注:本文在创作过程中得到了 ChatGPT、DeepSeek、Kimi 的智能辅助支持,由作者本人完成最终审阅。
在 “视频是不能 P 的” 系列文章中,博主曾先后分享过人脸检测、人脸识别等相关主题的内容。今天,博主想和大家讨论的是人脸分类问题。你是否曾在人群中认错人,或是盯着熟人的照片却一时想不出对方的名字?这种 “脸盲症” 的困扰,不仅在生活中令人感到尴尬,在整理照片时更是让人头疼不已。想象一下,某次聚会结束后,你的手机里存了上百张照片——有你的笑脸、朋友的自拍,甚至还有一部分陌生面孔混杂其中。手动将这些照片按人物分类,不仅费时费力,还可能会因为 “脸盲” 而频繁出错。此时,你是否期待有一种技术,可以像魔法一样,自动将这些照片按人物分类?事实上,这种 “魔法” 已经存在,它的名字叫做 K-Means 聚类分析。作为一种经典的无监督学习算法,K-Means 能够通过分析人脸特征,自动将相似的面孔归类到一起,完全无需人工干预。接下来,为了彻底根治 “脸盲症”,我们将详细介绍如何使用 K-Means 聚类分析来实现这一目标,哈利·波特拥有魔法,而我们则拥有科技。
实现过程
如图所示,我们将按照下面的流程来达成 “自动分类人脸” 这一目标。其中,Dlib 负责提取人脸特征向量、Scikit-Learn 中的 K-Means 负责聚类分析、Matplotlib 负责结果的可视化:
K-Means 简介
K-Means 是一种广泛应用的聚类算法,其基本原理是将数据集分成 K 个簇,目标是让每个簇内的数据点尽可能相似,而不同簇之间的数据点尽可能差异明显。K-Means 的执行过程如下:
随机选取 K 个初始中心点。
将每个数据点分配到距离最近的中心点所对应的簇。
更新每个簇的中心点,通常取簇内所有数据点的均值。
重复步骤 2 和 3,直到中心点不再发生变化或达到预设的最大迭代次数。
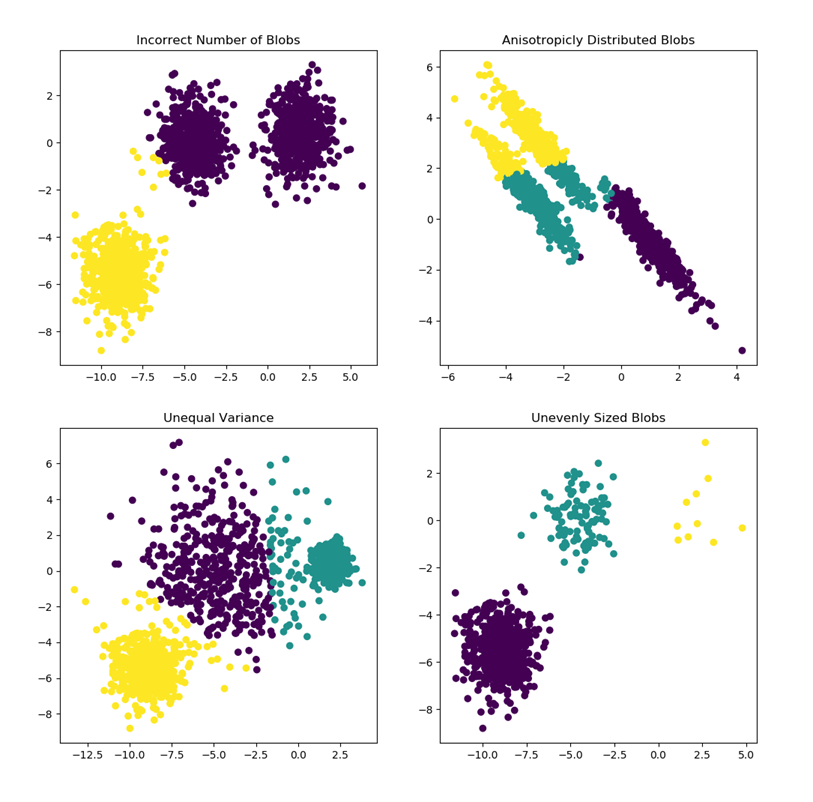
如下图所示,图中展示了四种不同的聚类数据分布情况,按照从左到右、自上而下的顺序:
- 图一:簇划分不正确或者簇数量假设错误
- 图二:数据分布具有各向异性,簇的形状是一个拉长的椭圆形,而不是对称的圆形
- 图三:各个簇之间的方差不同,绿色簇分布更紧密,而黄色簇分布更稀疏
- 图四:簇的大小不均匀,黄色簇数据点较少,而紫色簇数据点较多
因此,适用于 K-Means 的数据通常满足:
- 簇是球状且分布均匀
- 簇的大小相近
- 簇无明显噪声点或者离群点
- 数据是各向同性分布
- 簇的数量已知
- 数据维度适中
如何确定 K 值
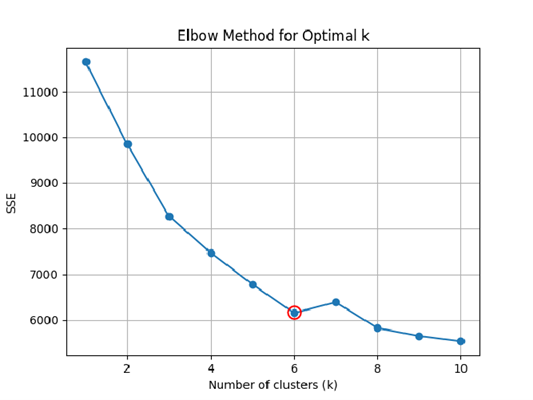
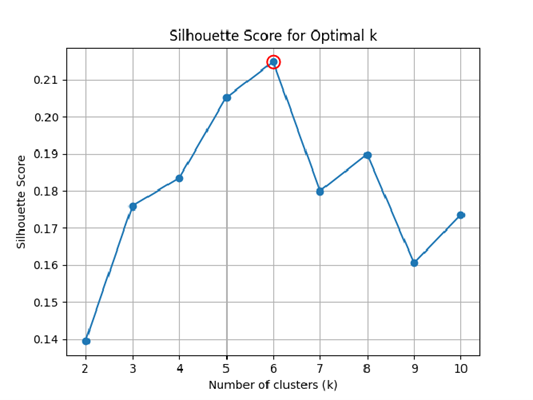
在使用 K-Means 之前,我们需要确定 K 值,即簇的数量。下面是三种常用的确定 K 值的方法:
- 肘部法则/手肘图法(Elbow Method):通过计算不同 K 值下的聚类误差平方和(SSE, Sum of Squared Errors),找到误差下降速度明显减缓的 “拐点”,这个拐点对应的 K 值即为最佳聚类数。
- 轮廓系数法(Silhouette Coefficient):通过计算每个数据点的轮廓系数,评估聚类效果,选择轮廓系数最大的 K 值。轮廓系数结合了聚类的紧密度(同一簇内样本的相似度)和分离度(不同簇之间的差异度)。
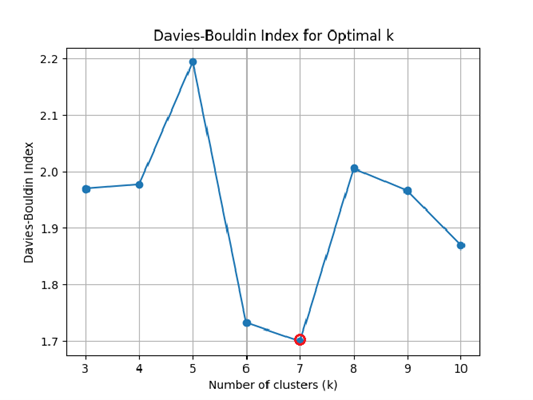
- 戴维斯-博尔丁评分(Davies-Bouldin Index):通过计算每个簇的簇内距离(样本到簇中心的平均距离)与簇间距离(不同簇中心之间的距离)的比值,评估聚类效果,选择评分最低的 K 值。
如图所示,分别展示了不同方法下的最佳 K 值,综合考虑三种评估方案,此处取 K=6:
提取人脸特征
为了对人脸照片进行聚类,我们首先需要提取人脸特征。为此,我们使用 Dlib 库,它提供了一个基于深度学习的预训练模型,该模型能够高效地将人脸图像转换为 128 维的特征向量。
import dlib
import cv2
import numpy as np
# 加载人脸检测器和特征提取器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("./models/shape_predictor_68_face_landmarks.dat")
face_model = dlib.face_recognition_model_v1("./models/dlib_face_recognition_resnet_model_v1.dat")
# 提取人脸特征
def extract_face_features(image_path):
img = cv2.imread(image_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(gray)
if not faces:
return None
max_face = max(faces, key=lambda rect: rect.width() * rect.height())
shape = predictor(gray, max_face)
feature = face_model.compute_face_descriptor(img, shape)
return np.array(feature)
K-Means 聚类
接下来,在提取了人脸特征值后,我们可以使用 Scikit-Learn 中的 K-Means 方法进行聚类:
from sklearn.cluster import KMeans
X, image_paths = load_dataset(dataset_path)
