当提及 ChatGPT 等生成式 AI 产品时,大家第一时间想到的是什么?对博主而言,印象最为深刻的是其流式输出效果,宛如打字机一般流畅。相信大家都注意到了,我给博客增加了 AI 摘要功能。虽然,这是一个非常“鸡肋”的功能,可是在光标闪烁的一刹那,我居然产生了一种“对方正在输入”的莫名期待。然而,此时此刻,理性会告诉我们:ChatGPT 的流式输出并不是为了让 AI 更“像”人类,它本质上是一种减少用户等待时长的优化策略。相比于人类的闪烁其词,心直口快或许更接近 AI 的真实想法。图灵测试,是一种用于判定机器是否具有智能的测试方法,其核心在于:如果程序表现出的行为与人类相似,我们便认为它具备了智能。当然,人机的不可区分性,同样带来了心理、伦理和法律上的问题。这便引出一个问题:人工智能,是否真的有必要像人类一样?有没有一种可能,让人工智能不那么地像人类,这反而是一种更加明智的做法?带着种种疑问,博主酝酿出了这篇文章,关于 ChatGPT 的流式传输,你需要知道的一切都在这里。从这一刻开始,“Attention Is All You Need”!
Server-Sent Events
目前,在众多生成式 AI 产品中,对话框依然是最普遍的产品形态。因此,当你准备开发一款 AI 应用时,实现“流式传输”功能是基本要求。正如矛盾先生所言,“模仿是创造的第一步”,所以,让我们先来看看 ChatGPT 是如何实现这个功能的。ChatGPT 早期使用的是 Server-Sent Events 技术来实现流式传输。然而,截止到博主写作这篇文章时,ChatGPT 中流式传输的实现已升级为 WebSocket。不过,这个话题还是值得探讨一下的,因为市面上依然有大量的项目在使用这个技术,我们姑且将其理解为,一笔由 OpenAI 引领而产生的技术债务。关于 Server-Sent Events 的基本概念,大家可以参考博主以前的博客 基于 Server-Sent Events 实现服务端消息推送:
下面,我们以 Kimi 为例来进行说明。通过观察浏览器的请求过程,足以一窥 Server-Sent Events 的个中奥妙。
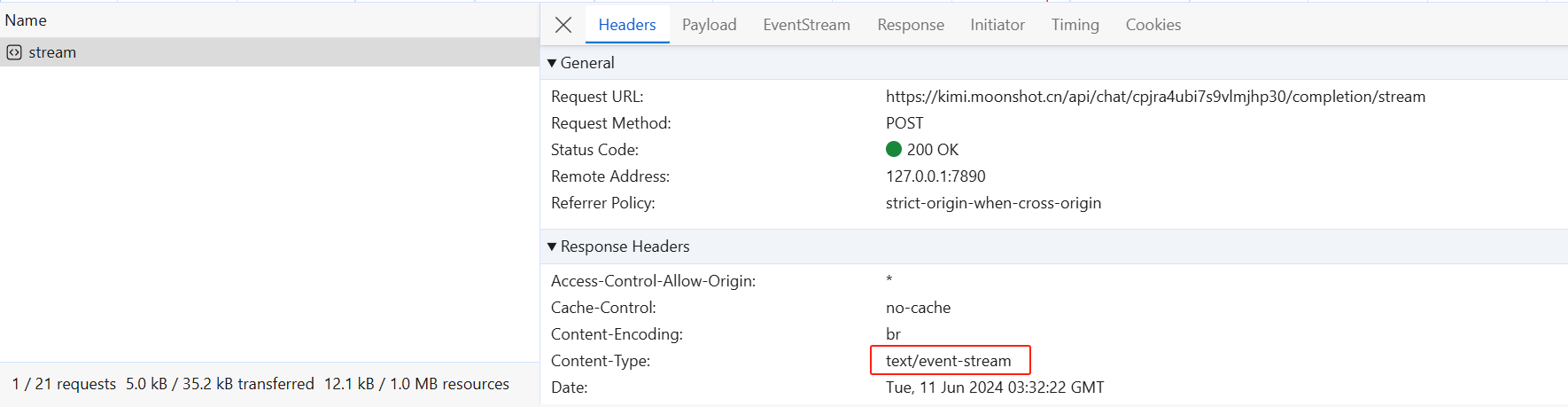
首先,Server-Sent Events 是基于 HTTP 协议的,其响应结果中的 Content-Type 取值为 text/event-stream。
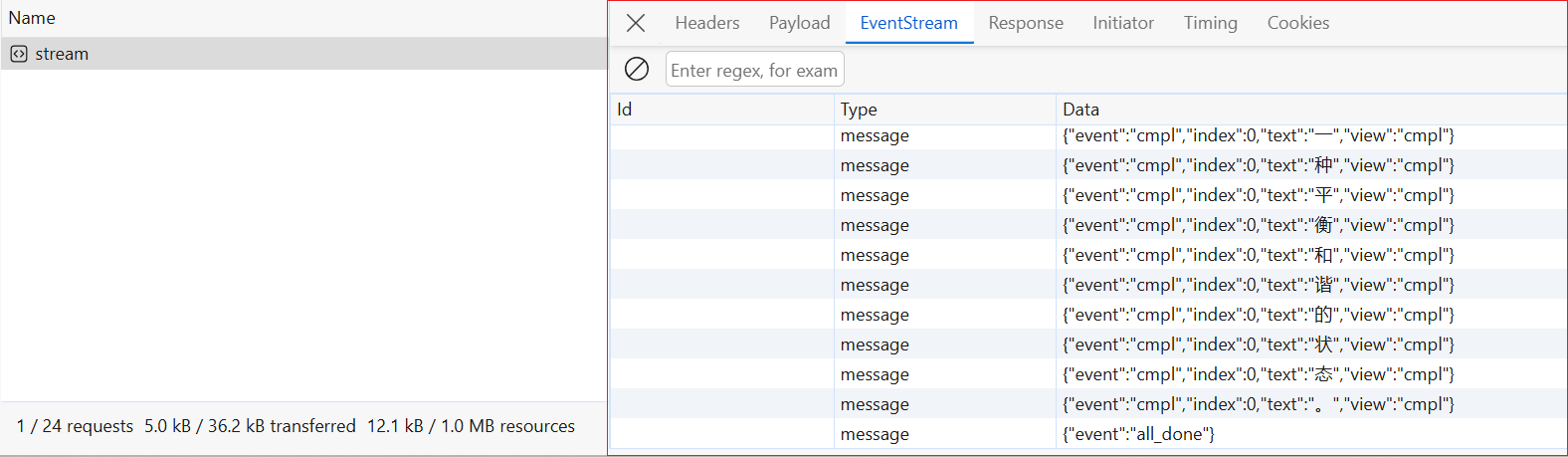
