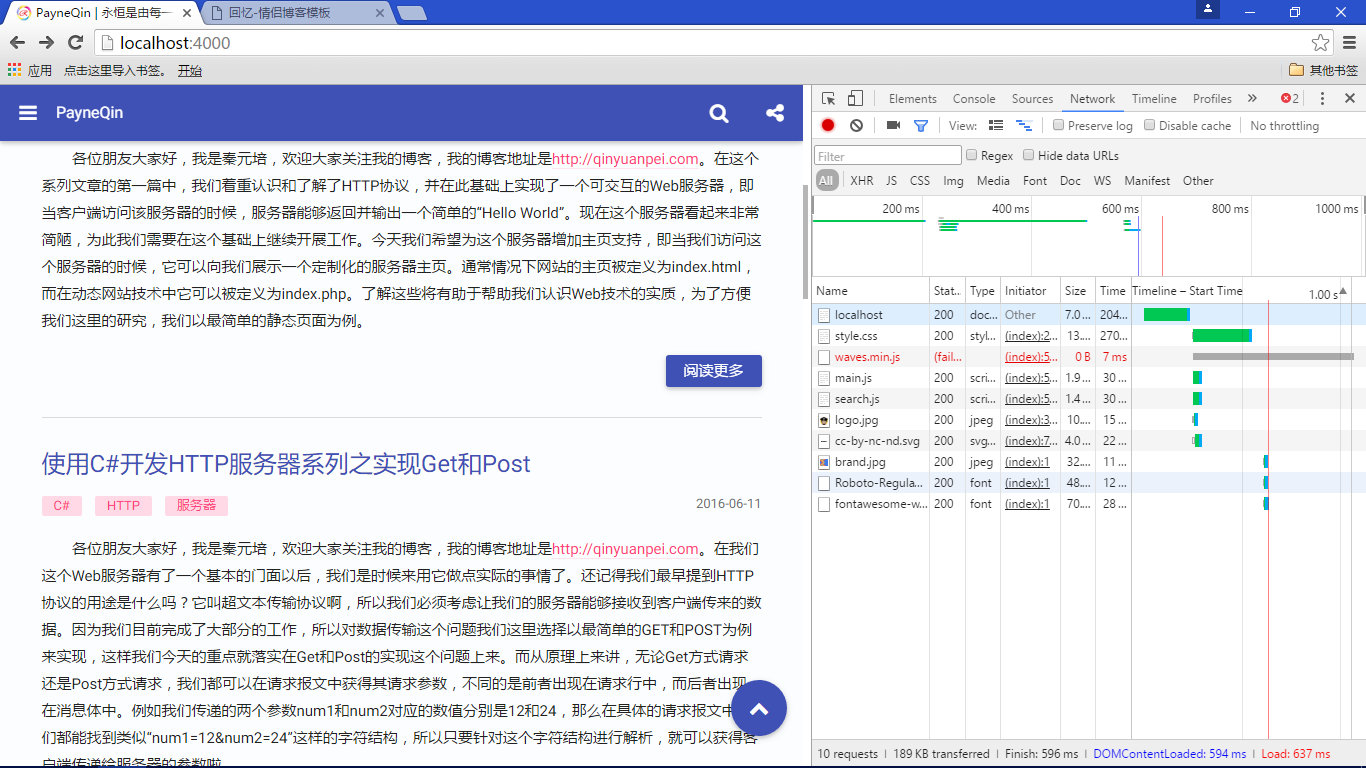
WTF!感觉在这里懵逼了是不是?你没有想到服务器在这里会响应如此多的请求吧?所以我们自作聪明地认为只要响应静态页面的请求就好了,这完全就是在作死啊!这里我的理解是这样的,对页面来讲服务器在读取它以后会返回给客户端,所以对客户端而言这部分响应是完全可见的,而页面中关联的 CSS 样式和 JavaScript 脚本则可能是通过浏览器缓存下载到本地,然后再根据相对路径引用并应用到整个页面中来的,而为了区分这些不同类型的资源,我们需要在响应报文中的 Content-Type 字段中指明内容的类型,所以现在我们就清楚了,首先在请求页面的时候存在大量关联资源,这些资源必须通过响应报文反馈给客户端,其次这些资源由不同的类型具体体现在响应报文的 Content-Type 字段中。因此,我们在第一段代码的基础上进行修改和完善,最终编写出了下面的代码:
public override void OnGet(HttpRequest request)
{
if (request.Method == "GET")
{
///获取客户端请求地址
///链接形式1:"http://localhost:4050/assets/styles/style.css"表示访问指定文件资源,
///此时读取服务器目录下的/assets/styles/style.css文件。
///链接形式2:"http://localhost:4050/assets/styles/"表示访问指定页面资源,
///此时读取服务器目录下的/assets/styles/style.index文件。
//当文件不存在时应返回404状态码
string requestURL = request.URL;
requestURL = requestURL.Replace("/", @"\").Replace("\\..", "");
//判断地址中是否存在扩展名
string extension = Path.GetExtension(requestURL);
//根据有无扩展名按照两种不同链接进行处
string requestFile = string.Empty;
if (extension != "") {
requestFile = ServerRoot + requestURL;
} else {
requestFile = ServerRoot + requestURL + "index.html";
}
//构造HTTP响应
HttpResponse response = ResponseWithFile(requestFile);
//发送响应
ProcessResponse(request.Handler, response);
}
}
注意到我在代码中写了两种不同形式的链接的分析:
