在刘慈欣老师的《三体》小说中,整个故事是以杨冬的死亡线索展开的,而她自杀的原因是物理学不存在了。随着 GPT-4 的发布,『NLP已死』和『NLP不存在了』的声音开始不绝于耳。如果说杨冬认为物理学被颠覆源于智子的“欺骗”,那么,现在的大型语言模型对于 NLP 的冲击,实际上改变了AI与最终用户互动的方式。传统的 NLP 技术方向涵盖了信息抽取、文本挖掘、机器翻译、语音合成、语音识别、语义理解、句法分析,这些都被视为自然语言处理的中间任务。因此,传统的 NLP 模式是在每个领域中提供各种不同的工具。当需要对自然语言进行处理时,你不得不将这些不同的工具结合起来,就像博主曾经使用过的结巴分词、SnowNLP、词袋模型、情感分析、TF-IDF一样。然而,现在的大型语言模型更像是一个直接面对最终任务的“智者”,跳过了这些中间任务。因为我们最终的目的就是要让程序产生智能,并让人类相信它能够“理解”他们的意图。显然,在这一点上,ChatGPT 和 Midjourney 都做到了。作为非科班的程序员,我无法科学、客观地评判 LLM 和 NLP 的优劣。但是我想分享一下我在开发 “贾维斯” 过程中获得的一点心得,希望对大家有所启发。
Hey Jarvis
在将小爱同学接入 ChatGPT 以后,我开始思考怎么样在智能和功能上取得平衡,尽管 ChatGPT 提升了小爱同学在聊天方面的智能,可这同时破坏了当下智能音箱普遍使用的“指令集”,你无法运用 ChatGPT 的这种“聪慧”让它真正地帮你做点事情。所以,我大概率要再次发明“智能音箱”,可我想知道,有了 ChatGPT 的加持以后,它到底能达到什么样的智能水平?带着这样一个想法,我开始从头编写贾维斯,一个基于 ChatGPT 的人工智能管家,其灵感来源于钢铁侠的人工智能管家 Jarvis。目前,它可以查询日期/时间、检索信息、播放音乐、控制米家/电脑、打开应用、讲笑话、查询天气、编程。以下是我在 Bilibili 上发布的视频演示:
你可能会好奇这些功能都是如何实现的?请允许我做一个简单说明,下面是“贾维斯”的整体设计思路:
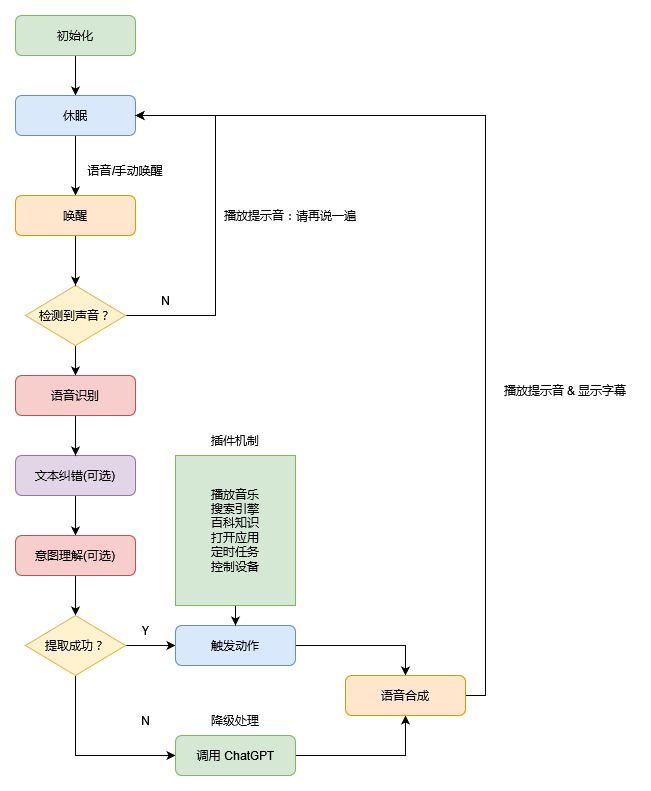
从整体而言,整个程序并不算特别复杂,因为语音唤醒、语音识别、语音合成这些均已有非常成熟的方案。在接入 ChatGPT 以后,我开始尝试为它扩展更多的功能。这个时候,我了解到自然语言理解(NLU)的这个方向,并且它依然属于自然语言处理(NLP)这个范畴,更具体的关键词则是意图识别或者意图提取。以查询日期这个功能为例,我只需要在某个函数上添加“路由”,即可为贾维斯设计不同的“技能”:
@trigger.route(keywords=['查询日期','询问日期','日期查询'])
def report_date(input):
now = datetime.datetime.now()
week_list = ['星期一','星期二','星期三','星期四','星期五','星期六','星期日']
formated = now.strftime('%Y年%m月%d日')
week_day = week_list[now.weekday()]
history = today_on_history()
if history != None:
return f'今天是{formated},{week_day}。{history}。'
else:
return f'今天是{formated},{week_day}。'
此时,问题就被转化为如何识别或者提取一句话中的真实意图。坦白地讲,面对人类这种口是心非的动物,想要了解其真实意图是非常困难的。譬如,人类都希望别人能够“懂我”,可没有人会喜欢被别人一眼看穿。因此,我们这里讨论的意图,特指那些动宾结构的指令型用语,例如:打开客厅的灯、查询明天的天气等等。不论屏幕前的你对 AI 持何种态度,我想说的是,AI 已然参与到我日常的编程和写作中,这正是我开发贾维斯的动力所在,我希望它能参与到更多的事项中去,甚至想让它取代家里的小爱同学。
基于 ChatGPT 实现意图提取
对笔者而言,在接触到 ChatGPT 以后,编程语言就仿佛进入了一个新的时代——魔法时代。因为无论你需要大语言模型帮你做什么,你要做的第一件事情就是编写 Prompt。而关于这件事情本身,则像极了魔法师在施法前吟唱咒语。所以,你说未来会出现那种被称之为“魔法吟唱师”的职业吗?当然,更有意思的点在于,如果说目前的编程语言都是过程式的,那么,在进入魔法时代以后,这一切就会变成描述式的。关于意图提取这个话题,你打算怎么样向 AI 解释它呢?下面开始我的尝试:
我想让你扮演我的自然语言处理工具,当我告诉你一句话的时候,你可以对它进行分词、句法分析、词性分析、上下文分析、主题建模/抽取,你可以自由地使用结巴分词、nltk 或者是 SnowNLP 这些工具,你需要猜测我这句话中的意图,并用下面的形式表示出来:
{ "query": "查询许嵩的资料", "intent": { "name": "查询", "confidence": 0.95 }, "entities": [ { "entity": "name", "value": "许嵩", "start": 2, "end": 4, "confidence": 0.98 }] }其中,
query字段表示原始查询文本,intent字段表示查询意图,entities字段表示本次查询中提取的实体信息。在这个示例中,意图为查询,置信度为0.95,实体为人名,值为“许嵩”,起始位置为2,结束位置为4,置信度为0.98。你只需要返回给我这样一段 JSON,不需要任何冗余的信息。需要注意的是,你要对相似的意图进行归类和合并,使用一个统一的意图进行描述。我的问题是:
如你所见,这是一段非常复杂的提示词,采用了经典的 Markdown 格式,借此告诉 ChatGPT 它需要做什么样的事情、以及期望它返回的数据格式。通常情况下,我们可以使用 requests 库来调用 ChatGPT 的 API 接口:
# 一个小技巧,使用三个单引号来处理多行文本
prompt = '''在这里填入你的提示词'''
# 定义请求头
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <Your OpenAI API KEY>",
}
# 定义请求体
query = '播放许嵩的断桥残雪'
query = prompt + query
payload = {
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": query}]
}
# 调用 ChatGPT API
r = requests.post('https://api.openai.com/v1/completions', headers=headers, json=data)
data = r.json()
content = data.get("choices")[0]["message"]["content"]
# 由于返回的是 JSON,需要再做一次反序列化
result = json.loads(content)
在将我的指令和提示词一起发送给 ChatGPT 后,我实际上获得了一个具备意图提取能力的 API 接口。虽然我没有使用传统 NLP 工具或技术,但我确实实现了类似的功能。我测试过 ChatGPT 的英文翻译效果,发现它的翻译效果甚至比主流的翻译工具要好很多。因此,无论传统 NLP 如何努力,似乎都难以与之匹敌,这大抵解释了为什么人们会发出“NLP已死”的声音。你还记得刘慈欣老师书中的“降维打击”这一概念吗?传统 NLP 一直致力于优化模型和算法,即使 GPT 使用的技术并不算先进。然而,在海量数据和大规模算力面前,GPT 最终呈现出来的效果比这些方案要好得多,这确实是一种奇迹。以下是博主通过 ChatGPT 提取出来的意图:

那么,这个方案是否就完美无缺呢?答案显然是否定的,一个最为明显的问题是,ChatGPT 对意图的分类非常随意,例如,查询日期和日期查询,是同一种含义的不同表达,属于近义词,可是 ChatGPT 并不会主动合并这些相似的结果,即使你在提示词中已经提及了这一点。那么,该如何优化这个问题呢?一种可行的方案是在提示词中告诉它你期望的意图分类,如信息查询、天气查询、设备控制…等等。除此之外,这段提示词的长度大概为1000个字符,大概会消耗 100 至 200 个左右的 Token,虽然支持多模态的 GPT-4 变得更强大了,可它的价格是 GPT-3.5 的 15 到 60 倍左右,因此,从经济成本考虑,这个基于 ChatGPT 的意图提取方案,在未来产生的费用可能会越来越高。当然,如果你能训练出比 GPT-3.5 更强大的大语言模型,这个问题就不再是一个问题啦!
