本文是 #视频是不能 P 的系列# 的第三篇。此前,我们已经可以通过 OpenCV 或者 Dlib 实现对人脸的检测,并在此基础上实现了某种相对有趣的应用。譬如,利用人脸特征点提取面部轮廓并生成表情包、将图片中的人脸批量替换为精神污染神烦狗 等等。当然,在真实的应用场景中,如果只是检测到人脸,那显然远远不够的,我们更希望识别出这张人脸是谁。此时,我们的思绪将会被再次拉回到人脸识别这个话题。在探索未知世界的过程中,博主发现 OpenCV 自带的 LBPH 方法,即局部二值模式直方图方法,识别精度完全达不到预期效果。所以,博主最终选择了 Dlib 里的特征值方法,即:对每一张人脸计算一个 128 维的向量,再通过计算两个向量间的欧式距离来判断是不是同一张人脸。在此基础上,博主尝试结合 支持向量机 来实现模型训练。因此,这篇文章其实是对整个探索过程的梳理和记录,希望能给大家带来一点启发。
原理说明
如下图所示,假设对于每一个人物 X ,我们有 N 个人脸样本,通过 Dlib 提供的 compute_face_descriptor() 方法,我们可以计算出该人脸样本的特征值,这是一个 128 维度的向量。如果我们对这些人脸样本做同样的处理,我们就可以得到人物 X 的特征值列表 feature_list_of_person_x。在此基础上,利用 MumPy 中的 mean() 方法,我们就可以计算出人物 X 的平均特征 features_mean_person_x。最终,我们把人物 X 的平均特征和名称一起写入到一个 CSV 文件里面。至此,我们已经拥有了一个简单的人脸数据库。
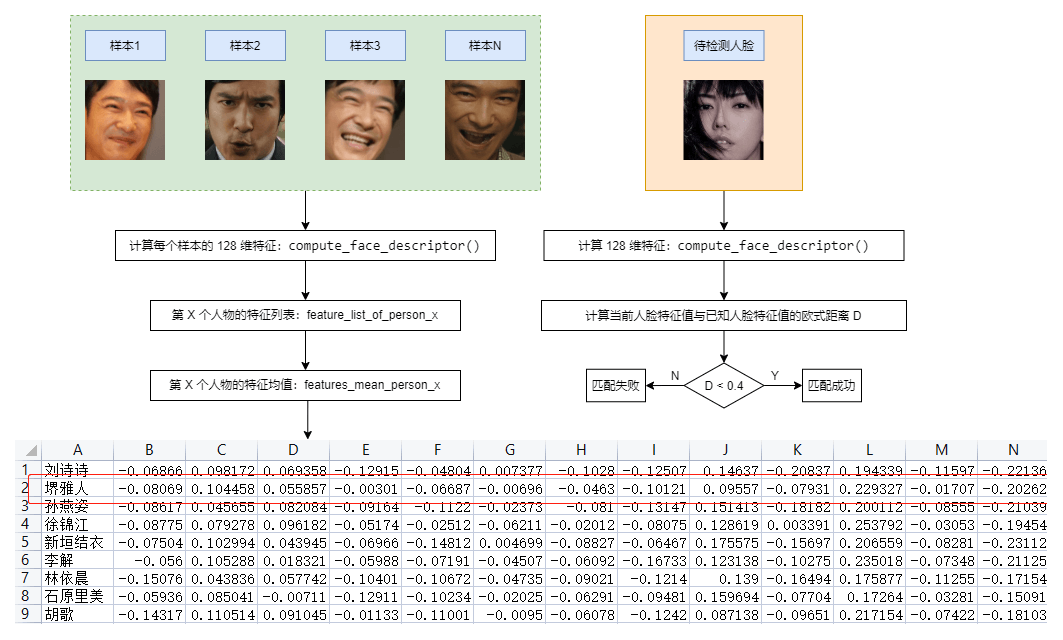
可以预见的是,一旦我们把人脸特征数值化,那么,人脸识别就从一个图形学问题变成了数学问题。对于图中的待检测人脸,我们只需要按同样地方式计算出特征值,然后从 CSV 文件中找一个距离它最近的特征即可。这里,博主使用的是欧式距离,并且人为规定了一个阈值 0.4, 即:当这个距离小于 0.4 时,我们认为人脸匹配成功;当这个距离大于 0.4 时,我们认为人脸匹配失败。下面的例子展示了使用 Dlib 计算人脸特征值的基本过程:
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')
face_reco_model = dlib.face_recognition_model_v1("dlib_face_recognition_resnet_model_v1.dat")
# 计算特征值
image = Image.open('/faces/person/sample-0.jpg')
image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
faces = detector(image, 1)
if len(faces) != 0:
face = faces[0]
shape = predictor(image, face)
face_descriptor = face_reco_model.compute_face_descriptor(image, shape)
此时, face_descriptor 就是当前人脸的特征值,这是一个 128 维的向量。我们只需要对每一个人脸样本重复以上步骤,就可以获得人物 X 的特征值列表,进而计算出人物 X 的特征均值。
实现过程
如下图所示,我们为每一个人物建立了一个文件夹,文件夹的名称即为对应人物的名称:

显然,对于每一个人物而言,我们只需要遍历该文件夹下的所有图片,即可计算出它的特征均值:
def get_mean_features_of_face(path):
path = os.path.abspath(path)
subDirs = [os.path.join(path, f) for f in os.listdir(path)]
subDirs = list(filter(lambda x:os.path.isdir(x), subDirs))
for index in range(0, len(subDirs)):
subDir = subDirs[index]
person_label = os.path.split(subDir)[-1]
image_paths = [os.path.join(subDir, f) for f in os.listdir(subDir)]
image_paths = list(filter(lambda x:os.path.isfile(x), image_paths))
feature_list_of_person_x = []
for image_path in image_paths:
# 计算每一个图片的特征
feature = get_128d_features_of_face(image_path)
if feature == 0:
continue
feature_list_of_person_x.append(feature)
# 计算当前人脸的平均特征
features_mean_person_x = np.zeros(128, dtype=object, order='C')
if feature_list_of_person_x:
features_mean_person_x =
np.array(feature_list_of_person_x, dtype=object).mean(axis=0)
yield (features_mean_person_x, person_label)
其中,get_128d_features_of_face() 方法用来计算某个图片的特征值:
def get_128d_features_of_face(image_path):
image = Image.open(image_path)
image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
faces = detector(image, 1)
if len(faces) != 0:
shape = predictor(image, faces[0])
face_descriptor = face_reco_model.compute_face_descriptor(image, shape)
else:
face_descriptor = 0
return face_descriptor
好了,当我们计算出每一个人物的特征均值以后,我们需要把当前人物的名称、特征均值一起写入到 CSV 文件里面,这样做的目的是方便我们后面做人脸识别:
def extract_features_to_csv(faces_dir):
mean_features_list = list(get_mean_features_of_face(faces_dir))
with open(FACES_FEATURES_CSV_FILE, "w", newline="") as csvfile:
writer = csv.writer(csvfile)
for mean_features in mean_features_list:
person_features = mean_features[0]
person_label = mean_features[1]
person_features = np.insert(person_features, 0, person_label, axis=0)
writer.writerow(person_features)
此刻,我们就拥有了一个简单的人脸数据库,对于任意一个待检测的人脸,我们只需要计算其特征值,然后再从人脸数据库中找到一个距离最小的特征即可:
def compare_face_fatures_with_database(database, image_path):
image = Image.open(image_path)
image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
faces = detector(image, 1)
campare_results = []
if len(faces) != 0:
for i in range(len(faces)):
face = faces[i]
shape = predictor(image, faces[0])
face_descriptor = face_reco_model.compute_face_descriptor(image, shape)
face_feature_distance_list = []
for face_data in database:
# 比对人脸特征,当距离小于 0.4 时认为匹配成功
dist = get_euclidean_distance(face_descriptor, face_data[1])
dist = round(dist, 4)
if dist >= FACES_FATURES_DISTANCE_THRESHOLD:
continue
face_feature_distance_list.append((face_data[0], dist))
# 按距离排序,取最小值进行绘制
sorted(face_feature_distance_list, key=lambda x:x[1])
if face_feature_distance_list:
person_dist = face_feature_distance_list[0][1]
person_label = face_feature_distance_list[0][0]
campare_results.append((person_label, person_dist))
return campare_results
可以注意到,我们会遍历人脸数据库中的每一个特征值,然后计算它和当前人脸特征的欧式距离。接下来,我们会对这些距离进行排序,选取距离最小的一组作为匹配结果,下面的代码片段展示了如何去计算一个欧氏距离:
def get_euclidean_distance(feature_1, feature_2):
feature_1 = np.array(feature_1)
feature_2 = np.array(feature_2)
return np.sqrt(np.sum(np.square(feature_1 - feature_2)))