其次,Server-Sent Events 以事件流的形式向客户端返回数据,这些数据放在 Data 字段中。此时,客户端只需要从 Data 字段中提取内容,再将其显示到界面上即可,这样便可以快速地实现流式输出效果。按照这个思路,我们可以提供一个简单的实现,如下面的代码片段所示:
[HttpGet("streaming")]
public async Task StreamingAsync()
{
HttpContext.Response.ContentType = "text/event-stream";
foreach (var item in text)
{
var payload = JsonSerializer.Serialize(new { text = item.ToString() });
var message = $"data: {payload}\n\n";
await HttpContext.Response.WriteAsync(message, Encoding.UTF8);
await HttpContext.Response.Body.FlushAsync();
await Task.Delay(200);
}
await HttpContext.Response.WriteAsync("data: [DONE]");
await HttpContext.Response.Body.FlushAsync();
await HttpContext.Response.CompleteAsync();
}
接下来,我们只需要在客户端使用 EventSource API 即可,代码同样非常简单:
const eventSource = new EventSource('https://localhost:7261/api/chat/streaming');
const messageList = document.querySelector('#result');
messageList.innerText = ''
eventSource.onmessage = (e) => {
if (e.data != '[DONE]') {
messageList.innerText += JSON.parse(e.data).text
}
};
eventSource.onerror = (e) => {
eventSource.close()
}
由此,我们便可以实现下面的效果,这个效果和 ChatGPT 可以说是非常接近啦!