基于 Rasa NLU 实现意图提取
也许,你在视频注意到了,当我向贾维斯下达控制智能家居的指令时,有时候它并不能正确地理解我地意图。于是,我开始尝试回归到传统 NLP 的思路。在这个过程中,我了解到了 Rasa NLU 这个项目,这是一个致力于构建 AI 助手的开源框架,你可以提供它提供的各种能力训练出一个聊天机器人。当然,我最感兴趣的还是它提供的自然语言理解(NLU)能力,我打算借助于这一框架,训练出一个可以离线使用的意图提取器。因为只有这样,你才能深刻地理解 LLM 和 NLP 的区别在哪里。参照官方教程,在正式开始训练前,你至少应该做好以下准备:
- 一个 Python 3.9 的环境,建议使用
virtualenv来管理你的虚拟环境 - 安装 CMake 环境,建议将其添加至操作系统环境变量中
- 下载中文词向量模型文件 total_word_feature_extractor_zh.dat,提取码:g54u
接下来,安装必要的依赖项。其中,MITIE 建议通过源代码来安装:
python -m pip install rasa jieba scikit-learn
# 从源代码安装 MITIE,直接安装失败率非常高
python -m pip install git+https://github.com/mit-nlp/MITIE.git
Rasa 的训练主要分为 Core 和 NLU 两个部分。其中,Core 这部分主要用于聊天机器人的训练,换句话说,只有当你需要实现一个功能完备的聊天机器人的时候,你才需要针对这部分进行训练。考虑到,我们这里仅仅是为了使用 Rasa 提供的 NLU 能力。因此,我们只需要训练 NLU 这部分即可。下面是笔者参照官方文档编写的训练数据, 在 Rasa 1.0 以及 Rasa 2.0 版本中,通常使用 JSON 和 Markdown 格式来编写训练数据,而在 Rasa 3.0 中,我们有了新的选择——YAML,下面是一个简单的示例:
version: "3.1"
nlu:
- intent: greet
examples: |
- 你好
- 哈喽
- 嗨
- 嘿
- 早上好
- 晚上好
- 早安
- 晚安
- intent: query_weather
examples: |
- [今天]{"entity": "date"}的天气怎么样
- [明天]{"entity": "date"}的天气怎么样
- [后天]{"entity": "date"}的天气怎么样
- [今天]{"entity": "date"}下雨吗
- [明天]{"entity": "date"}下雨吗
- [后天]{"entity": "date"}下雨吗
- [今天]{"entity": "date"}的气温是多少
- [明天]{"entity": "date"}的气温是多少
- [后天]{"entity": "date"}的气温是多少
- 帮我查询一下[今天]{"entity": "date"}的天气
- 帮我查询一下[明天]{"entity": "date"}的天气
- 帮我查询一下[后天]{"entity": "date"}的天气
- intent: query_time
examples: |
- 几点了
- 现在几点
- 告诉我[时间]{"entity": "time"}
- 查询[时间]{"entity": "time"}
- intent: query_date
examples: |
- [今天]{"entity": "date"}几号
- [明天]{"entity": "date"}几号
- [后天]{"entity": "date"}几号
- [今天]{"entity": "date"}周几
- [明天]{"entity": "date"}周几
- [后天]{"entity": "date"}周几
- [今天]{"entity": "date"}星期几
- [明天]{"entity": "date"}星期几
- [后天]{"entity": "date"}星期几
