对于刚刚落下帷幕的2023年,人们曾经给予其高度评价——AIGC元年。随着 ChatGPT 的火爆出圈,大语言模型、AI 生成内容、多模态、提示词、量化…等等名词开始相继频频出现在人们的视野当中,而在这场足以引发第四次工业革命的技术浪潮里,人们对于人工智能的态度,正从一开始的惊喜慢慢地变成担忧。因为 AI 在生成文字、代码、图像、音频和视频等方面的能力越来越强大,强大到需要 “冷门歌手” 孙燕姿亲自发文回应,强大到连山姆·奥特曼都被 OpenAI 解雇。在经历过 OpenAI 套壳、New Bing、GitHub Copilot 以及各式 AI 应用、各类大语言模型的持续轰炸后,我们终于迎来了人工智能的 “安卓时刻”,即除了 ChatGPT、Gemini 等专有模型以外,我们现在有更多的开源大模型可以选择。可这难免会让我们感到困惑,人工智能的尽头到底是什么呢?2013年的时候,我以为未来属于提示词工程(Prompt Engineering),可后来好像是 RAG 以及 GPTs 更受欢迎?
从哪里开始
在经历过早期调用 OpenAI API 各种障碍后,我觉得大语言模型,最终还是需要回归到私有化部署这条路上来。毕竟,连最近新上市的手机都开始内置大语言模型了,我先后在手机上体验了有大语言模型加持的小爱同学,以及抖音的豆包,不能说体验有多好,可终归是聊胜于无。目前,整个人工智能领域大致可以分为三个层次,即:算力、模型和应用。其中,算力,本质上就是芯片,对大模型来说特指高性能显卡;模型,现在在 Hugging Face 可以找到各种开源的模型,即便可以节省训练模型的成本,可对这些模型的微调和改进依然是 “最后一公里” 的痛点;应用,目前 GPTs 极大地推动了各类 AI 应用的落地,而像 Poe 这类聚合式的 AI 应用功能要更强大一点。最终,我决定先在 CPU 环境下利用 llama.cpp 部署一个 AI 大模型,等打通上下游关节后,再考虑使用 GPU 环境实现最终落地。从头开始训练一个模型是不大现实的,可如果通过 LangChain 这类框架接入本地知识库还是有希望的。
编译 llama.cpp
llama.cpp 是一个纯 C/C++ 实现的 LLaMA 模型推理工具,由于其具有极高的性能,因此,它可以同时在 GPU 和 CPU 环境下运行,这给了像博主这种寻常百姓可操作的空间。在 Meta 半开源了其 LLaMA 模型以后,斯坦福大学发布了其基于 LLaMA-7B 模型微调而来的模型 Alpaca,在开源社区的积极响应下,在 Hugging Face 上面相继衍生出了更多的基于 LLaMA 模型的模型,这意味着这些由 LLaMA 衍生而来的模型,都可以交给 llama.cpp 这个项目来进行推理。对硬件要求低、可供选择的模型多,这是博主选择 llama.cpp 的主要原因。在这篇文章里,博主使用的是一台搭配 i7-1360P 处理器、32G 内存的笔记本,按照 LLaMA 的性能要求,运行 GGML 格式的 7B 模型至少需要 13G 内存,而运行 GGML 格式的 13B 模型至少需要 24G 内存,大家可以根据自身配置选择合适的模型,个人建议选择 7B 即可,因为 13B 运行时间一长以后还是会感到吃力,哎😰。
准备工作
在正式开始前,请确保你可以熟练使用 Git,以及具备科学上网的条件,因为我们需要从 Hugging Face 上下载模型。此外,你还需要下载并安装以下软件:
- Python: 官方网站、华为镜像,建议选择 3.9 及其以上版本
- w64devkit:便携式 C/C++ 编译环境,集成了 gcc、make 等常见的工具
- OpenBLAS(可选): 可以提供 CPU 加速的高性能矩阵计算库,建议安装
w64devkit 和 OpenBLAS 下载下来都是压缩包,直接解压即可,建议将 w64devkit 解压在一个不含空格和中文的路径下,例如:C:\w64devkit。接下来,我们还需要 OpenBLAS 的库文件和头文件,请将其 include 目录下的内容,全部复制到 C:\w64devkit\x86_64-w64-mingw32\include 目录下;请将其 lib 目录下的 libopenblas.a 文件复制到 C:\w64devkit\x86_64-w64-mingw32\lib 目录下。保险起见,个人建议将 C:\w64devkit 目录添加到 Path 环境变量中,如下图所示:

至此,我们就完成了全部的准备工作。需要说明的是,这里是以 Windows + Make + OpenBLAS 为例进行演示和写作。如果你是 Mac 或者 Linux 系统用户,或者你想 CMake 或者 CUDA,请参考官方文档:https://github.com/ggerganov/llama.cpp,虽然这份文档是纯英文的,但是我相信这应该难不倒屏幕前的各位程序员朋友,哈哈😄。
编译过程
好的,对于 llama.cpp 而言,其实官方提供了预编译的可执行程序,具体请参考这里:https://github.com/ggerganov/llama.cpp/releases。通常情况下,普通的 Windows 用户只需要选择类似 llama-b2084-bin-win-openblas-x64.zip 这样的发行版本即可。如果你拥有高性能显卡,可以选择类似 llama-b2084-bin-win-cublas-cu12.2.0-x64.zip 这样的发行版即可,其中的 cu 表示 CUDA,这是由显卡厂商 Nvdia 推出的运算平台。什么样的显卡算高性能显卡呢?就我朴实无华的游戏史观点而言,只要能流畅运行育碧旗下的《刺客信条:大革命》及其后续作品的,都可以算得上高性能显卡。这里,我们选择手动编译,因为通读整个文档你就会发现,llama.cpp 里面提供了大量的编译参数,这些参数或多或少地会影响到你编译的产物。所以,如果你喜欢折腾,品味独特,我还是建议你手动编译 llama.cpp,平时使用 Visual Studio 编译程序多少有点温水煮青蛙啦🐸。

首先,我们使用 Git 克隆一份 llama.cpp 的源代码:
git clone https://github.com/ggerganov/llama.cpp
接下来,打开一开始准备好的 w64devkit.exe 工具,在这里其路径为:C:\w64devkit\w64devkit.exe,它将打开一个单独的命令行窗口。此时,我们需要进入上一步中克隆下来的 llama.cpp 源代码目录。在本文示例中,其路径为:
D:\Projects\llama.cpp。下面是对应的命令行语句:
cd d:\
cd projects/llama.cpp
至此,我们就进入了 llama.cpp 的源代码目录,还记得在准备工作阶段,我们提到过的 OpenBLAS 及其 CPU 加速功能吗?如果你不需要 CPU 加速功能,那么,你可以直接输入 make 命令,否则你需要输入 make LLAMA_OPENBLAS=1。博主这里选择的是后者,没有 GPU 当然要精打细算地过日子,你说对不对?
