最近,我一直在尝试复刻 OpenAI 的 Canvas 功能,它与 Claude 的 Artifacts 功能非常相似。当然,两者在侧重点上有所不同——Artifacts 更注重于 “预览” 功能,而 Canvas 则专注于编程和写作领域。尽管 Artifacts 珠玉在前,可 Canvas 无疑为交互式体验带来更多可能性。对此,OpenAI 研究主管 Karina Nguyen 曾表示:我心目中的终极 AGI 界面是一张空白画布(Canvas)。在当前推崇 “慢思考” 的背景下,我有时会觉得下半年的大语言模型(LLM)发展 “不温不火”,给人一种即将停滞不前的的感觉。我想,这可能与四季更迭、万物枯荣的规律有关,正所谓 “环球同此凉热”。直到这两天,Claude 发布了 Computer Use,智谱发布了 AutoGLM,这个冬天再次变得热闹起来,为了不辜负这份幸运,我决定更新一篇博客,这次的主题是:容器技术驱动下的代码沙箱实践与思考。
为什么需要代码解释器?
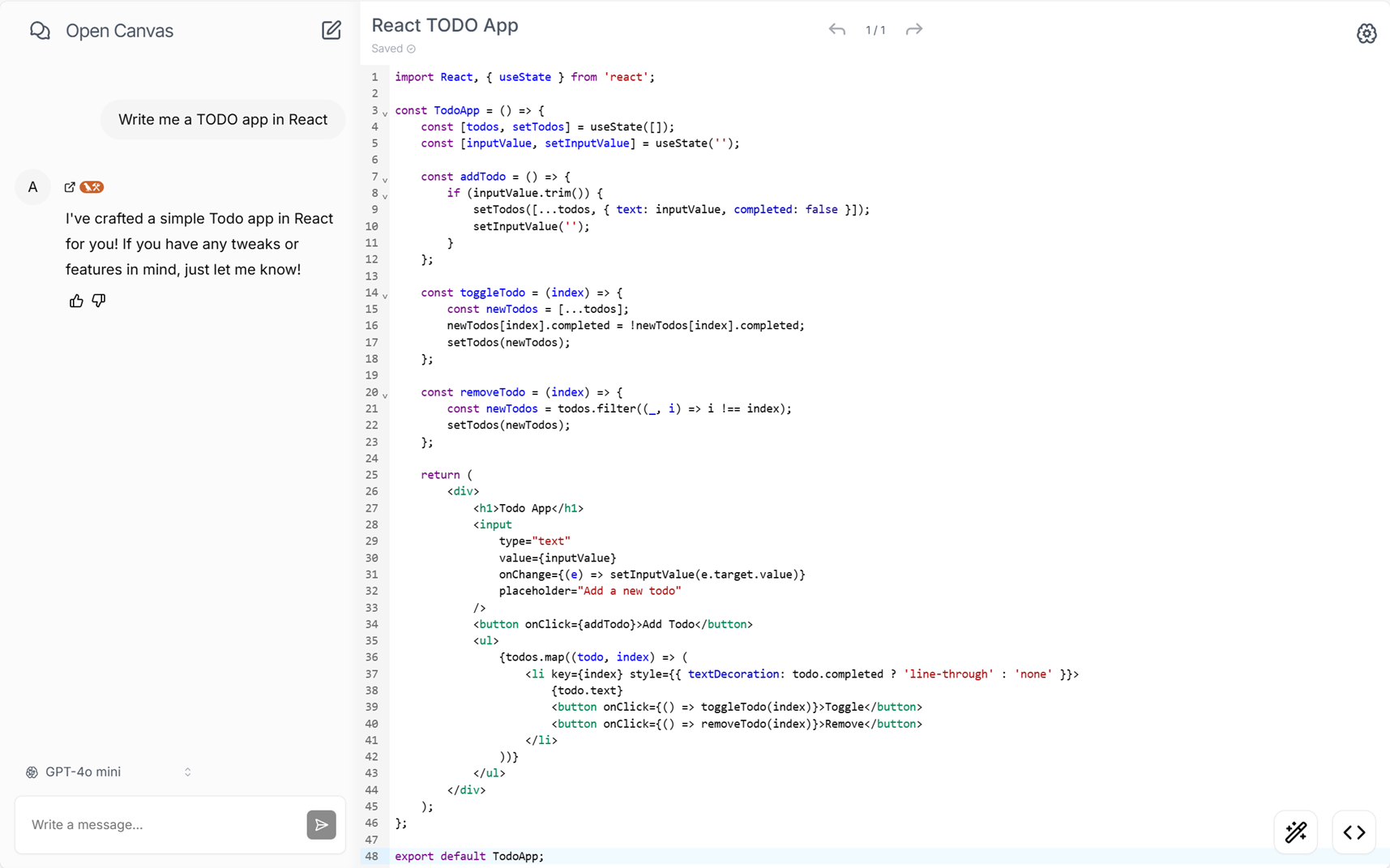
在当前生成式 AI 的浪潮中,代码生成首当其冲,从 CodeGeex 到通义灵码,从 Github Copilot 到 Cursor,可谓是层出不穷,其交互方式亦从代码补全逐渐过渡到代码执行。你会注意到,在 OpenAI 的 Canvas 以及 Claude 的 Artifacts 中,都支持前端代码的实时预览,这意味着 AI 生成的不再是冷冰冰的代码,而是所见即所得的、可交互的成果。其实,早在 ChatGPT-3.5 中,OpenAI 就提供了 Code Interpreter 插件,可见让 AI 生成代码并执行代码的思路由来已久。究其本质,编程是一项持续改进的活动,必须根据反馈不断地完善代码。如果你使用过 Cursor 这个编辑器,相信你会对这一过程印象深刻,你可以实时地看到修改代码带来的变化,快速验证想法,加快调试和迭代的速度。毫无疑问,这种即时反馈的交互模式大大提高了编程的效率和趣味。
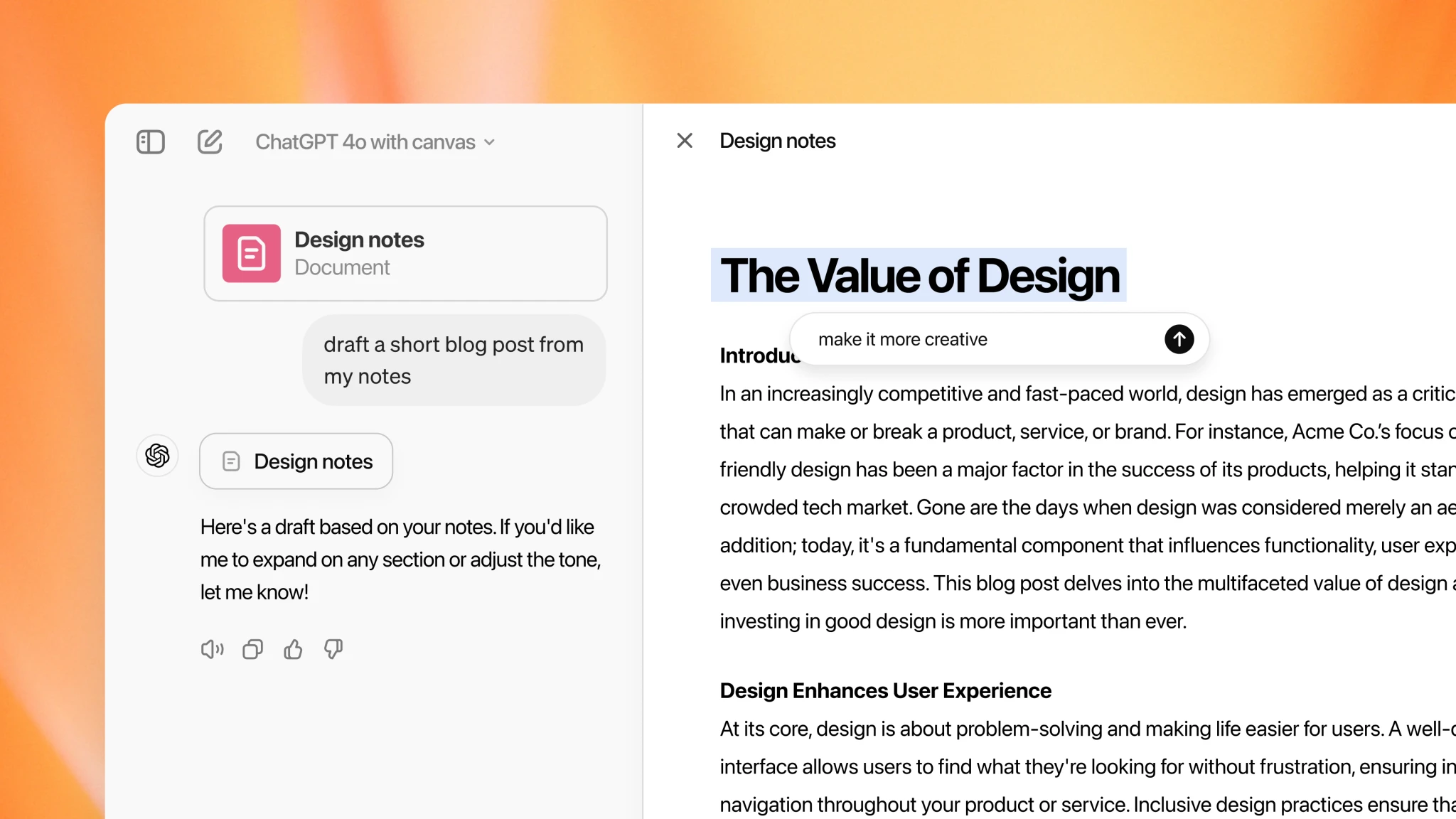
在实现 AI 智能体的过程中,我尝试为 Semantic Kernel 开发过一个 Code Interpreter 插件,我觉得这对于扩展(LLM)的能力边界意义重大。以 “9.11 和9.8 哪个大” 这一经典问题为例,在各路大模型普遍翻车的情况下,搭配 Code Interpreter 插件 Agent 表现稍好,因为它可以通过编写 Python 脚本来解决问题。同样地,像 “strawberry 中有多少个 r” 这样的问题,都可以通过该插件得到有效解决。或许有人觉得这种方式不够 “智能”,可如果使用工具是人类进步的体现,我们为什么要否认 AI 通过工具获得的答案呢?