- 查询[日期]{"entity": "date"}
- intent: search_info
examples: |
- 搜索[周杰伦]{"entity": "name"}的信息
- 查询[刺客信条]{"entity": "name"}的资料
- 检索[许嵩]{"entity": "name"}的情况
完整的训练数据可以在 这里 找到,你可以注意到,在训练数据中博主手动标注出了一部分实体,你必须确保这些词语能被分词组件正确地切分。这一点如何保证呢?事实上,Rasa 采用管道的形式来组织各种各样的组件,例如,在 Rasa 中你可以使用 JiebaTokenizer 或者 MitieTokenizer 对训练数据进行分词。编写 Rasa 配置文件,本质上就是决定选择哪些组件来处理你的训练数据。为了方便大家理解,我做了一个简单的表格供大家参考:
| 分类 | 组件 | 描述 |
|---|---|---|
| NLP | MitieNLP、SpacyNLP | 在管道中加载一个预训练的词向量模型 |
| Tokenizers | WhitespaceTokenizer、JiebaTokenizer、MitieTokenizer、SpacyTokenizer | 在管道中使用分词组件,对训练数据进行分词 |
| Featurizers | MitieFeaturizer、SpacyFeaturizer、ConveRTFeaturizer、LanguageModelFeaturizer、RegexFeaturizer、CountVectorsFeaturizer、LexicalSyntacticFeaturizer | 在管道中使用特征化组件,对文本特征进行分类 |
| Intent Classifiers | MitieIntentClassifier、LogisticRegressionClassifier、SklearnIntentClassifier、KeywordIntentClassifier、DIETClassifier、FallbackClassifier | 在管道中使用意图分类器,识别输入内容的意图 |
| Entity Extractors | MitieEntityExtractor、SpacyEntityExtractor、SpacyEntityExtractor、DucklingEntityExtractor、RegexEntityExtractor、EntitySynonymMapper | 在管道中使用实体提取器,提取输入内容中的实体 |
经过反反复复的训练和测试,博主找到了下面这套最合适的配置文件:
language: "zh"
assistant_id: JarvisBot
pipeline:
- name: "MitieNLP"
model: "data/total_word_feature_extractor_zh.dat"
- name: JiebaTokenizer
dictionary_path: "data/jieba/"
"intent_tokenization_flag": false
"intent_split_symbol": "_"
"token_pattern": None
- name: "CountVectorsFeaturizer"
"analyzer": "word"
"min_ngram": 1
"max_ngram": 1
"OOV_token": "_oov_"
"use_shared_vocab": false
- name: LexicalSyntacticFeaturizer
"features": [["low", "title", "upper"], ["BOS", "EOS", "low", "upper", "title", "digit"], ["low", "title", "upper"]]
- name: LogisticRegressionClassifier
max_iter: 100
solver: lbfgs