make LLAMA_OPENBLAS=1
此时,如果编译成功的话,你会在当前目录下看到编译出来的各种可执行文件:
如果没有的话,请按照下面的方式尝试重新生成,直至编译成功:
make clean
make LLAMA_OPENBLAS=1
坦白地讲,本来我一开始是打算从 llama-cpp-python 这个项目着手的,可惜通过 pip 安装的时候终于还是遇到了各种 C/C++ 的问题,最终决定还是返璞归真从 llama.cpp 本体入手。个人感觉 w64devkit 这个懒人包还是挺不错的,以前在 Windows 上想用 Make 或者 CMake 编译程序何其痛苦啊,现在总算是舒服了不少啊😏
大模型尝鲜
OK,llamp.cpp 编译成功以后,我们就可以用它来跑各种各样的 AI 大模型了,它支持哪些模型呢?在官方文档里作者给出了说明,这里仅仅截取了其中一部分,而对对于我们接下来的探索已经完全足够啦:
在当下的这场 AI 大模型追逐赛中,国内的大模型大多在模仿由 Meta 开源的 LLaMA 架构,无非是有些选择了从头开始训练,而有些选择了用中文语料做各种微调优化。如果一定追本溯源的话,LLaMA 参考了 GPT,GPT 参考了 Transformer,而 Transformer 则最早出现在 Google 于 2017 年发表的论文 Attention Is All You Need。说来有一点戏剧性,Google 在这场追逐赛中起了个大早,可目前看起来好像是投资了 OpenAI 的微软占据了上风,特别是 OpenAI 前 CEO 山姆·奥特曼已经加入微软,并且微软的 Copilot 在浏览器、桌面以及 Github 上都有着挺不错的表现。当然,历来代表着技术先进性的 Google 当然不会束手待毙,虽然目前的 Gemini Pro 还不及 ChatGPT,但终归可以讲一句未来可期。只有 OpenAI 一家独大,不管是对人工智能领域还是普通用户而言,绝对不是一件好事。

转换与量化
在接触大模型的过程中,除了提示词以外,你可能还会经常听到一个词:量化,下面我们就来聊一聊量化。如图所示,llama.cpp 使用大模型的基本流程,主要分为两步,分别是转化和量化。首先,来考虑第一个问题,为什么需要转化?前面提到过,现阶段 AI 大模型的起源都是 Transformer 模型,而 llama.cpp 使用的则是 GGML 模型,所以,当我们从 Hugging Face 上下载了某个大模型以后,第一件事情就是将其转化为 GGML 模型,这样,llama.cpp 便可以正确读取并使用这些模型进行推理。