可惜,EventSource API 有一个致命的缺点:它仅支持通过 GET 方式发起请求,而在 ChatGPT 等聊天应用中通常需要以 POST 方式发起请求。如下面的代码片段所示,调用 OpenAI 的 Chat Completions 接口需要传递模型信息(model)、聊天历史信息(messages)、温度(temperature)等参数:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo-16k",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
此时,我们可以考虑使用 Fetch API 来解决这个问题。虽然微软提供了一个开箱即用的方案 Fetch Event Source,但是我建议大家最好还是亲自动手写一写。我承认,像 Axios 这样的第三方库固然非常好用,可一旦遇到这种不太常见的应用场景,你还是得回到 Fetch API 这种原生 API 上面,这再次印证了那句名言——没有银弹:
const response = await fetchWithTimeout('https://localhost:7261/api/chat/streaming', {
timeout: 1000 * 60 * 10,
method: 'POST',
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
let rawData = '';
while (true) {
const { done, value } = await reader.read();
if (done) { break }
rawData += decoder.decode(value);
while (rawData.indexOf('\n') != -1) {
const lineIndex = rawData.indexOf('\n');
const message = rawData.slice(0, lineIndex);
rawData = rawData.slice(lineIndex + 1);
if (message.startsWith('data: ')) {
if (message.includes('[DONE]')) { break }
const messageData = message.substring(5)
messageList.innerText += JSON.parse(messageData).text
}
}
}
这里使用了 Stream API 中的 ReadableStream 接口,它提供了一个getReader() 的方法,默认情况下,该方法返回一个 ReadableStreamDefaultReader 实例。这些术语听起来可能有些复杂,你可以将视为一种读取流数据的接口。每次调用 read() 方法时,就可以读取一部分数据。当返回的 done 属性为 true 时,表示读取完毕。由于读取出来的数据是二进制格式,我们还需要使用 TextDecoder 进行解码。此时,我们就可以突破 EventSource API 的限制,以 POST 的方式接入 SSE,具体示例见下图:

或许,大家会好奇这里的 fetchWithTimeout() 方法到底是什么来路?事实上,它们仅仅是对超时做了处理的 fetch() 函数的封装。对于其中的 AbortController,请允许在下先卖个关子,谜底稍后便会揭开:
async function fetchWithTimeout(resource, options = {}) {
const { timeout } = options;
const controller = new AbortController();
setTimeout(() => controller.abort(), timeout)
const response = await fetch(resource, {
...options,
signal: controller.signal
});
return response;
}
IAsyncEnumerable
在上述示例中,使用 StreamingAsync() 方法返回数据时,我们采用了 foreach 语法顺序写入数据。这意味着我们必须在获取到全部数据之后,才能逐个发送给客户端。设想一下,如果我们是通过调用第三方 LLM 服务来向客户提供 AI 服务,那是不是要等所有数据都收集完毕再返回给客户端呢?根据以往的经验,这种做法是可行的,客户在调用你的服务时,必须考虑到调用第三方接口所需的时间。然而,在生成式 AI 的时代,这个想法就点不合时宜。此时,IAsyncEnumerable 这个接口便派上了用场。下面,让我们通过一个示例来做进一步的了解:
// IEnumerable
public static async Task<IEnumerable<int>> GetNumbersByEnumerable(int count)
{
var numbers = new List<int>();
for (var i = 0; i < count; i++)
{
await Task.Delay(200);
numbers.Add(i);
}
return numbers;
}
// IAsyncEnumerable
public static async IAsyncEnumerable<int> GetNumbersByAsyncEnumerable(int count)
{
for (var i = 0; i < count; i++)
{
await Task.Delay(200);
yield return i;
}
}
其中,IAsyncEnumerable 是 C# 8.0 引入的一个接口,它允许以异步方式枚举集合。请看以下代码片段,你认为它的输出结果会是什么?毕竟这两段代码在功能上非常相似,都是遍历一个集合并输出其内容:
// 遍历 IEnumerable 打印
Console.WriteLine("IEnumerable: ");
foreach (var item in await GetNumbersByEnumerable(10))
{
Console.Write(item);
}
Console.WriteLine();
// 遍历 IAsyncEnumerable 打印
Console.WriteLine("IAsyncEnumerable: ");
await foreach (var item in GetNumbersByAsyncEnumerable(10))
{
Console.Write(item);
}