tol: 0.0001
random_state: 42
ranking_length: 10
- name: "MitieIntentClassifier"
- name: "MitieEntityExtractor"
- name: "EntitySynonymMapper"
现在,我们只需要通过下面的脚本训练模型即可:
python -m rasa train -c sample_configs/config_jieba_mitie_sklearn.yml --data data/examples/rasa/jarvis_rasa_zh.yml nlu
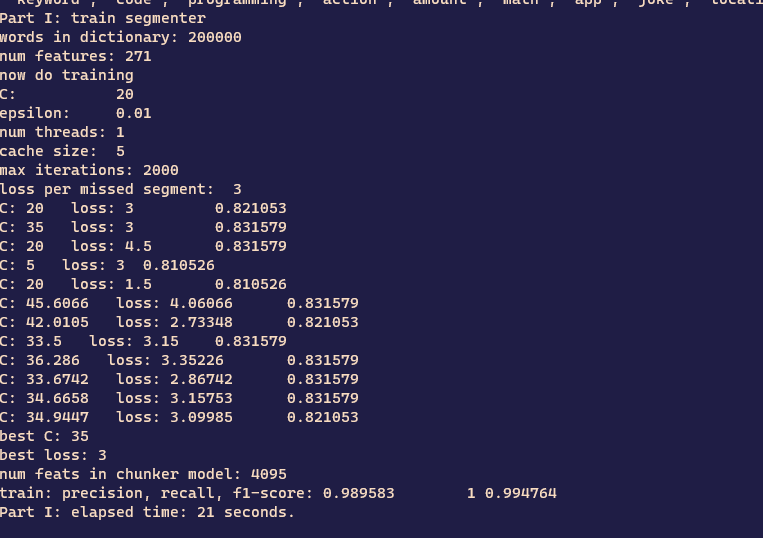
其中:-c 参数用于指定配置文件、--data参数用于指定训练数据。经博主测试,在普通的 CPU 环境下,完成一次训练大概需要 4 个小时,每次训练后它会在 models 目录生成一个模型文件,在不指定模型名称的情况下,这个模型文件的名称通常是随机生成。当然,你可以使用 --fixed-model-name参数使其固定下来。如下图所示,这是博主“炼丹”过程中保存的截图,希望屏幕前的、比我更懂机器学习的各位,帮我分析一下这个训练是否还有优化空间:
当模型训练好以后,我们就可以开始测试啦!此时,我们需要执行下面的脚本:
python -m rasa run --enable-api -m models\nlu-20230515-183633-creative-bucket.tar.gz
该命令会在本地运行一个 NLU Server,端口默认为 5005,通常,你可以像下面这样访问它提供的 API 接口:
curl localhost:5005/model/parse -d '{"text":"hello"}'
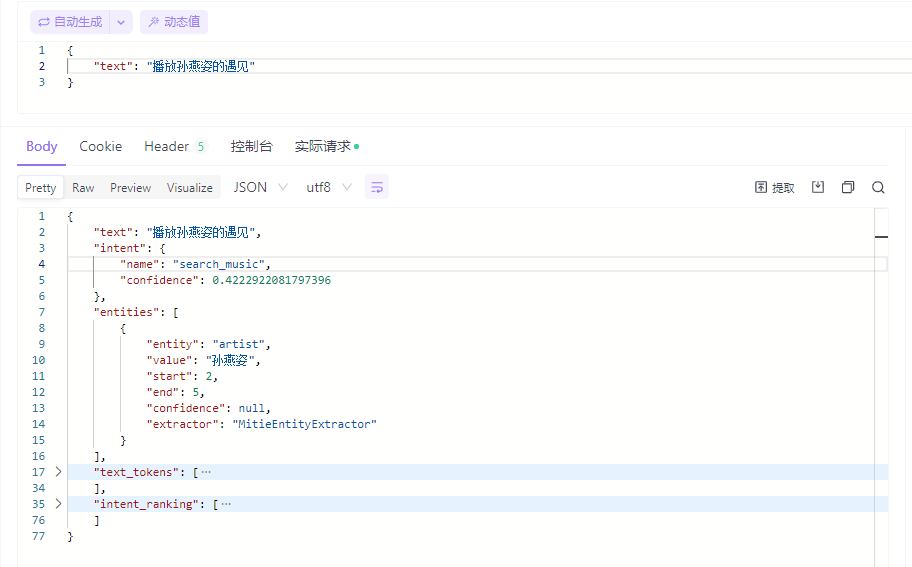
下面是博主实际测试的结果,个人对这个结果还是挺满意的,如果一定要说缺陷的话,首先,它会把 “王菲的传奇” 这句话切分为 “王菲” 和 “的传奇”,当然,这大概率是没有排除某些停用词的缘故;其次,它不能提取出我们期望的实体,在这个例子中,“孙燕姿”这个实体固然重要,可更重要的应该是“遇见”,这将是接下来优化的一个重点。
当然!幸运的是,我们至少解决了当时 ChatGPT 没有解决的问题,因为这些意图的分类都是我们在训练数据中人为规定的,所以,它不会出现意料之外的意图分类,或者是相似的意图分类,就像本文一开始给出的代码示例一样,“查询日期”、“询问日期”、“日期查询” 本质上都是在描述同一件事情,可由于这些分类都是由 ChatGPT 产生的,所以,基于 ChatGPT 的这个方案多少是有点不确定性在里面的,而对于一个 API 来说,相同的输入应该得到相同的结果,从这一点上来看,或许是 Rasa 更胜一筹!
结论
ChatGPT 发布以来,关于被 AI 替代以致于失业的焦虑声音不断涌现,即便是传统的 NLP 亦不能幸免。在开发贾维斯的过程中,博主需要解决意图识别的问题,本文分享了两种解决问题的思路,它们分别是以 ChatGPT 为代表的大语言模型、以 Rasa 为代表的传统 NLP。对于 “NLP 已死”、“NLP 不存在了”这样的观点,笔者的看法是,这实际代表了人工智能的两种方向:通用智能和专业智能。虽然像 ChatGPT 这样的通用型 LLM 表现不俗,但是对于 NLP 的一系列问题,永远依赖于调用一个外部模型注定不可行。在这种情况下,你不可能像 OpenAI 一样投入大量人力、物力去训练一个 LLM。此时,选择 LLaMa 或者 Alpaca 这样的“小”模型就不失为一种明智的选择。此外,现阶段 LLM 的微调、“投喂”数据依然需要 NLP 的知识。也许,正如杨冬所言,并不是物理学不存在了,而是我们认为的物理学不存在了。同样的,像传统 NLP 那样细分的、垂直的子任务会越来越少,而多模态/跨模态的场景和应用会越来越多。如果用一句 100% 正确的废话来描述就是,这是一个机遇与挑战并存的时代!