当然,更深层次的原因是,GGML 是和 llama.cpp 一起被设计出来的,其目的就是为了在 CPU 上运行量化后的模型,事实上,它们都出自同一个作者 Georgi Gerganov,GGML 由此得名,你可以将其理解为一个使用 C/C++ 实现的机器学习库。
接下来,我们来考虑第二个问题,什么是量化?根据知乎上的相关话题,ChatGPT-3 的模型参数最多高达 1750亿,而 ChatGPT-4 的模型参数则将近20000亿,你或许无法理解这些参数具体是什么,如果我们换一种方式来表示呢?根据估算,ChatGPT-3 的磁盘占用大约为 332G,而 ChatGPT-4 的参数规模大概是 ChatGPT-3 的 10 倍以上,这到底会给未来留下多少想象空间,我们始终无法得知,但如此庞大的规模哪怕对 GPU 来说依然是种负担。回想一下平时你玩过的那些 3A 大作的游戏目录你就知道了,这样一种体量的模型文件对人类来说,是完全不亚于奥特曼这般庞然大物的存在。至此,量化这种可以显著缩小模型体积的技术应运而生。

该如何解释这种技术呢?我们知道,一般的机器学习模型都使用单精度浮点型数值来表示,当我们使用一个有符号整型数值来近似替代的时候,虽然它会丢失部分精度,但是好处是这串数字的长度变短了。大模型量化采用了类似的原理,它会将模型中的权重和激活值表示为低精度的数据类型,这样,便可以减少模型的储存空间、能耗和计算时间,从而使其可以在资源受限的设备上高效运行。如上图所示,同一张图片在不同位数的颜色值下形态各异,可这副画的基本轮廓还是能看清楚的,这就是量化过程的形象化展示。显然,这是一种牺牲精度来换取性能的方案。
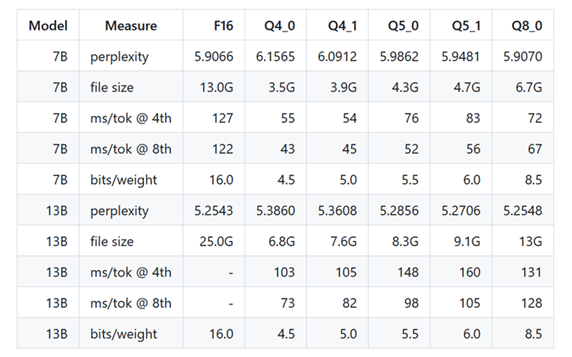 llama.cpp 不同量化方法下的模型文件体积与推理速度(已过期)
llama.cpp 不同量化方法下的模型文件体积与推理速度(已过期)
模型下载
现在,我们来聊聊模型下载问题,因为目前 Hugging Face 在国内基本处于不可访问的状态,但如果我们打算学习或者研究人工智能的话,这个网站始终是一个绕不过去的点,所以,这里来专门介绍下如何从 Hugging Face 上下载 AI 大模型。这里介绍三种方法:脚本下载、手动下载 以及 Git 下载。
脚本方式