难道只有 o1 这种 “推理流” 才算思考,而 ReAct 这种 “规划流” 就不是思考?米兰·昆德拉说,“人类一思考,上帝就发笑”,人类的思想和行为,在宇宙或者更高存在的眼中可能微不足道,甚至有些可笑,以你我有限的认知去揣度智能,这本来就是一种虚妄。实际上,人类的思维过程并非总是纯粹的推理,我们同样依赖着工具、经验和试错。因此,我认为,无论是通过纯粹的推理还是借助工具,只要能有效地达成目标,都应该被视为智能的表现。
目前,这个 Code Interpreter 面临的问题是,它并未与宿主环境实现完全隔离。例如,在执行 C# 脚本时,可以选择 Roslyn、Mono、CS-Script 以及 dotnet-script;运行 Python 脚本时,可以选择 Python.NET;运行 JavaScript 时,可以选择 Jint。理论上,可以添加更多运行时环境,只要它们能嵌入.NET 框架。但这样做的风险是,一旦 AI 生成恶意代码,可能就会影响到整个 Agent 的运行。我曾考虑过 Python 的虚拟环境,但这个方案并不通用。更重要的是,Python.NET 依赖的是 Python 的动态链接库而非可执行文件,这意味着虚拟环境并未实现真正的隔离。此外,AI 生成的代码可能依赖第三方库,直接安装到宿主环境可能会引起版本冲突。在大量使用 AI 生成的代码时,我们不得不考虑这些代码的安全性。我的老板曾问我,“你敢在生产环境中直接使用大模型生成的SQL语句吗?”,基于这些考虑,我们必须寻找一种更优的代码沙箱方案。
容器技术驱动的代码沙箱
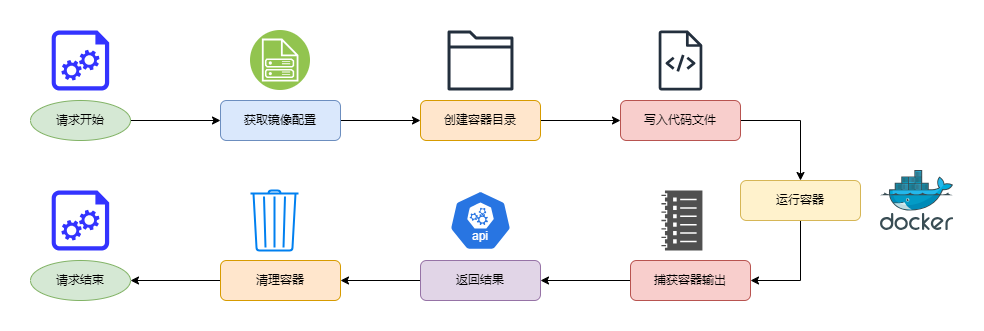
我们的目标是:创建一个与宿主环境完全隔离的代码沙箱,它能够独立运行代码并管理依赖。此时,我们发现容器技术非常适合这一需求,因为 Docker 利用 Linux 的 Namespace 功能实现了资源隔离。具体来说,我们会为每一种语言准备一个镜像,这个镜像中通常包含了该语言的编译器或者解释器,例如,Java 使用 OpenJDK 镜像,C# 使用.NET SDK 镜像。运行代码时,首先将代码文件挂载到容器中,然后使用编译器或解释器处理该文件。以下是一个简化的流程说明图:
以 Python 为例,假设我们有一个名为 code_runner/python3 的镜像,其对应的 Dockerfile 定义如下:
FROM python:3.9.18
RUN useradd --create-home --no-log-init --shell /bin/bash sandbox \
&& adduser sandbox sudo
USER sandbox
WORKDIR /home/sandbox