答案揭晓,结果非常的 Amazing 啊!尽管这两个方法都是异步的,可在打印时就可以明显地看出它们的差异:前者是一次性输出,而后者则是流式输出。我在不经意间完成了一次点题,更重要的是, 对于 IAsyncEnumerable 类型,你只需要为在其前面增加 async 关键词修饰即可,并不需要使用 Task 类型对其进行包装:
 Enumerable 与 AsyncEnumerable 对比
Enumerable 与 AsyncEnumerable 对比
可以说,这个类型天然地对 LLM 友好。例如,博主尝试通过 Ollama 接入 Mistral、Llama 3 等模型。条件受限,使用纯 CPU 进行推理。此时,如果调用非流式的接口无疑会花费大量时间,虽然我们可以在前端增加过渡动画,可这终究无法改变其生成慢的本质。此时,我们可以尝试下面的思路:首先调用流式接口,然后获取其响应流,再配合 IAsyncEnumerable 接口将其输出到 SSE 端点。下面是调用 Ollama API 接口的代码片段:
public async IAsyncEnumerable<string> ChatStreamAsync(OpenAIModel request)
{
using var httpClient = _httpClientFactory.CreateClient();
var httpRequest = new HttpRequestMessage(HttpMethod.Post, new Uri($"{_baseUrl}/v1/chat/completions"));
httpRequest.Content = new StringContent(JsonConvert.SerializeObject(request), Encoding.UTF8, "application/json");
var httpResponse = await httpClient.SendAsync(httpRequest, HttpCompletionOption.ResponseHeadersRead);
httpResponse.EnsureSuccessStatusCode();
using var responseStream = await httpResponse.Content.ReadAsStreamAsync();
using var reader = new StreamReader(responseStream);
var line = string.Empty;
while ((line = await reader.ReadLineAsync()) != null)
{
if (string.IsNullOrEmpty(line)) continue;
if (!line.StartsWith("data: ")) continue;
var data = line.Substring("data: ".Length);
if (data.IndexOf("DONE") == -1)
yield return JObject.Parse(data)["choices"][0]["delta"]["content"].Value<string>();
}
}
现在,我们便可以像下面这样实现基于 Server-Sent Events 的流式传输接口:
HttpContext.Response.ContentType = "text/event-stream";
await foreach (var item in ChatStreamAsync(new OpenAIModel(){ Model = "mistral:7b" }))
{
var payload = JsonSerializer.Serialize(new { text = item });
var message = $"data: {payload}\n\n";
await HttpContext.Response.WriteAsync(message, Encoding.UTF8);
await HttpContext.Response.Body.FlushAsync();
await Task.Delay(200);
}
await HttpContext.Response.WriteAsync("data: [DONE]");
await HttpContext.Response.Body.FlushAsync();
await HttpContext.Response.CompleteAsync();
从某种意义上讲,你可能会觉得,大模型的流式接口都可以使用 IAsyncEnumerable 类型来进行承载?这种感觉是完全正确的。实际上,在微软的 Semantic Kernel 项目中,就可以看到 IAsyncEnumerable 的应用:
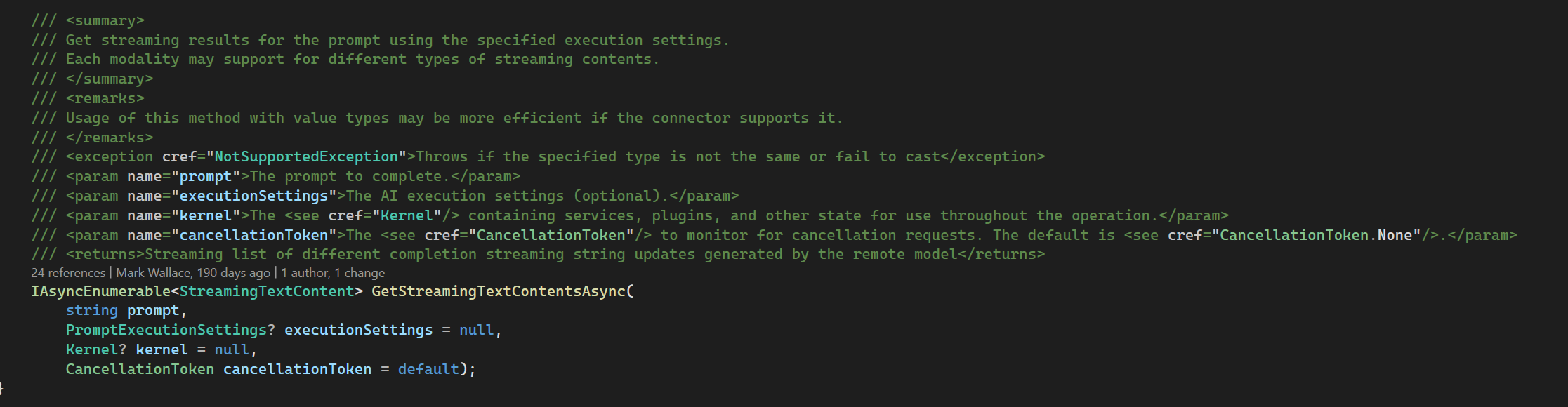 Semantic Kernel 中的 IAsyncEnumerable
Semantic Kernel 中的 IAsyncEnumerable
事实上,JavaScript 中的 异步生成器,无论其概念还是语法,皆与 IAsyncEnumerable 非常相似:
async function* foo() {
yield 'a';
yield 'b';
yield 'c';
}
let str = '';
async function generate() {
for await (const val of foo()) {
str = str + val;
}
console.log(str);
}
generate(); // "abc"
停止/取消生成
OK,对于流式传输这个话题,无论是前端还是后端部分,我想现在大家都可以做到得心应手啦。实际上,我们还有一个问题没有解决,那就是停止/取消生成。我发现,长时间处于舒适区,人们总不免会忽略某些问题。例如,在工作中习惯了 RESTful API 的我们,一旦需要通过 HttpClient 处理响应流,便可能感到困惑。对于前端开发者来说,调用 API 往往不会考虑取消操作,就像随意向天空开枪,结果嘛听天由命。可现在,这个问题在生成式 AI 中再次浮出水面,果然,“出来混还是要还的”。因此,接下来,我们将讨论在生成式 AI 里如何处理停止/取消生成的问题。
async function fetchWithTimeout(resource, options = {}) {
const { timeout } = options;
const controller = new AbortController();
setTimeout(() => controller.abort(), timeout)