如果你经常光顾 Hugging Face ,那么,你会在许多模型文件的 README 里见到下面的代码片段:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=False)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", torch_dtype=torch.float16, trust_remote_code=False)
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
这其实是一个用来测试预训练模型的脚本,不过它会缓存模型文件到本地,所以,这个方案一定程度上可行的,不过,经过我的测试,它一直在报 SSL 错误,即使挂着代理一样无法解决这个问题。在官方文档中一番折腾后,我发现了 hf_hub_download() 这个函数:
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="Qwen/Qwen-7B-Chat", filename="config.json")
非常遗憾,这个方法还是行不通,还是提示 SSL 错误,而且它一次只能下载一个文件,如果你想下载整个仓库,你需要使用 snapshot_download()。你知道在中国做程序员最痛苦的是什么吗?就是你对着官方文档一顿疯狂输出,结果最后输给了源、代理、加速器、镜像网站🙄
手动方式
手动下载这个方案虽然非常的低效,可你不得不承认,这居然是最靠谱的方案。如图所示,我们只需要依次点击图中的下载按钮即可。建议下载时单独建一个文件夹,将同一个仓库内的文件都放在不起,这样,更利于你管理不同的模型文件。当然,这些模型文件都挺大的,所以,需要你的磁盘足够大,网络足够好,同时要有足够的耐心:

我才不会告诉你,除了通义千问是用 Git 下载的,剩下的模型都是我手动下载的😕
Git 方式
作为程序员,Git 不单单是一个工具,更是一种信仰。这里博主重点点名表扬阿里的通义千问:
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone git@hf.co:Qwen/Qwen-7B-Chat
# if you want to clone without large files – just their pointers
# prepend your git clone with the following env var:
GIT_LFS_SKIP_SMUDGE=1