你会注意到,这里创建了一个名为 sandbox 的用户,同时指定了其工作目录为 /home/sandbox。 这一点非常重要,因为我们希望使用统一的方式来处理不同的镜像。接下来,对于每一个前端请求,我们将在后端生成一个目录,并在其中存放待执行的代码文件,这里我们将其命名为 code.py。此时,通过下面的命令就可以创建容器:
# runner_b8de2d4e-9b72-4e16-99ad-b0a4db6def7f 为后端自动生成的目录
# 其中存放着待执行的代码文件 code.py
docker run -t -d \
-v runner_b8de2d4e-9b72-4e16-99ad-b0a4db6def7f:/home/sandbox:rw \
code_runner/python3 python code.py
如果一切顺利的话,你会看到容器开始运行。至此,在容器中执行代码已成为现实。那么,如何得到代码的执行结果呢?通常情况下,你有下面这两种选择:
- 容器日志:通过容器日志来捕获程序输出,即:docker logs <容器Id>
- 输出重定向:将标准输出重定向到文件,然后再通过读取该文件来捕获程序输出
如果选择第二种方案,你需要将脚本修改为类似下面这样:
docker run -t -d \
-v runner_b8de2d4e-9b72-4e16-99ad-b0a4db6def7f:/home/sandbox:rw \
code_runner/python3 python code.py > output.txt
这里,我们选择第一种方案,如图所示,程序输出的结果是:Hello World.:

接下来的流程就变得简单啦,因为我们只需要删除容器、清理目录、返回结果,这个过程非常简单不再赘述。在实际场景中,我们更希望将这一切自动化。当然,你可以使用类似 os.system() 的方案执行 docker 命令。但是,更好的选择是,直接使用 Docker 的 Python SDK。此时,上述流程可以被简化为以下代码片段:
import uuid, docker
container_name = f"./runner_{uuid.uuid4()}"
container = client.containers.run(
image='code_runner/python3',
command='python code.py',
volumes={os.path.abspath(container_name): {
'bind': '/home/sandbox',
'mode': 'rw'
}},
tty=True,
detach=True
)
container.wait()