链接形式 1: “http://localhost:4050/assets/styles/style.css” 表示访问指定文件资源,此时读取服务器目录下的 /assets/styles/style.css 文件。
链接形式 2: “http://localhost:4050/assets/styles/” 表示访问指定页面资源,此时读取服务器目录下的 /assets/styles/style.index 文件。
首先我们判断这两种形式是根据扩展名来判断的,这样我们可以获得一个指向目标文件的地址 requestFile。这里提供一个辅助方法 ResponseWithFile,这是一个从文件中构造响应报文的方法,其返回类型是一个 HttpResponse,当文件不存在时将返回给客户端 404 的错误代码,我们一起来看它具体如何实现:
/// <summary>
/// 使用文件来提供HTTP响应
/// </summary>
/// <param name="fileName">文件名</param>
private HttpResponse ResponseWithFile(string fileName)
{
//准备HTTP响应报文
HttpResponse response;
//获取文件扩展名以判断内容类型
string extension = Path.GetExtension(fileName);
//获取当前内容类型
string contentType = GetContentType(extension);
//如果文件不存在则返回404否则读取文件内容
if (!File.Exists(fileName)){
response = new HttpResponse("<html><body><h1>404 - Not Found</h1></body></html>", Encoding.UTF8);
response.StatusCode = "404";
response.Content_Type = "text/html";
response.Server = "ExampleServer";
} else {
response = new HttpResponse(File.ReadAllBytes(fileName), Encoding.UTF8);
response.StatusCode = "200";
response.Content_Type = contentType;
response.Server = "ExampleServer";
}
/返回数据
return response;
}
同样的,因为在响应报文中我们需要指明资源的类型,所以这里使用一个叫做 GetContentType 的辅助方法,该方法定义如下,这里仅仅选择了常见的 Content-Type 类型来实现,有兴趣的朋友可以自行了解更多的内容并在此基础上进行扩展:
/// <summary>