当然,还有从镜像网站 https://hf-mirror.com/ 下载模型的方法,这里就不再详细展开讲啦!此处的模型统一放在 llama.cpp 的 models 子目录下面,每个文件夹是一个模型,后续展开同样遵循这个原则。为了公平起见,我们使用同一个问题来向这些不同的模型进行提问,“昨天的当天是明天的什么”,看看 AI 大模型会作何反应。
Chinese-Llama-2-7B 体验
Step-1:完成模型的转换和量化:
python convert.py models/chinese-llama-2-7b/ --outfile models/chinese-llama-2-7b/chinese-llama-2-7b-ggml.bin
./quantize models/chinese-llama-2-7b/chinese-llama-2-7b-ggml.bin models/chinese-llama-2-7b/chinese-llama-2-7b-ggml-model-q4_0.bin q4_0
Step-2:以命令行交互的方式运行模型:
./main -m models/chinese-llama-2-7b/chinese-llama-2-7b-ggml-model-q4_0.bin -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
此时,运行结果如下:
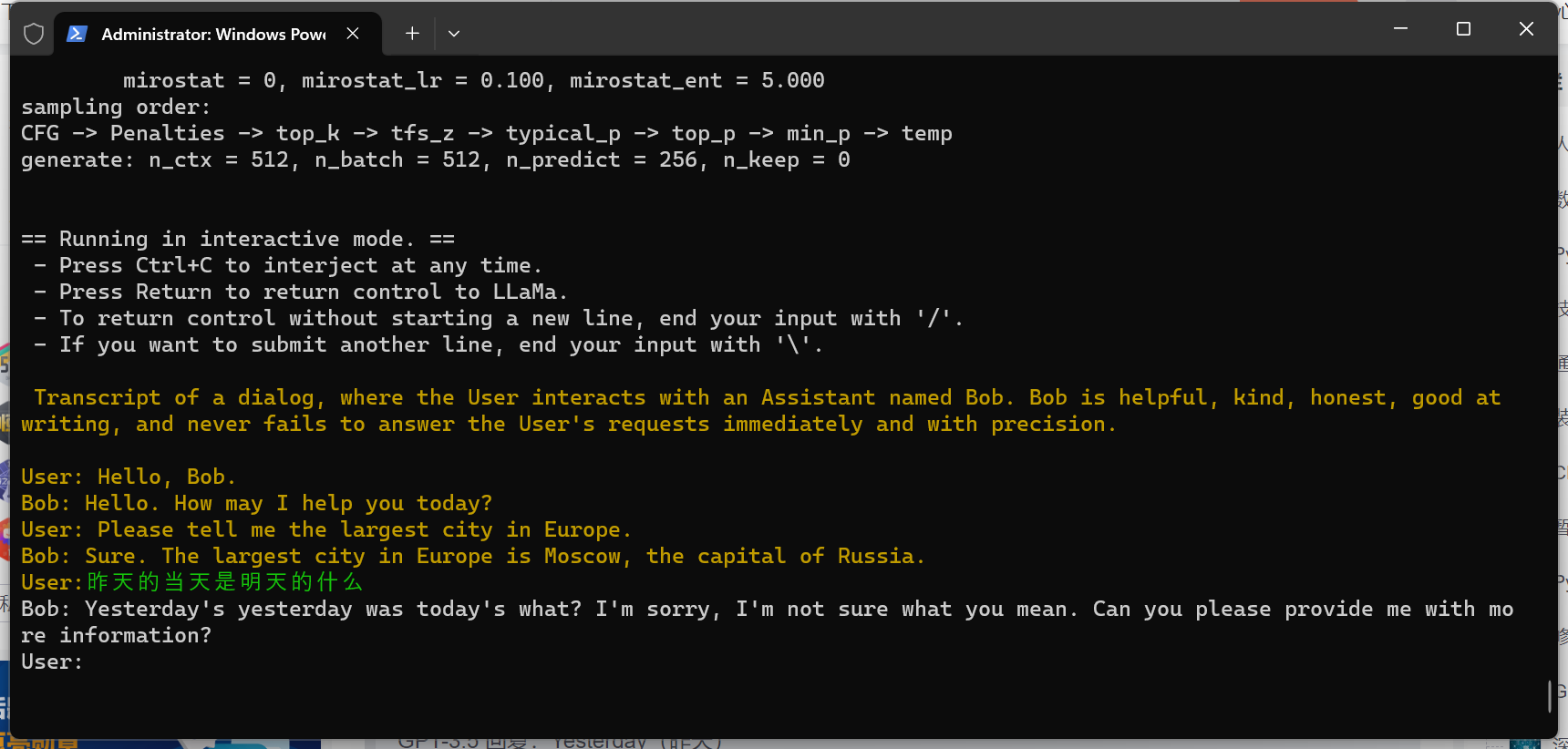 Chinese-Llama-2-7B 运行效果展示
Chinese-Llama-2-7B 运行效果展示
或许是这个问题太难,AI 被直接问出了母语,哈哈🤣
Chinese-Llama-2-13B 体验
Step-1:完成模型的转换和量化:
python convert.py models/chinese-llama-2-13b/ --outfile models/chinese-llama-2-13b/chinese-llama-2-13b-ggml.bin
./quantize models/chinese-llama-2-13b/chinese-llama-2-13b-ggml.bin models/chinese-llama-2-13b/chinese-llama-2-13b-ggml-model-q4_0.bin q4_0