const response = await fetch(resource, {
...options,
signal: controller.signal
});
return response;
}
我们还是以这段代码为例来进行说明,这里实例化了一个 AbortController,并在 fetch() 函数中传入了 signal 参数,该参数的类型为 AbortSignal。可以注意到,这个 signal 参数值来自 AbortController 的 signal 属性。由此,我们可以了解到:fetch() 函数的取消机制,需要搭配 AbortController 来使用,正如 .NET 里 Task 的取消需要搭配 CancellationToken 使用一样。下面是一个更为直观的代码示例:
const controller = new AbortController();
const signal = controller.signal;
fetch(url, {
signal: controller.signal
});
// AbortSignal 可以监听事件
signal.addEventListener('abort', () => console.log('abort!'));
controller.abort(); // abort()
console.log(signal.aborted); // true
特别地,对于 fetch() 函数超时问题的处理,更推荐使用下面的方式,因为 AbortSignal 里提供了一个静态方法:
const res = await fetch(url, { signal: AbortSignal.timeout(5000) });
至此,我们可以在前端页面实现对 Server-Sent Events 的取消/停止生成控制,如下图所示:
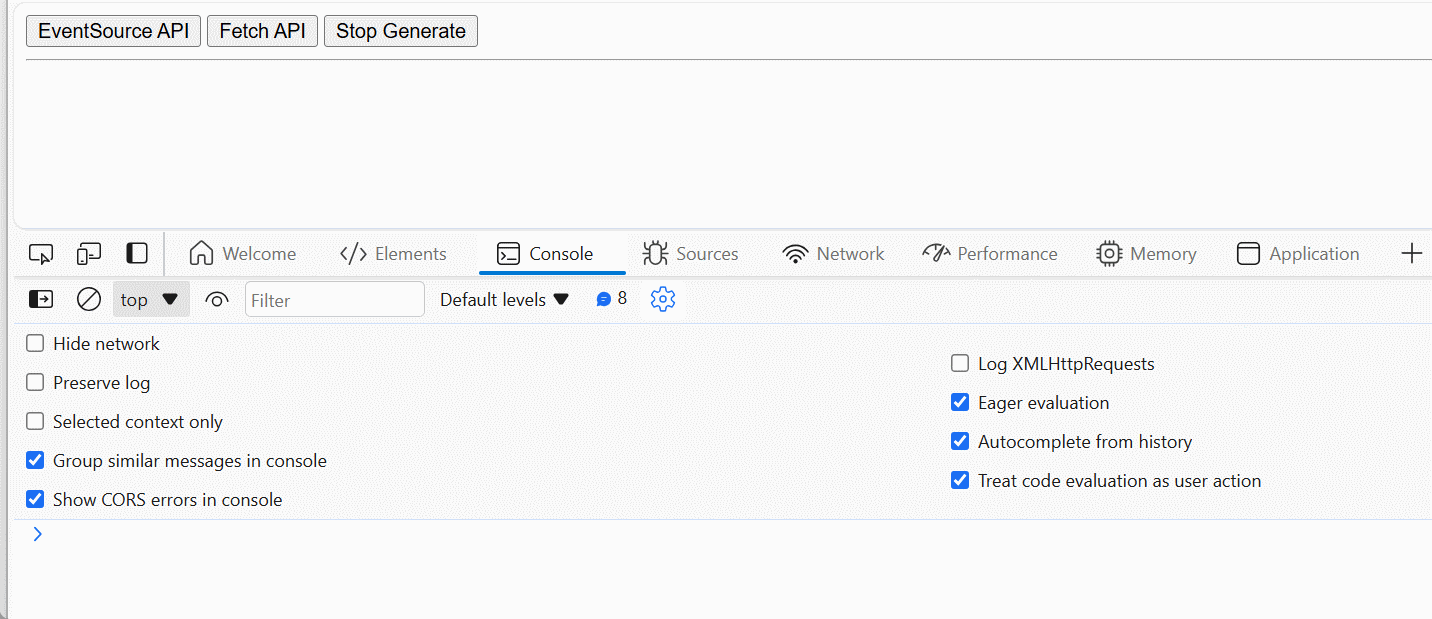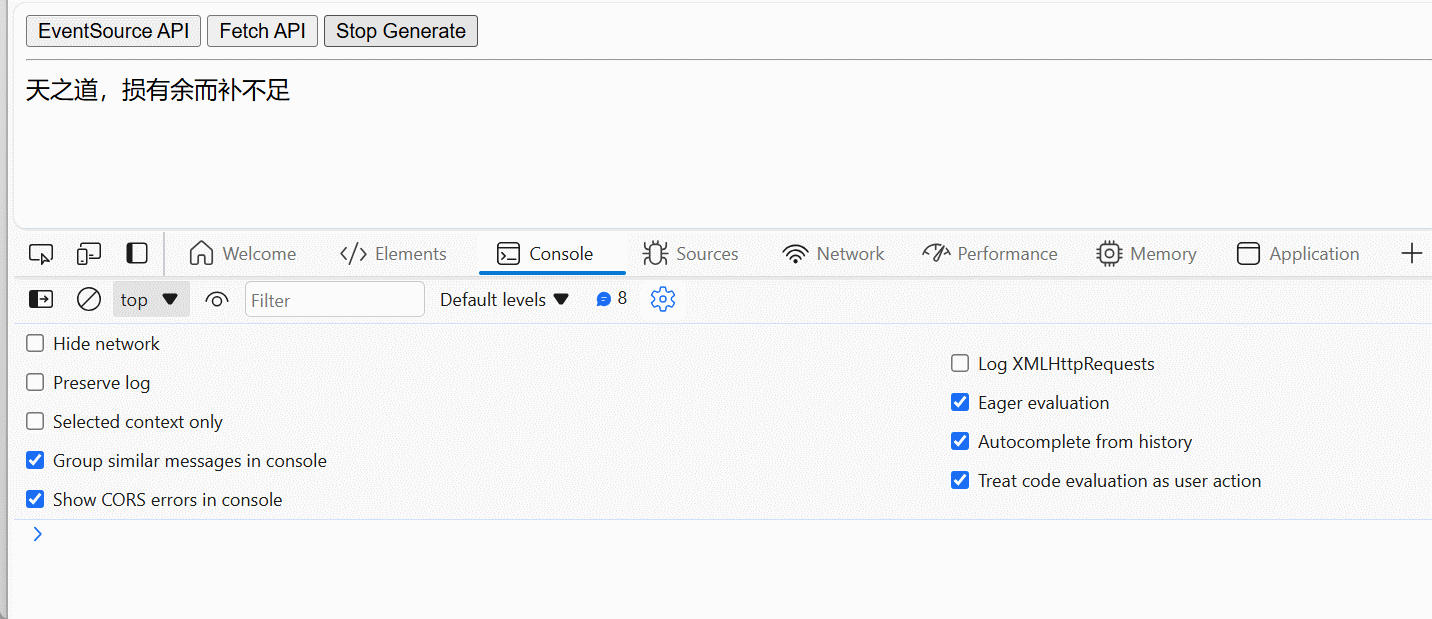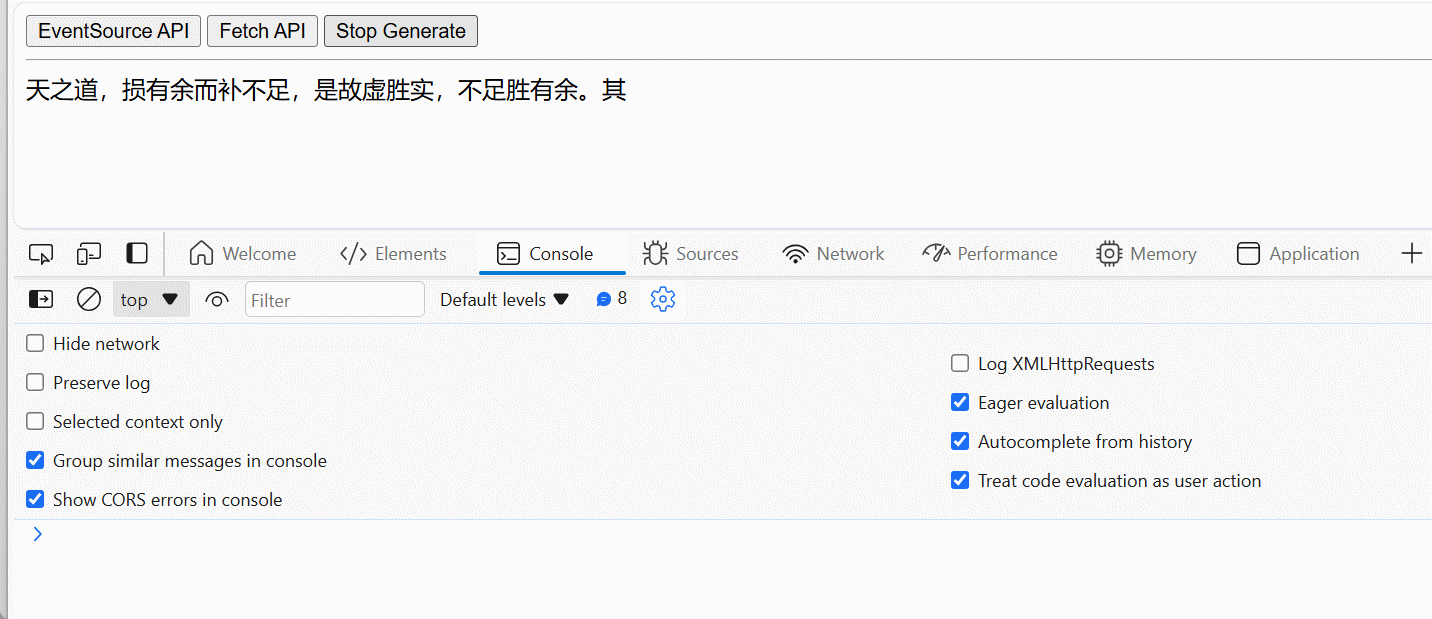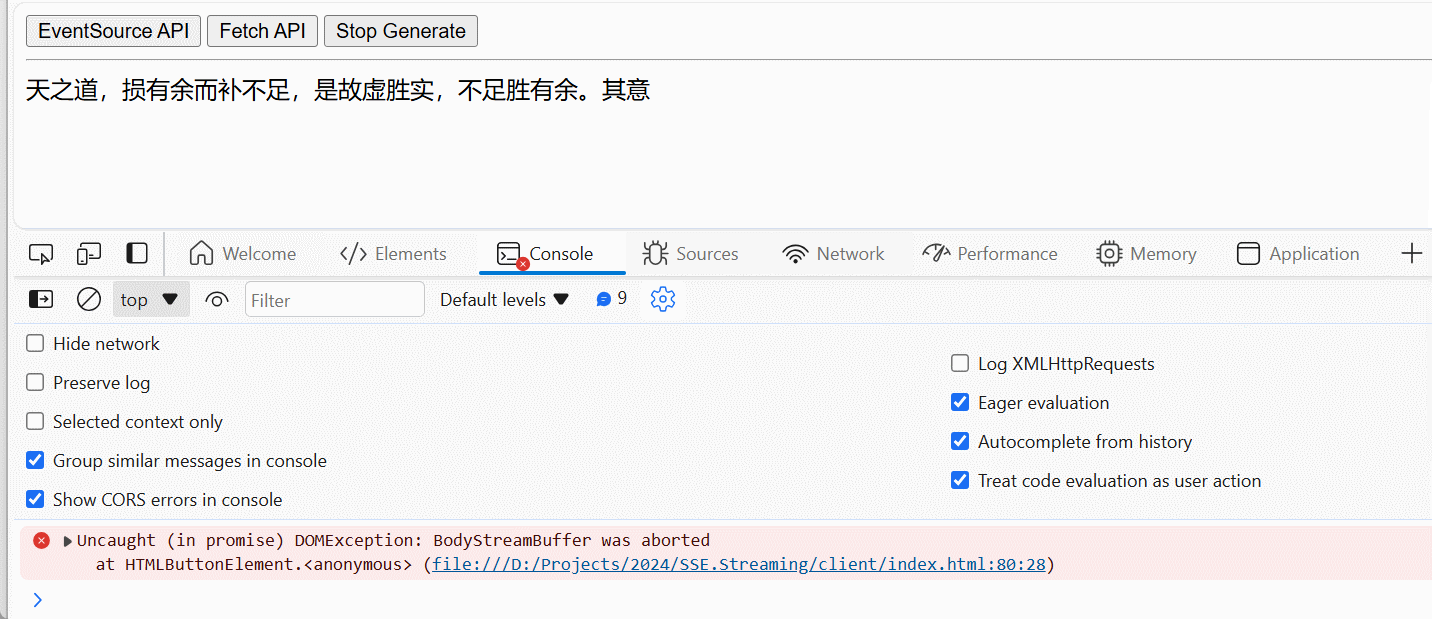 在前端部分实现对 Server-Sent Events 的取消/停止生成控制
在前端部分实现对 Server-Sent Events 的取消/停止生成控制
可是,这个问题是否就此结束?对于当下的生成式 AI 而言,其核心任务是依据用户输入生成符合预期的答案。那么,当用户从前端页面触发了取消/停止生成动作以后,其真正期望的是不再继续为当前输入生成答案。例如,用户的预期是生成一篇 800 字左右的高考作文,但是在 AI 生成了 200 多个字以后,用户决定取消/停止生成后续的内容,我们是否能真正地让这一切停下来?当我在 Axios 中看到 CancelToken 的设计时,我不由自主地将其和 .NET 中的 CancellationToken 相比较。可遗憾的是,当前端通过 AbortController 发起取消请求时,后端服务器通常不会自动感知到这个取消动作,甚至 HTTP 协议本身都不支持取消请求的标准机制。
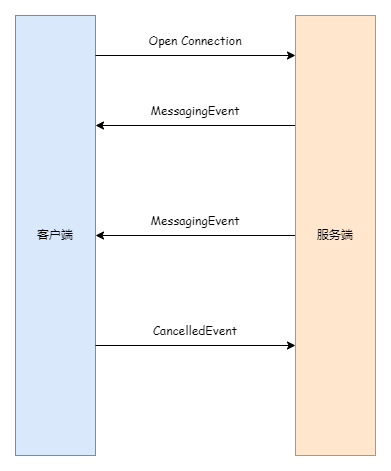