output = container.logs().decode('utf-8')
container.stop()
container.remove(force=True)
基于这一原理,我们将镜像和命令与特定语言关联起来,从而得到一个配置文件。实际上,在设计的流程中,后端接收前端请求以后,首要任务是根据选定语言获取相应的镜像和命令。这使我们能够统一处理多种语言。如需支持新语言,只需准备相应的镜像和配置信息。以下配置文件展示了 Python、JavaScript、C# 和 C++ 的实现细节:
{
'python3': {
'image': 'code_runner/python3',
'command': 'python code.py',
'extension': 'py'
},
'javascript': {
'image': 'code_runner/nodejs',
'command': 'node code.js',
'extension': 'js'
},
'csharp': {
'image': 'code_runner/dotnet',
'command': 'dotnet script code.csx',
'extension': 'csx'
},
'csharp-mono': {
'image': 'code_runner/mono',
'command': "sh -c 'mcs -out:code code.cs && mono ./code'",
'extension': 'cs'
},
'cpp': {
'image': 'code_runner/cpp',
'command': "sh -c 'g++ code.cpp -o code && ./code'",
'extension': 'cpp'
}
}
如图所示,我们现在可以在代码沙箱中运行 C# 代码,这个沙箱目前利用 Mono 来编译和执行程序:

实践过程中遇到的挑战
到目前为止,一切都算顺利,可如果你认为这就是全部的话,那可就太天真啦!首当其冲的是各种编译型语言,以 C++ 为例,通常的编译命令如下,它实际上是将编译和运行两个步骤合二为一:
g++ code.cpp -o code && ./code
可如果你直接将这个命令应用到 Docker 上,你会发现这个 && 无法被正确地识别。此时,你需要使用 sh -c 命令对当前命令进行包装,这样就可以完美地规避这个问题:
sh -c 'g++ code.cpp -o code && ./code'
如果你运气不佳的话,你可能还会遇到 g++、mono、mcs 这些命令行工具在容器内找不到的情况,此时,你还需要添加必要的环境变量,以 Mono 为例,你可以在 Dockerfile 中做如下处理:
ENV PATH="/usr/bin:/usr/local/bin:${PATH}"
继续探索,博主这里考虑了两种 C# 脚本化的方案,它们分别是 Mono 和 dotnet-script,其中:Mono 使用的是标准的 C# 语法,这意味着它必须要有入口方法 Main(),而 dotnet-script 使用的是顶级语句,所有代码会被放置在一个隐式的 Main() 方法中执行。如果说这种语法上的细微差异尚可接受,那么,接下来请你做好破防的准备:

当然,这并不是你的错,根本原因在于 Docker 输出的日志中包含特殊的 ANSI 转义序列,这些特殊字符通常用于控制终端输出时的颜色和样式,此刻变成了某种噪音。这里,博主介绍两种思路来解决这个问题:
- 思路一:正则替换法,网络上广泛流传的正则表达式 r’\x1b[[0-9;]*[mK]’,经验证,无效!😹
def remove_ansi_sequences(input_string):
ansi_escape = re.compile(r'\x1b\[([0-?]*[ -/]*[@-~])')
return ansi_escape.sub('', input_string).replace('\x1b=','')
- 思路二:重定向法,将终端的标准输出重定向到一个文本文件。果然,大道至简!😂
dotnet script code.csx > ./output.txt
个人更推荐这种方案,万一正则表达式再次失效了呢?到目前为止,这个代码沙箱里运行的都是代码片段,这意味着我们可以先暂时忘掉工程实践中的层级结构,你不必通过工程文件或者解决方案来描述各个文件之间的关系。可这样自然就会产生一个问题,代码中的依赖的第三方库该怎么办?此时你有两种策略可供选择:
- 策略一:在镜像里通过包管理器提前安装好常用的第三方库,最典型的例子是 Anaconda,它预装了大量与科学计算相关的第三方库,如 NumPy、Pandas 等,可以做到一般意义上的开箱即用。
- 策略二:在代码沙箱运行时自动安装第三方库,如果你使用过 Jupyter Notebook,相信你会非常熟悉它管理依赖的方式。如下图所示,我们可以在 Jupyter Notebook 中使用 pip、NuGet 这类包管理器:
在这种情况下,虽然我们依然是在 Jupyter Notebook 的单元格里写代码,可工程化的思维早已深入人心,“代码即工程,工程即代码”。只要大模型可以同时生成代码和依赖项,那么,理论上这些代码上就可以通过 Jupyter Notebook 运行起来。所以,我接下来的想法是,在有了 dotnet-script 和 Mono 这两种 C# 的编译器以后,我想继续扩展出基于 Jupyter Notebook 的方案,至少现在解决了第三方库的依赖问题,对吧?