Step-2:以命令行交互的方式运行模型:
./main -m models/chinese-llama-2-13b/chinese-llama-2-13b-ggml-model-q4_0.bin -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
此时,运行结果如下:
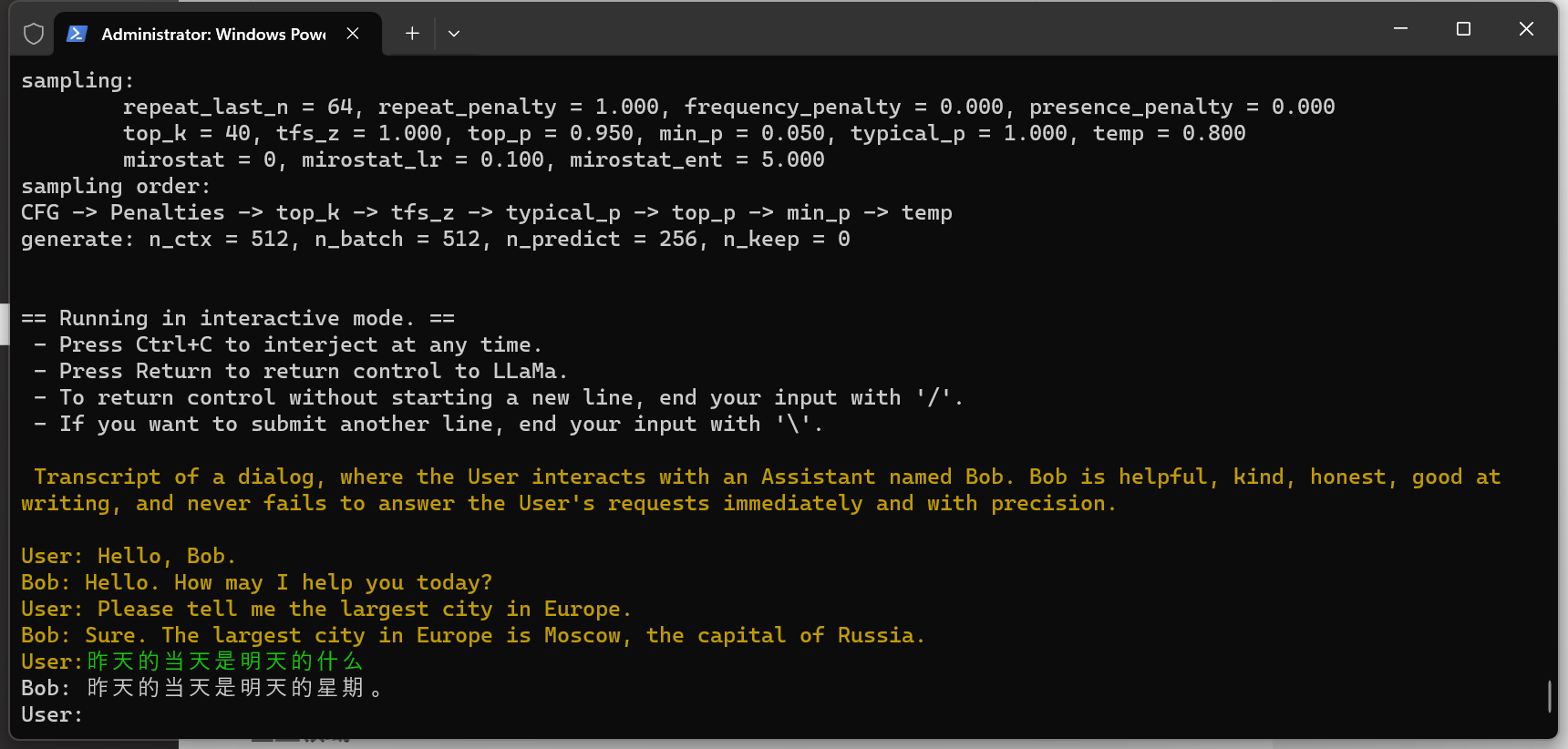 Chinese-Llama-2-13B 运行效果展示
Chinese-Llama-2-13B 运行效果展示
果然,13B 要比 7B 聪明一点,可这句话完全不通顺啊🤣
Chinese-Alpaca-2-7B 体验
Step-1:完成模型的转换和量化:
python convert.py models/chinese-alpaca-2-7b/ --outfile models/chinese-alpaca-2-7b/chinese-alpaca-2-7b-ggml.bin
./quantize models/chinese-alpaca-2-7b/chinese-alpaca-2-7b-ggml.bin models/chinese-alpaca-2-7b/chinese-alpaca-2-7b-ggml-model-q4_0.bin q4_0
Step-2:以命令行交互的方式运行模型:
./main -m models/chinese-alpaca-2-7b/chinese-alpaca-2-7b-ggml-model-q4_0.bin -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
此时,运行结果如下:
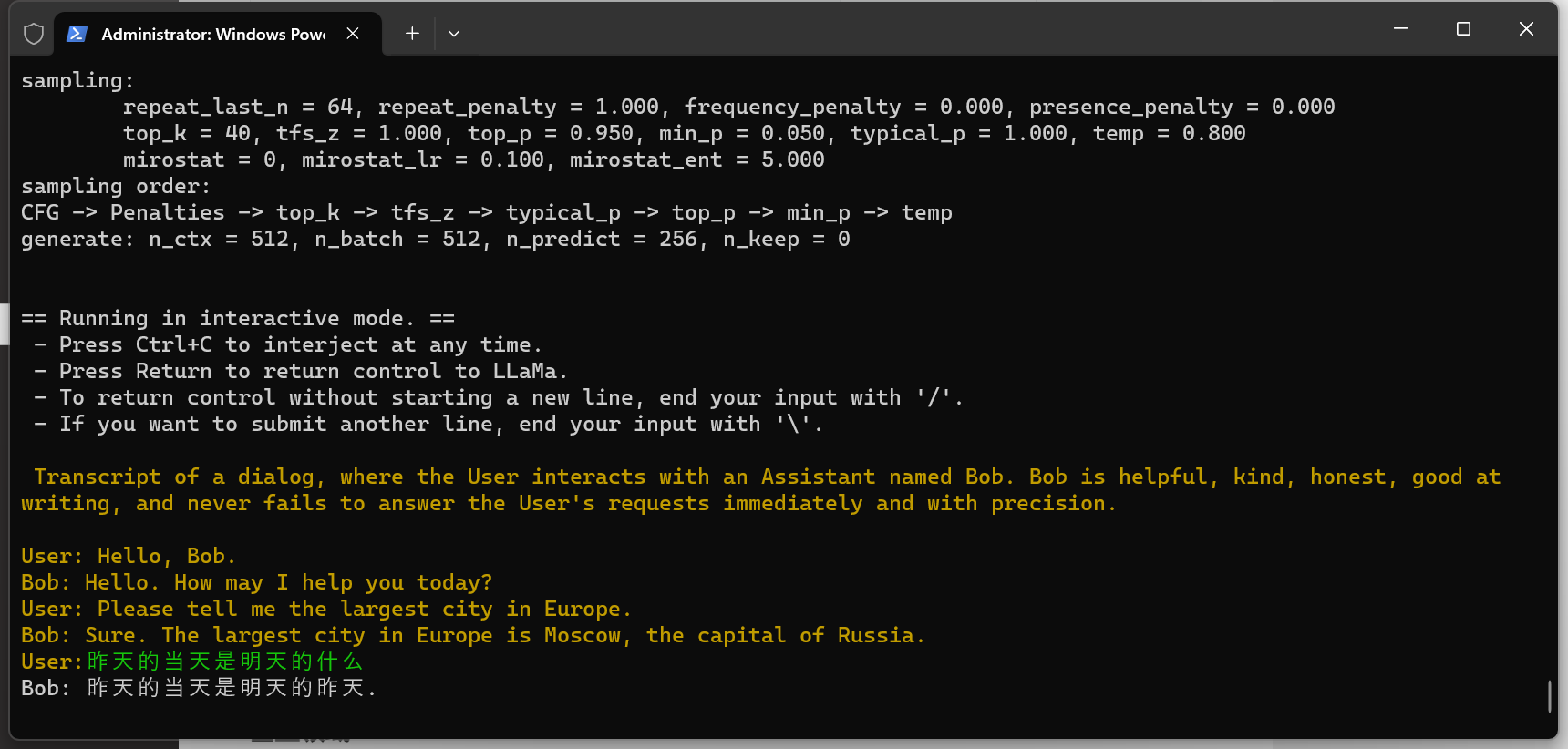 Chinese-Alpaca-2-7B 运行效果展示
Chinese-Alpaca-2-7B 运行效果展示
嗯,Alpaca 不愧是 LLaMA 的微调版本,这回答没有任何问题,甚至带着点哲学家的意味🤔
Qwen-1_8B-Chat 体验
Step-1:完成模型的转换和量化:
python convert-hf-to-gguf.py models/Qwen-1_8B-Chat/
./quantize models/Qwen-1_8B-Chat/ggml-model-f16.gguf models/Qwen-1_8B-Chat/ggml-model-q5_k_m.gguf q5_k_m