如图所示,博主设想了一种基于 WebSocket 的双向通信机制实现取消/停止生成的方案,当前端触发了取消/停止生成动作以后,后端调用 CancellationToken 的 Cancel() 方法,而这个令牌会被传递到文本生成流程中,当发现当前令牌被取消了以后便会引发异常,从而中止当前的文本生成流程。想法是挺美好的,代价是前端需要为每一次请求生成一个标识,并为每个标识映射一个 CancellationTokenSource。下面是一个基于 SignalR 的“拙劣”实现:
// 生成文本
public async Task Generate(string requestId, string prompt)
{
var cts = new CancellationTokenSource();
_cancellationTokens[requestId] = cts;
await foreach (var item in _textGenerator.Generate(prompt, cts.Token))
{
var message = JsonSerializer.Serialize(new { text = item })
await Clients.Caller.SendAsync("ReceiveChunks", message, requestId, cts.Token);
}
}
// 取消生成
public async Task Cancel(string requestId)
{
if (_cancellationTokens.TryGetValue(requestId, out var cts))
{
await cts.CancelAsync();
await Clients.Caller.SendAsync("GenerationCancelled", requestId);
_cancellationTokens.Remove(requestId);
}
}
本文小结
在与 Ollama 的 API 进行对接时,我发现使用流式 API 是一个不错的选择,因为结合着 IAsyncEnumerable 来使用的话,对于聊天体验的提升可以说是聊胜于无。在开发 AI 应用的过程中,我深刻体会到,当 AI 与人交流的时候,采用“流式传输”可以使人觉得 AI 真的有在思考,甚至有像人类一样组织着词句。然而,当 AI 与 API 交互时,“流式传输”可能会不太合适,特别是在 Function Calling 以及需要结构化输出的地方。Transformer 模型通过预测下一个词元来进行文本生成,其本质上与人类逐字发音、然后组成句子和段落的行为方式相似。唯一的区别在于,我们只有在写作的时候会按照某种结构去组织文本,除非我们需要带着讲稿在公众面前演讲,否则在任何情况下,我们基本上都是按照“流”的方式在传递信息。从这个视角来看,像 RESTful API 或者 RPC 那样按部就班的对话方式,可能并不是“正确”的选择。过去,我常被告知在群组里回复消息要及时,要用“好的”、“收到”这些词汇,现在回想起来,我只觉得风声中夹杂着荒诞呼啸而过。如你所见,在这篇博客里,我介绍了生成式 AI 里的基本功能——流式传输,从 Server-Sent Events 到 IAsyncEnumerable 再到 Fetch API 的取消机制,这些看似无关的想法被我串联在了一起,甚至写成了一篇文章。我不禁要怀疑,大模型的智能是否仅仅是文字的排列组合?而人类的知识是否仅仅是信息的高度压缩呢?