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 使用 K-means 进行聚类
num_clusters = 6
kmeans = KMeans(n_clusters=num_clusters, n_init=50, random_state=42, init='k-means++')
kmeans.fit(X)
# 获取聚类标签
labels = kmeans.labels_
其中,load_dataset() 方法用于返回特征值和图片路径,因为最终我们需要将这些图片移动到不同的文件夹中,以实现图片分类。下面是该方法的具体实现:
def load_dataset(dataset_path):
results = [
(features, image_path)
for image_name in os.listdir(dataset_path)
if (image_path := os.path.join(dataset_path, image_name))
and (features := extract_face_features(image_path)) is not None
]
X, image_paths = zip(*results) if results else ([], [])
return np.array(X), list(image_paths)
这里,简单说一下各个参数对于 K-Means 的影响:
- 使用 StandardScaler 对矩阵 X 进行标准化处理,将每一列的均值调整为 0,标准差调整为 1。标准化后的数据更适合 K-Means 聚类,因为 K-Means 对特征的尺度比较敏感。
- 参数
n_clusters取值为 6,表示将数据分为 6 个簇,该值由最佳的 K 值确定。 - 参数
n_init取值为 50,表示运行 K-Means 的次数,每次将使用不同的初始质心,确保可以得到最优结果。 - 参数
random_state取值为 42,设置随机种子,确保结果可以复现。 - 参数
init取值为k-means++,表示使用 K-Means++ 算法初始化质心,避免陷入局部最优。
更多的参数及细节,请参考官方文档:https://scikit-learn.org.cn/view/108.html#2.3.2.%20K-means
PCA 降维与可视化
理论上,这一步可以省略。不过,为了更加直观地展示聚类结果,我们可以使用 PCA(Principal Component Analysis,主成分分析)对人脸特征进行降维,将高维特征映射到低维空间。在本文中,我们会将 128 维的特征向量映射到 2 维平面,并通过 Matplotlib 库进行可视化展示,其中的关键代码展示如下:
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from matplotlib.offsetbox import OffsetImage, AnnotationBbox
# 使用 PCA 降维到 2 维
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)
# 获取聚类质心
centers = kmeans.cluster_centers_
centers_reduced = pca.transform(centers)
# 绘制每个聚类的散点
plt.figure(figsize=(12, 10))
# 对于每个聚类,绘制聚类的点和代表性图片
for cluster in range(num_clusters):
cluster_mask = labels == cluster
cluster_points = X_reduced[cluster_mask]
# 获取降维后的聚类中心坐标
x_center, y_center = centers_reduced[cluster] # 每个聚类的二维坐标
# 绘制聚类中的数据点
plt.scatter(cluster_points[:, 0], cluster_points[:, 1], label=f'Cluster {cluster}')
# 选择每个聚类中最接近聚类中心的图像
cluster_indices = np.where(cluster_mask)[0]
distances = np.linalg.norm(X_reduced[cluster_mask] - centers_reduced[cluster], axis=1)
closest_image_idx = cluster_indices[np.argmin(distances)]
closest_image_path = image_paths[closest_image_idx]
# 读取并处理该图片
img = extract_face_rect(closest_image_path)
h, w = img.shape[:2]
# 设定目标图像大小
target_size = 100
aspect_ratio = w / h
# 根据长宽比计算新宽高
if aspect_ratio > 1:
new_w = target_size
new_h = int(target_size / aspect_ratio)
else:
new_h = target_size
new_w = int(target_size * aspect_ratio)
# 调整图片大小
img_resized = cv2.resize(img, (new_w, new_h))
# 在聚类中心绘制代表性图片
imagebox = OffsetImage(img_resized, zoom=0.5)
imagebox.image.axes = plt.gca()