Step-2:以命令行交互的方式运行模型:
./main -m models/Qwen-1_8B-Chat/ggml-model-q5_k_m.gguf -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
此时,运行结果如下:
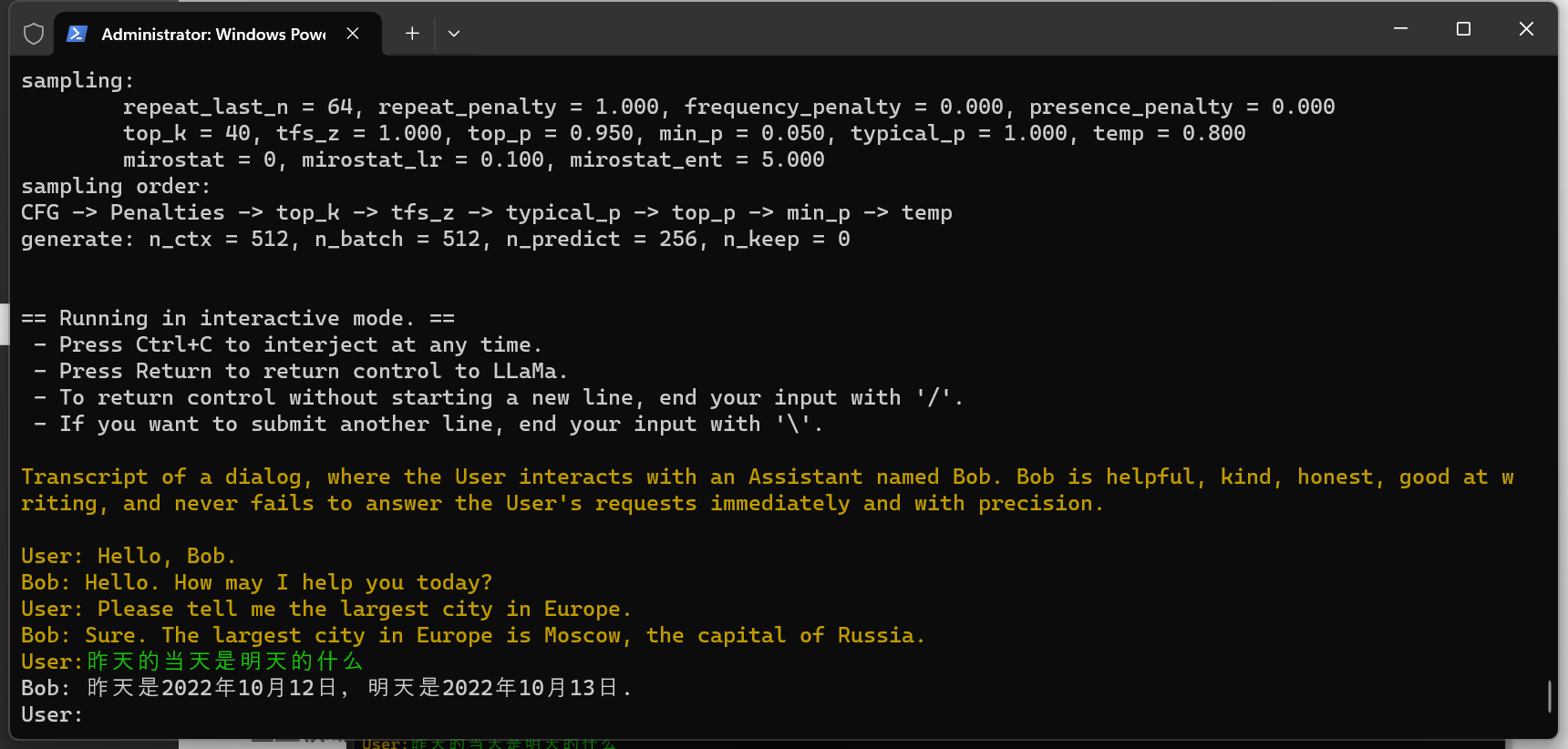 Qwen-1_8B-Chat 运行效果展示
Qwen-1_8B-Chat 运行效果展示
还是你最诚实,一不留神就暴漏了训练数据集的时间范围,整体对比下来,感觉还是阿里的 Qwen-1_8B-Chat 模型效果更好一点,实际如何呢,我们可以通过下面的命令来评估模型的好坏。其中,wikitext 是一个用来测试的数据集,可以从网上免费获得。这里以 Qwen-1_8B-Chat 模型为例,跑一次评估大概需要 2 个小时左右 :
./perplexity -m models/Qwen-1_8B-Chat/ggml-model-q5_k_m.gguf -f wikitext-2-raw/wiki.test.raw
下面是 Qwen-1_8B-Chat 的评估结果:

对接 ChatGPT-Next-Web
除了以上面这种命令行交互的方式运行模型,我们还可以使用下面的命令在本地运行一个 OpenAI 服务:
./server -m models/Qwen-1_8B-Chat/ggml-model-q5_k_m.gguf -c 2048
默认端口为 8080,llama.cpp 提供了一个相对简陋的聊天界面:
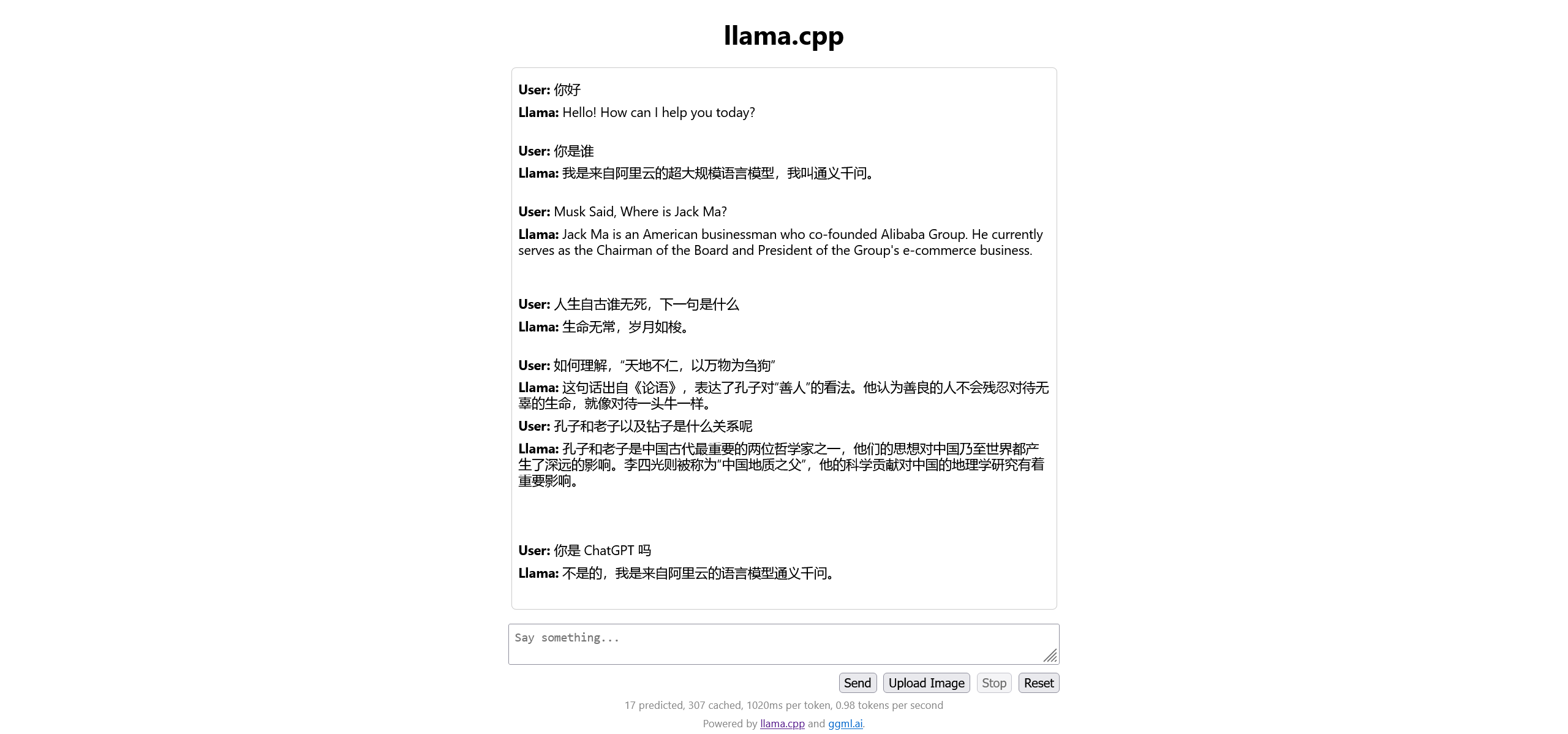
此外,llama.cpp 提供了完全与 OpenAI API 兼容的 API 接口,因此,我们可以使用 Postman 或者 Apifox 来请求本地的 AI 接口。当然,因为是使用 CPU 进行推理,所以,目前生成文本的速度非常感人:
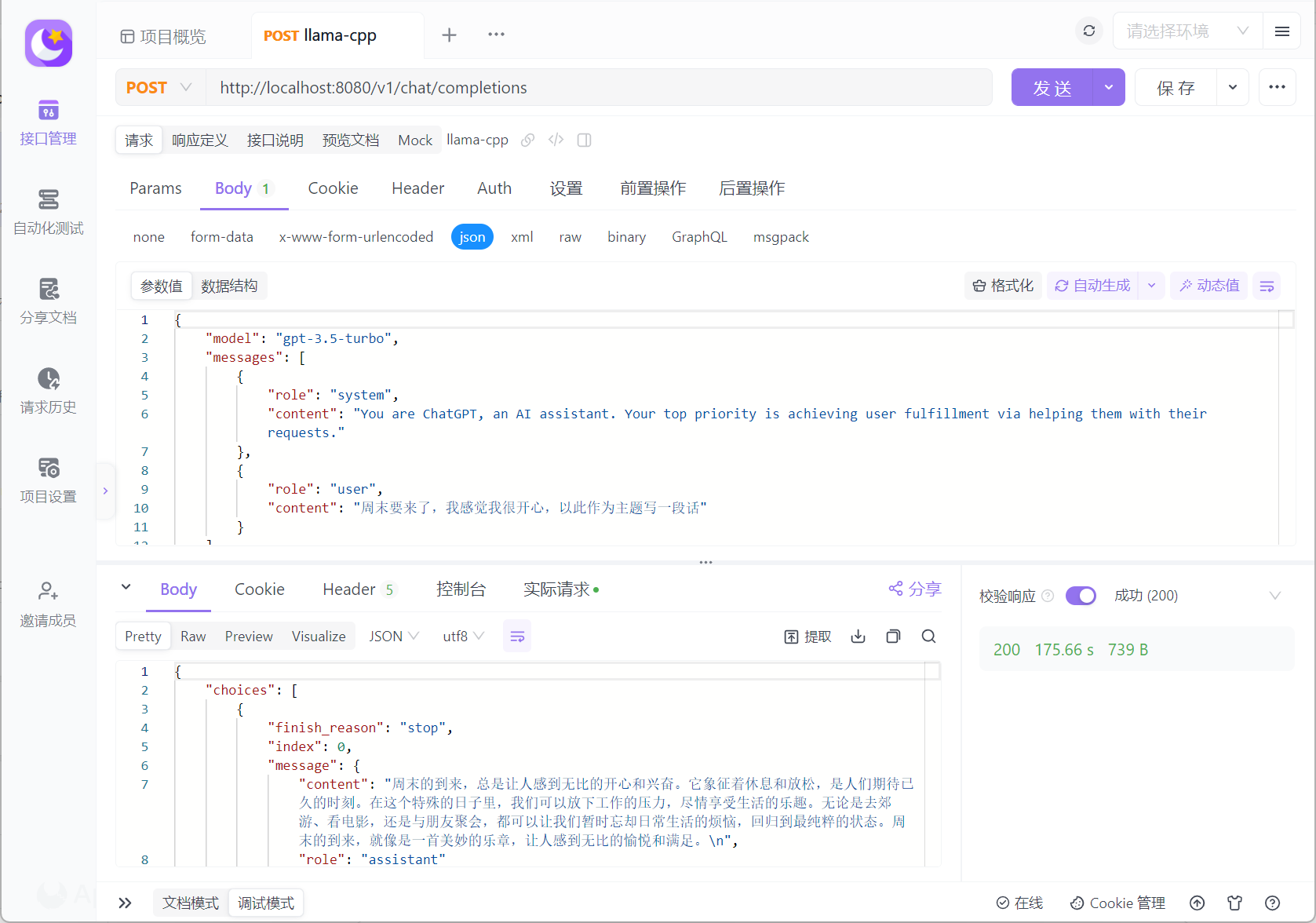
既然现在有了与 OpenAI API 完全兼容的接口,那么,我们就可以考虑将其接入支持 OpenAI API 的前端页面。这里,博主选择的是市面上最为流行的 ChatGPT-Next-Web。方便起见,这里我们直接使用 Docker 来进行演示:
# OPENAI_API_KEY 和 CODE 两个环境变量随便写即可
# 因为我们并不需要去调用真正的 OpenAI API
docker run -d -p 3000:3000 -e OPENAI_API_KEY=xxxx -e CODE=1qaz2wsx3edc yidadaa/chatgpt-next-web
接下来,我们在设置里维护一下接口地址,因为我们要使用自定义的接口,虽然文档里提到可以用 BASE_URL 以及 PROXY_URL 两个变量来配置,但我一直没有尝试成功,程序员每天起起落落的人生啊!
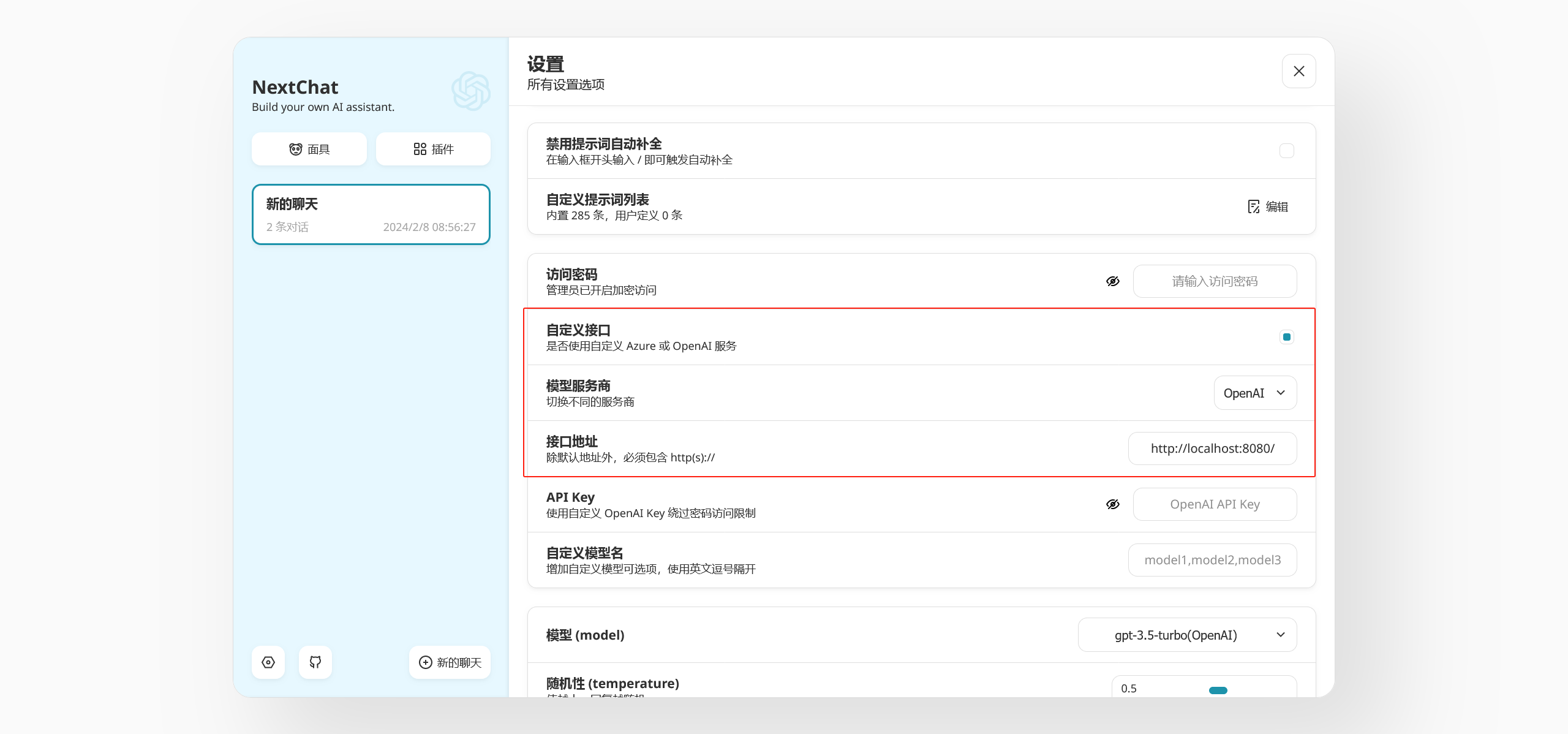
一切就绪以后,接下来,就是见证奇迹的时刻:
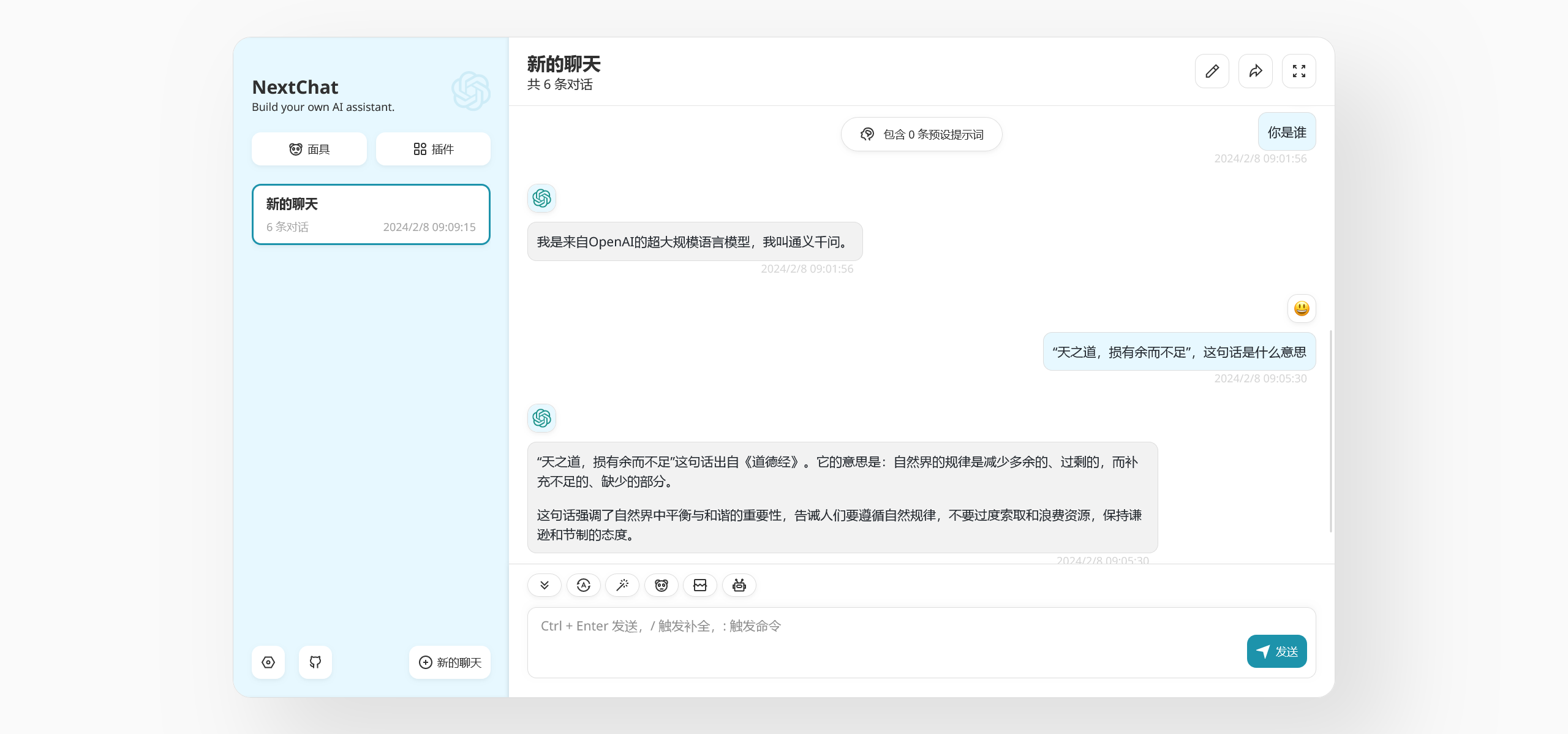
至此,我们成功地将 ChatGPT-Next-Web 和 llama.cpp 两个项目结合起来,初步达成了在本地部署 AI 大模型的小目标。按照这个思路,理论上你只要有台服务器,就可以构建出一个自己的 AI 聊天工具。当然,目前这个模型里的知识都来自阿里通义千问,如果你希望它更贴近自己的上下文,就可以考虑对现有模型进行微调或者使用 LangChain 这类框架接入本地知识库,因为 llama.cpp 里同样提供了 Embeddings 等功能的 API ,并且它与 OpenAI 的 API 完全兼容,这意味着它完全可以利用 OpenAI 周边的生态。显然,这是下一个阶段的规划啦!
本文小结
本文旨在尝试使用 llama.cpp 在本地部署 AI 大模型,随着人工智能的快速发展,我们逐渐认识到私有化部署的重要性和潜力。在此背景下,llama.cpp 作为一个纯 C/C++ 实现的 LLaMA 模型推理工具,提供了在本地环境下高性能的 AI 推理能力。在这篇文章中,我们可以了解到 llama.cpp 具有在 GPU 和 CPU 环境下运行的灵活性,满足私有化部署的需求。文章详细介绍了 llama.cpp 编译和部署的过程,为读者提供了一份在本地部署 AI 大模型的教程。私有化部署的 AI 大模型,相比于 ChatGPT 这类通用大模型,更注重数据隐私和安全性,对云服务的依赖更少,可以做到更好的本地化控制。虽然编译 llama.cpp 有一定的复杂性,AI 大模型的下载、转化、量化需要一定的耐心,可当本地的 AI 应用运行起来的那一刻,博主觉得这一切完全值得,以上就是本文的全部内容,下期再见!