Jupyter 与结果可视化
你可能会疑惑,既然 dotnet-script 和 Mono 都能运行 C#,为什么还要考虑 Jupyter?除了处理第三方库依赖问题以外,Jupyter 的可视化功能是我最为看重的特性。比如, 对于数据分析这类任务,如果我们能让大模型将分析结果以图表形式展示出来,这无疑会极大地提升产品的用户体验。再比如,我之前尝试 Text2SQL 的时候,如果 SQL 查询结果能以表格或 Excel 格式展现出来,效果会不会更佳?我认为,Code Interpreter 适用于两种场景,即:非展示类场景和展示类场景,前者是用程序执行的结果作为上下文,而后者是需要对程序执行的结果进行展示。显然,在后面这种场景中,Jupyter Notebook 表现上要更胜一筹。如下图所示,我们可以在 Jupyter Notebook 中绘制出各式各样的图表:
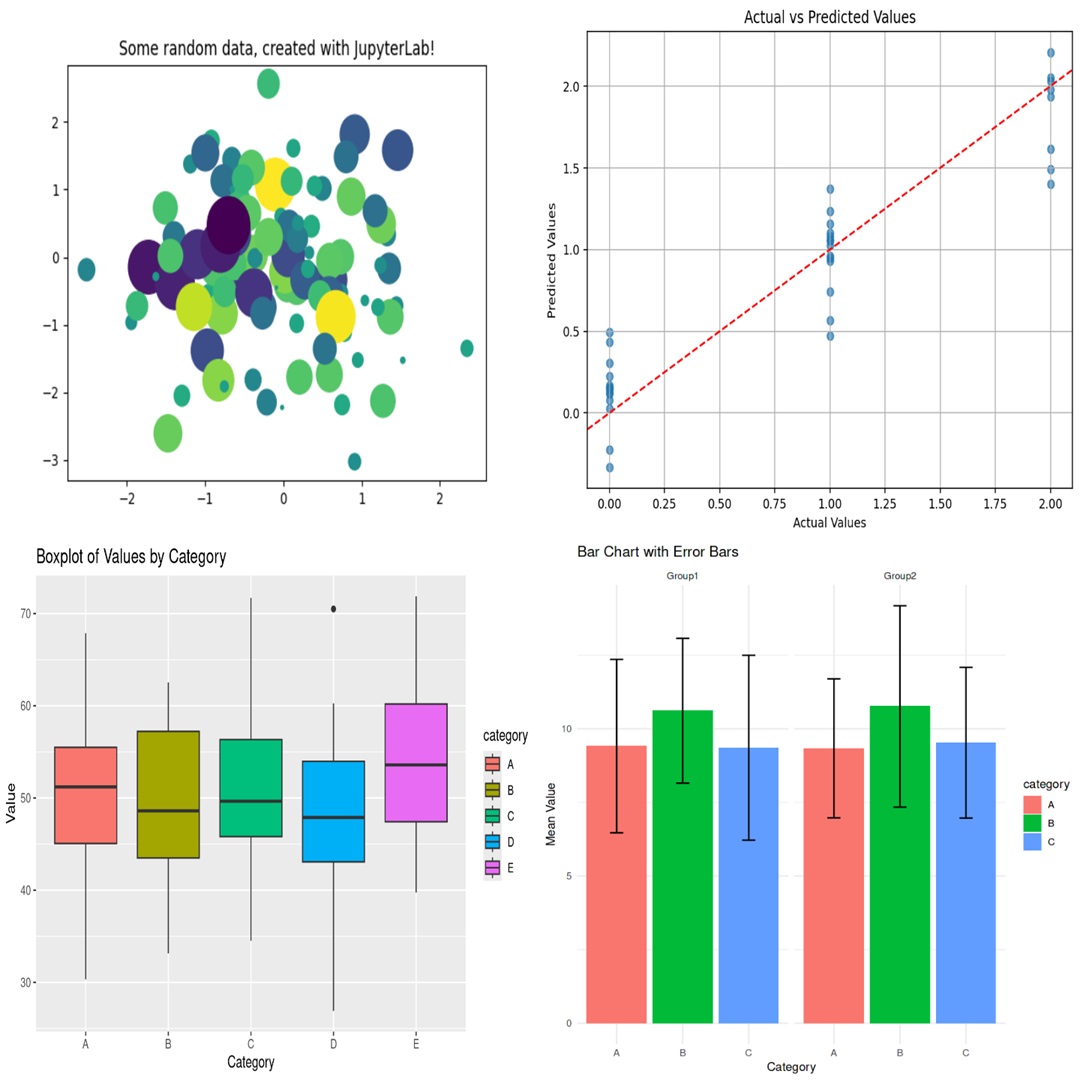
好了,现在让我们来思考,如何将 Jupyter 与我们在前面收获到的经验结合起来。这里需要用到两个重要的工具: nbformat 以及 nbconvet。其中,前者负责将代码片段转化为 .ipynb 格式的笔记本,后者负责执行笔记本、获取结果以及格式转换等。如图所示,下面是与 Jupyter 相关的流程示意图:

在整个流程中,第一步是从代码片段创建 .ipynb 格式的笔记本文件,而从 nbformat 的文档中我们可以了解到,Jupyter 的笔记本文件其实是一个 JSON 文件,其标准结构通常类似于下面这样:
{
"metadata": {
"kernel_info": {
# if kernel_info is defined, its name field is required.
"name": "the name of the kernel"
},
"language_info": {
# if language_info is defined, its name field is required.
"name": "the programming language of the kernel",
"version": "the version of the language",
"codemirror_mode": "The name of the codemirror mode to use [optional]",
},
},
"nbformat": 4,
"nbformat_minor": 0,
"cells": [
# list of cell dictionaries, see below
],
}
对我们而言,这里最关键的是其中的 cells 节点,因为我们需要将代码片段放在这里,在 Jupyter 中通常有三种形式的单元格,即:Code、Markdown 以及 Raw,它们之间唯一的区别是 Code 类型的单元格可以有输出、执行次数等信息,这些细节均可以在文档中找到,这里不再赘述。通常,单元格的标准结构定义如下:
{
"cell_type": "type",
"metadata": {},
"source": "single string or [list, of, strings]",
}
不要紧张,我们不会愚蠢到要去手写这个文件的地步,相信我,通过 nbformat 包这一切会变得非常简单:
import nbformat
def code_to_ipynb(code_string, notebook_name='output_notebook.ipynb'):
nb = nbformat.v4.new_notebook()
code_cell = nbformat.v4.new_code_cell(code_string)
nb['cells'].append(code_cell)
with open(notebook_name, 'w', encoding='utf-8') as f:
nbformat.write(nb, f)
现在,我们拥有了一个 .ipynb 格式的笔记本文件,你可以直接通过 Jupyter Notebook 或者 JupyterLab 打开它。当然,我们这里更希望它可以在后台静默执行,因为我们并不需要用到 Jupyter 的可视化界面。此时,我们可以使用 nbconvert 这个工具,它可以将 .ipynb 格式的笔记本文件转换为 HTML、LateX、PDF、Markdown 等常见格式,在指定 Kernel 的情况下,你甚至可以运行整个笔记本文件中的代码,下面是部分命令示例:
# 将笔记本转换为 HTML
jupyter nbconvert --to html notebook.ipynb --output notebook.html