ab = AnnotationBbox(imagebox, (x_center, y_center),frameon=True,pad=0.5)
plt.gca().add_artist(ab)
# 绘制聚类中心
plt.scatter(centers_reduced[:, 0], centers_reduced[:, 1], c='red', marker='X', s=200, label='CentroIds')
# 标题、标签和图例
plt.title('K-means Clustering Results (PCA Reduced)')
plt.xlabel('PCA Dimension 1')
plt.ylabel('PCA Dimension 2')
plt.legend()
plt.grid(True)
plt.show()
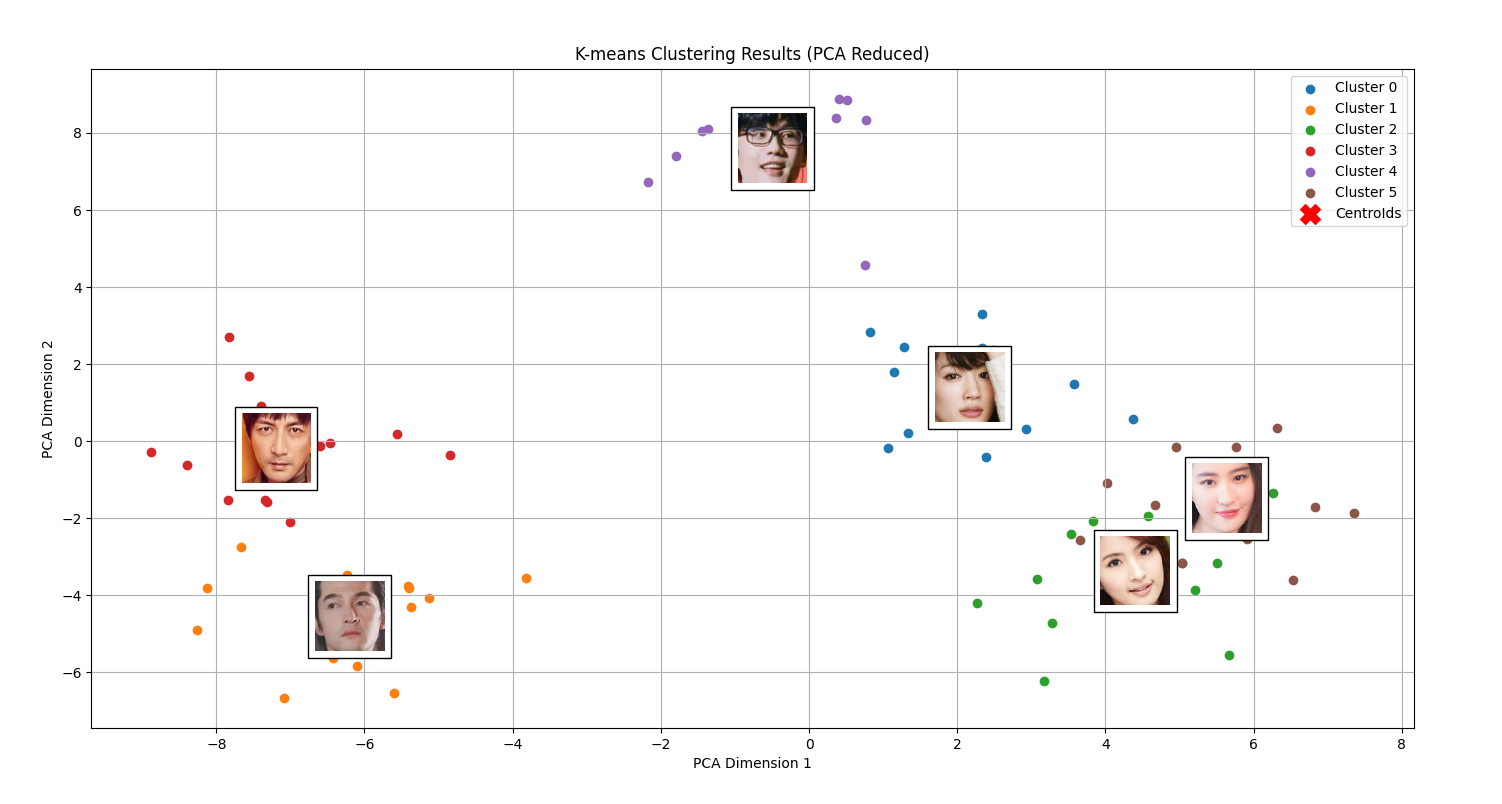
这段代码看起来非常复杂,它具体做了什么事情呢?实际上,在通过 K-Means 聚类获得分类标签以后,我们开始尝试在每个簇的中心绘制一张人脸图片,这张图片是如何找到的呢?这里我们选取的的是离簇中心最近的那张图片。考虑到,通过 Dlib 提取的人脸特征值都是 128 维的,如果希望将其绘制到二维平面上,就需要通过 PCA 来完成降维。如图所示,通过 PCA 降维后,我们可以将聚类结果可视化。不同颜色代表不同的簇,同一簇内的点表示相似的人脸照片。通过这张图片,相信你会更加直观地理解核心点、边界点、聚类中心、重叠点等概念:
本文小结
本文尝试探索运用 K-Means 聚类技术对人脸照片进行快速分类的方案。首先,我们介绍了 K-Means 的基本原理及其适用范围,并探讨了如何合理确定簇数 K。随后,博主详细阐述了人脸特征的提取方法、K-Means 聚类的具体实施步骤,以及借助 PCA 降维技术实现数据可视化的流程。这一系列步骤帮助我们高效地对大量人脸照片进行分类。然而,K-Means 并非完美无瑕。它需要预先设定簇数 K,对初始中心点的选择较为敏感,且默认簇为球形或凸形。这导致其在处理非凸形簇或含噪声数据时表现不佳。针对这些局限性,实际应用中可以考虑使用 DBSCAN 等聚类算法,这类方法通常能够自动确定簇的数量,并对噪声数据具有更强的适应性。作为一种经典的聚类算法,K-Means 具有计算高效、实现简单的优点。然而,在普适性、精确度以及对深度特征的利用上,相较于基于深度学习的聚类方法,K-Means 存在一定不足。本文旨在为读者提供一种基础思路,激发其对于聚类分析这一领域的兴趣。本文代码已上传至 Github,更多细节请参考:https://github.com/Regularly-Archive/2024/blob/main/face-classify/kmeans_cluster_classify.py。