/// 根据文件扩展名获取内容类型
/// </summary>
/// <param name="extension">文件扩展名</param>
/// <returns></returns>
protected string GetContentType(string extension)
{
string reval = string.Empty;
if (string.IsNullOrEmpty(extension))
return null;
switch (extension)
{
case ".htm":
reval = "text/html";
break;
case ".html":
reval = "text/html";
break;
case ".txt":
reval = "text/plain";
break;
case ".css":
reval = "text/css";
break;
case ".png":
reval = "image/png";
break;
case ".gif":
reval = "image/gif";
break;
case ".jpg":
reval = "image/jpg";
break;
case ".jpeg":
reval = "image/jgeg";
break;
case ".zip":
reval = "application/zip";
break;
}
return reval;
}
风雨过后终见彩虹
好啦,到目前为止,关于静态 Web 服务器的编写我们基本上告一段落啦!其实这篇文章写的不是特别顺利,因为我几乎是在不断否认自我的情况下,一边调试一边写这篇文章的。整篇文章总结下来其实就两个点,第一,Web 服务器在加载一个页面的时候会发起无数个请求报文,除了页面相关的请求报文以外大部分都是和资源相关的请求,所以 HTML 页面的优化实际上就是从资源加载这个地方入手的。第二,不同的资源有不同的类型,具体表现在响应报文的 Content-Type 字段上,构造正确的 Content-Type 能让客户端了解到这是一个什么资源。好了,现在我们可以气定神闲的验证我们的劳动成果啦,这里我以我本地的 Hexo 生成的静态博客为例演示我的 Web 服务器,假设我的博客是存放在"D:\Hexo\public"这个路径下,所以我可以直接在 Web 服务器中设置我的服务器目录:
ExampleServer server = new ExampleServer("127.0.0.1",4050);
server.SetServerRoot("D:\\Hexo\\public");
server.Start();
现在打开浏览器就可以看到:
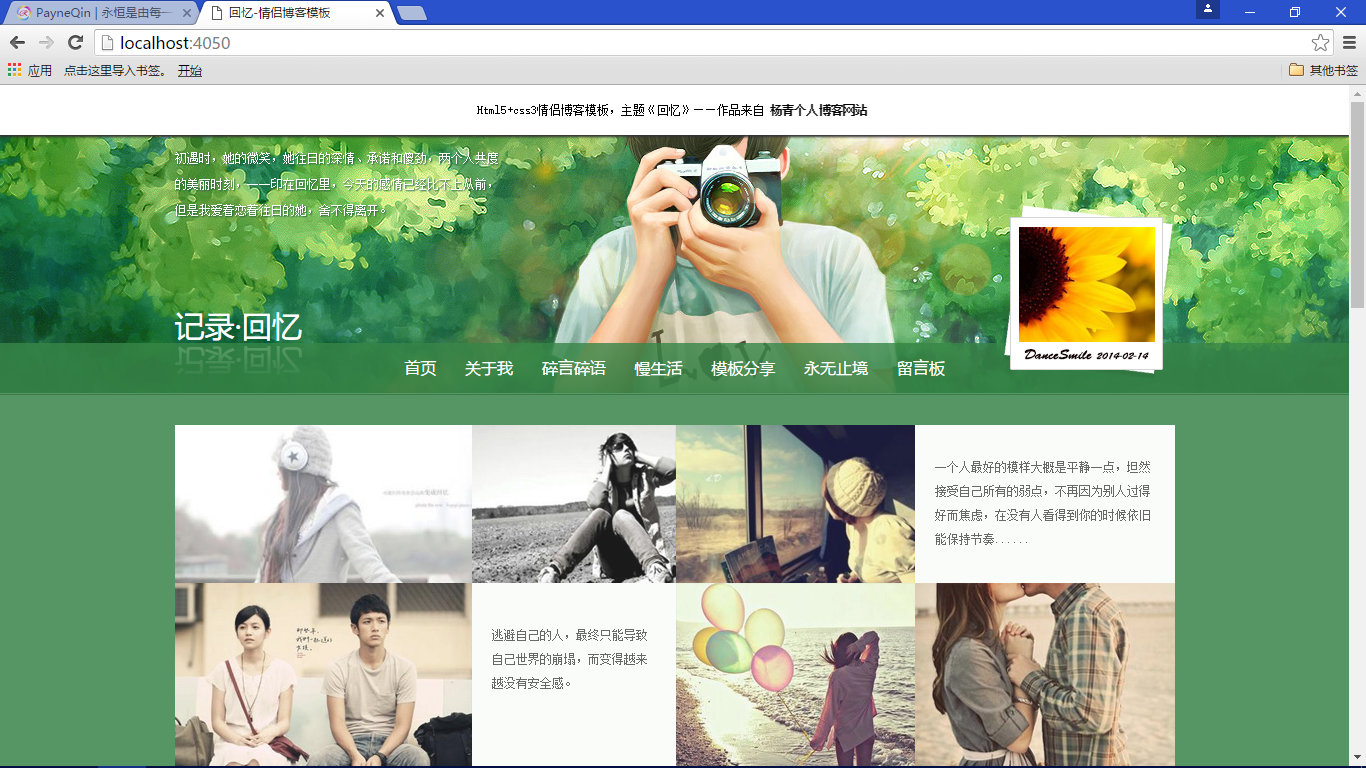
如此激动人心的时候,让我们踏歌长行、梦想永续,下期见!