# 运行笔记本,然后转换为 HTML
jupyter nbconvert --execute --to html notebook.ipynb --output notebook.html
# 运行笔记本,忽略输入,然后转换为 HTML
jupyter nbconvert --execute --no-input --to html notebook.ipynb --output notebook.html
# 运行笔记本,忽略输入,指定 Kernel,然后转换为 HTML
jupyter nbconvert --execute --no-input --to html --ExecutePreprocessor.kernel_name=python3 notebook.ipynb --output notebook.html
# 运行笔记本,直接覆盖原来的笔记本
jupyter nbconvert --to notebook --execute --inplace notebook.ipynb
如果你不喜欢命令行,你还可以使用 nbconvert 的类库,这一刻,风和你都是自由的:
import nbformat
from nbconvert import HTMLExporter
notebook = nbformat.read('notebook.ipynb', as_version=4)
html_exporter = HTMLExporter(template_name="classic")
(body, resources) = html_exporter.from_notebook_node(notebook)
至此,整个 Jupyter 相关的处理流程便在逻辑上实现了闭环,只要我们生成 .ipynb 格式的笔记本并将其挂载到容器中,然后再通过 nbconvert 完成转换即可。考虑到我们未来需要在前端中展示 Jupyter 的运行结果,我们直接返回 HTML 即可。那么,接下来,就是见证奇迹的时刻:

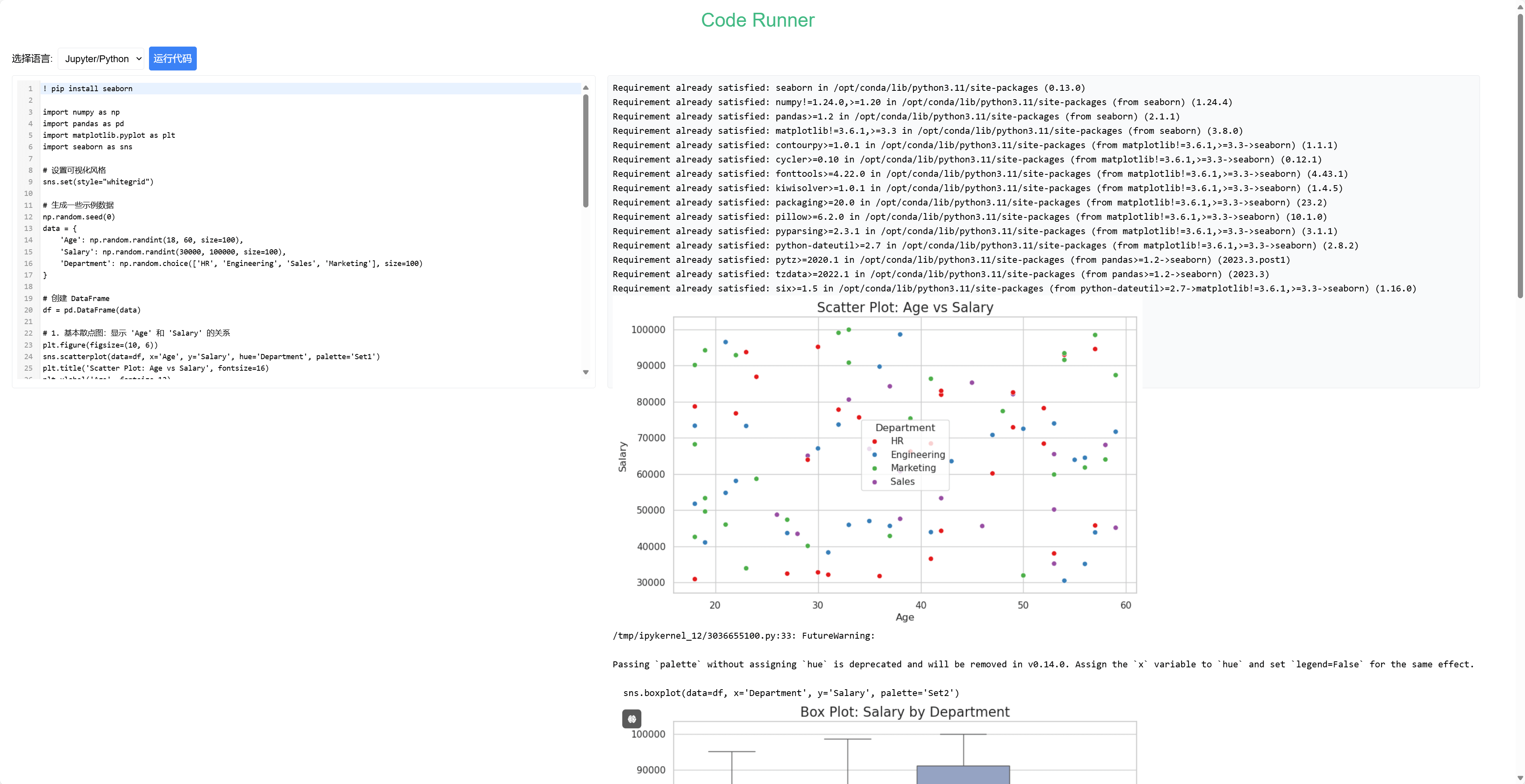
本文小结
从 OpenAI 的 Code Interpreter 到 Canvas,从 Claude 的 Artifacts 到 Computer Use,我们一起见证了 AI 编程领域的快速发展。在此过程中,代码执行环境的安全性和隔离性成为了一个重要议题。本文探讨了基于容器技术的代码沙箱方案,这是对挑战的积极探索和实践。容器技术完美解决了代码执行的隔离问题,每个代码片段都在独立的容器中运行,拥有自己的运行时环境,不影响宿主系统。这种方案不仅确保了安全性,还提供了统一的环境管理能力。实践过程充满挑战、一波三折,可容器技术带来的便利性不容忽视。更重要的是,这种方案具有良好的可扩展性,支持多种编程语言,为 AI 运行代码提供了坚实的技术基础。展望未来,随着生成式 AI 技术的进步,代码沙箱的重要性将日益凸显,或许正如 OpenAI 研究主管所说的 “终极 AGI 界面是一张空白画布”,代码沙箱将会成为通向这个愿景的重要基础设施之一,生成代码、执行代码、可视化结果将成为AGI世界的标准能力。