如下图所示,我们可以输出每一张人脸的名称,以及当前人脸相对于特征均值的距离,经博主测试,这个方案的正确率可以达到 94.58% 左右,是一种相对比较靠谱的做法:

不过,这个方案的缺点同样非常明显,即:它必须遍历人脸数据库中的每一条数据,这意味着它的时间复杂度是 O(n)。考虑到现实生活中需要录入的人脸数据可能是成百上千的,这个方案的执行效率注定会越来越低,这迫使我们不得不换一种思路来解决这个问题。重新审视人脸识别这个问题,我们会发现,这其实是一个分类问题,就像我们人为地去给一堆照片贴上标签一样。当然,它并不是一个非此即彼的二分类问题,而是一个多分类的问题。如果你接触过 Scikit Learn,那么,你大概会想到通过某种分类器进行模型训练的思路,这里以支持向量机为例:
# 提取人脸特征和标签
mean_features_list = list(get_mean_features_of_face(faces_dir))
features = list(map(lambda x:x[0], face_encodings_mean_list))
labels = list(map(lambda x:x[1], face_encodings_mean_list))
# 通过支持向量机训练模型
clf = svm.SVC(C=1.0, kernel="linear", gamma='scale', probability=True)
clf.fit(features, labels)
在这种情况下,我们可以利用 joblib.dump() 和 joblib.load() 两个方法对模型进行保存和加载。此时,我们该如何识别一个人脸呢?简单来说,你可以把支持向量机想象成一个线性函数,因此,我们只需要传入待检测图片的特征值,它就可以帮我们计算/预测出人脸的分类。显然,它不需要像前面的方案一样遍历每一条人脸数据,因此,支持向量机这个方案执行效率上要更好一点:
features = get_128d_features_of_face(image_path)
predict_label = clf.predict(features)
当然,世界上没有百分之百完美的方案,支持向量机如果遇到了一张陌生的人脸,它的预测结果就会变得离谱起来,譬如,孙燕姿被识别为堺雅人、堺雅人被识别为胡歌,用鲁迅先生的话讲,屏幕内外充满了快活的空气。虽然,Scikit Learn 里可以用 predict_proba() 方法引入概率来评估结果的准确性,可博主实际使用下来,发现效果并没有好多少。无独有偶,OpenCV 自带的 LBPH 方法,其模型训练和这个思路非常地相似,无非是它接收是一个 Mat 类型的参数:
recognizer = cv2.face.LBPHFaceRecognizer_create()
detector = cv2.CascadeClassifier("haarcascade_frontalface_alt2.xml")
# 获取人脸样本及标签
face_samples = get_images_and_labels(DATASETS_DIR)
faces = list(map(lambda x:x[0], face_samples))
faceIds = list(map(lambda x:x[1], face_samples))
# 模型训练
recognizer.train(faces, np.array(faceIds))
recognizer.save('/train/train_data.yml')
# 模型预测
recognizer.read('/train/train_data.yml')
faceId, confidence = recognizer.predict(image)
它会返回人脸的 Id 以及置信度,我们可以结合这个置信度去做进一步的判断,比如置信度超过 50% 就认为它匹配到了人脸。我一开始提到这个方案的精度达不到要求,就是因为它经常给出错误的预测结果,甚至比支持向量机遇到陌生人脸时还要离谱。所以,对于 OpenCV 官方的这个方案呢,我们知道它是怎么回事就可以了,我个人并不推荐在真实的场景中使用这个方法。当然,OpenCV 后来开始支持 CNN,我们值得更好的人脸识别方案,限于篇幅和精力,这个等以后有机会了再展开说说。

本文小结
本文分享了 OpenCV 和 Dlib 下的人脸识别的实现,由于 OpenCV 自带的 LBPH 方法识别效果不符合预期,博主不得不使用 Dlib 来实现人脸识别。这里采用的思路是,计算出每一个人物的人脸特征均值,它是一个 128 维的向量,通过计算待检测人脸特征值与已知人脸特征值的欧式距离,来判断两张脸是否为同一张脸,经过测试,该方案的识别率可以达到 94.58% ,是一种相对来说比较靠谱的方案。考虑到这个方案的时间复杂度为 O(n) ,我们不得不考虑效率更高的做法。在这个基础上,我们尝试结合支持向量机做进一步的优化,支持向量机最大的问题时,当它面对一张陌生人脸的时候,其预测结果会变得非常离谱,可是在最好的情况下,它的准确率依然接近 97.04%。作为对照组,博主捎带着介绍了一下 OpenCV 自带的 LBPH 方法如何训练模型,权当帮大家扩展思路,只有此中的成败利钝,只有靠大家自己去取舍啦!最后,听说射雕英雄传又要翻拍啦,我宣布我永远都喜欢胡歌这一版的射雕英雄传,哈哈!


