2020 年年底的时候,博主曾心血来潮地开启过一个系列:视频是不能 P 的,其灵感则是来源于互联网上的一个梗,即:视频不能 P 所以是真的。不过,在一个美颜盛行的时代,辨别真伪实在是一件奢侈的事情,在各种深度学习框架光环的加持下,在视频中实现“改头换面”已然不再是新鲜事儿,AI 换脸风靡一时的背后,带来是关乎隐私和伦理的一系列问题,你越来越难以确认,屏幕对面的那个到底是不是真实的人类。古典小说《红楼梦》里的太虚幻境,其牌坊上有幅对联写道,“假作真时真亦假,无为有处有还无”。果然,在这个亦真亦幻的世界里,哪里还有什么东西是不能 PS 的呢?在“鸽”了很久很久之后,博主决定要来更新这个系列啦,让我们继续以 OpenCV 作为起点,来探索那些好玩、有趣的视频/图像处理思路,这一次呢,我们来聊聊 OpenCV、Dlib 和 表情包,希望寓教于乐的方式能让大家感受到编程的快乐!
环境准备
python -m pip install opencv-python
python -m pip install opencv-contrib-python
python -m pip install Pillow
python -m pip install numpy
python -m pip install imutils
python -m pip install dlib
请注意,如果通过 pip 安装 dlib 不大顺利,你可以到 https://github.com/sachadee/Dlib 这个仓库中下载对应的 .whl 文件。例如,博主使用的是 64 位的 Windows 系统,而我的 Python 版本是 3.7,因此,我下载的是 dlib-19.22.99-cp37-cp37m-win_amd64.whl 这个文件。此时,我们可以用下面的方式来安装 dlib:
python -m pip install dlib-19.22.99-cp37-cp37m-win_amd64.whl
除此以外,我们还需要下载 dlib 所需的模型文件,下载地址为:http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2。下载该文件并解压后,可以得到一个 .dat 格式的文件,这就是我们用来做人脸识别的模型文件,即人脸的 68 个特征点检测,这个我们会在下面做更进一步的说明。
初探 Dlib
其实,如果是简单的人脸检测,OpenCV 完全足矣。如果你读过我这个系列的第一篇文章,就会知道 OpenCV 人脸检测的实际效果如何。事实上,它会使用一个矩形来表示检测到的人脸范围,这里,我还是用堺雅人主演的电视剧《半泽直树》来作为说明,可以注意到每一个矩形对应着一张人脸:
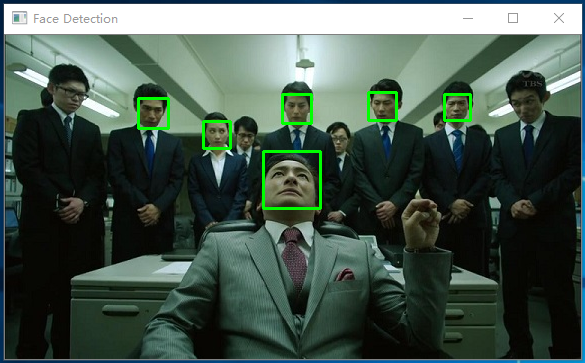
可是,如果我们希望对这些“人脸”进行比对以期望达到人脸识别的目的,这个精度对我们来说就显得捉襟见肘啦!为了解决这个问题, dlib 中使用的是一种被称之为 68 face landmarks 的方法,简单来说,就是用 68 个特性点来定位一个人的面目五官,为了方便大家理解,我们一起来看下面的例子:
# 初始化 detector 和 predictor
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')
# 载入人脸图片
image = cv2.imread("./faces/face1.jpg")
# 检测人脸 & 绘制特征点
face_rects = detector(image, 0)
for index, face in enumerate(face_rects):
shape = predictor(image, face_rects[index])
shape = face_utils.shape_to_np(shape)
for idx, (x,y) in enumerate():
cv2.circle(img, (x, y), 1, (0, 0, 255), -1)
cv2.putText(img, str(idx + 1), (x,y), cv2.FONT_HERSHEY_SIMPLEX, 0.2, (255, 255, 255), 1, cv2.LINE_AA)
cv2.imshow("image",image)
此时,我们可以得到下面的结果:

可以注意到, dlib 可以进一步识别出人脸中的特征点,譬如眼睛、眉毛、鼻子、嘴巴等等,这让我们有了更多可以探索的乐趣。举个例子,司机在道路上疲劳驾驶,有可能会引发交通事故,如果我们能实时分析司机的面目表情,就可以为这个世界做出一点小小的努力。一个常见的思路是计算“眼睛”部分的宽高比,因为当人眼睛闭合的时候,相当于“眼睛”部分纵向的特征点间距变小。再比如,我们可以通过嘴角和眉毛的弧度来“揣测”一个人的喜怒哀乐,让计算机不再是冷冰冰地一台机器。也许,你听说过“三庭五眼”这套理论,所以,从某种意义上来讲,这个思路还可以扩展到“看相”这个方向。果然,你可以永远相信神仙姐姐的颜值呢…
移花接木
OK,在对 dlib 有一个初步印象以后,我们来说说,在今天这篇博客里,博主到底想做一件什么样的事情。如下图所示,我们希望借助 dlib 逐步地“抠取”出人物表情,最终再和这个经典的“熊猫人”融合在一起,从而达到从某任意图片生成表情包的目的。当然啦,这个想法并不容易实现,因为你从这个图片中就可以看到它的最终效果。图中使用的素材出自半泽直树第二季,当半泽直树遇上对手黑崎骏一,瞬间碰撞出一种惺惺相惜的 CP 感,作为雅人叔的忠实粉丝,还有什么比做成表情包更直抒胸臆的表达方式呢?

68 个特征点的绘制,在初探 dlib 的环节已经讲过,这里就不再赘述啦!这里,我们先来说说人脸的矩形范围如何获得,可能有读者朋友会问,这个矩形的作用是什么?其实,不管我们用怎样不规则的一个多边形来裁切图片,我们最终得到的一定是具备长和宽的矩形。因此,这个矩形就是帮我们定位整个脸的范围。下面是对应的代码片段:
def get_facemark_rect(shape):
shape2np = face_utils.shape_to_np(shape)
(x0, y0) = shape2np[0]
minX = maxX = x0
minY = maxY = y0
for (x,y) in shape2np:
if x < minX:
minX = x
if x >= maxX:
maxX = x
if y < minY:
minY = y
if y >= maxY:
maxY = y
return (minX, minY, maxX - minX, maxY - minY)
可以注意到,代码非常地朴实无华,只需要分别找到 x 和 y 的最小值/最大值,就可以确定人脸的矩形范围。如下图所示,红色线条呈现出的即为人脸的矩形范围。作为对比,我们同时绘制了 dlib 本身自带的一个矩形范围,这个矩形范围大致等同于 OpenCV 人脸检测的效果:
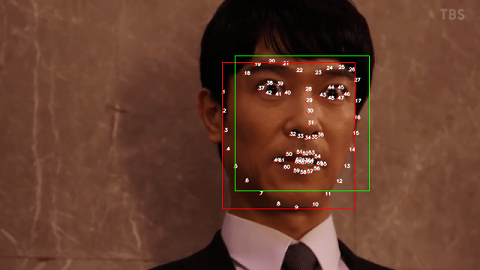
事实上,如果你回头去看我绘制特征点这一部分的代码,会发现这里有一个变量 face 一直没有用到,它实际上是 dlib里定义的一种类型 rectangle,从命名上我们就可以知道,这是一个表示矩形的数据结构。在 OpenCV 中,我们可以使用下面的代码片段来绘制一个矩形:
# 使用自己计算出的矩形范围
(x, y, w, h) = get_facemark_rect(shape)
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 1)
# 使用 dlib 自带的矩形范围
x, y, w, h = face.left(), face.top(), face.right() - face.left(), face.bottom() - face.top()
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 1)
考虑到,博主这里需要的是一个相对精确的面部的范围,大家可以结合自己的需要,选择其中一种即可。接下来,我们来考虑如何根据这 68 个特征点进行“抠脸”,为此,我们只需要找到那些表示面部轮廓的点即可,通过上面的图形,我们可以看出,脸的下半部分轮廓点为 1 到 17,上半部分轮廓点为 18 到 27。因此,我们只需要用这些点构造一个多边形即可:
def create_face_mask(image, facemark):
shape, face = facemark
shape2np = face_utils.shape_to_np(shape)
mask = np.zeros(image.shape, dtype=np.uint8)
points = np.concatenate([shape2np[0:16], shape2np[26:17:-1]])
cv2.fillPoly(img=mask, pts=[points], color=(255,) * image.shape[2])
return mask
这里,我们首先创建了一个和原图片同样大小的图片 mask , 然后调用 fillPoly() 对多边形进行填充。这样,我们就得到了一个和人脸轮廓完全一致的掩膜:

在 OpenCV 中,可以通过 bitwise_and() 函数来对两张图片进行“叠加”, 而在这个示例中,原图片为 image,掩膜图片为 mask,因此,对应的代码片段如下:
image = cv2.bitwise_and(image, mask)
此时,我们可以得到下面的结果,可以注意到,雅人叔的脸已经被我“抠取”出来了,哈哈!

当然啦,这个图片对我们来说太大了!毕竟,我们需要的是雅人叔的这张脸,而不是这个黑乎乎的背景。此时此刻,前面我们计算出来的矩形范围就派上用场啦,因此,我们对图片做一次裁切,OpenCV中裁切图片是非常容易的,我们只需要像对待数组一样指定一个范围:
(x, y, w, h) = get_facemark_rect(shape)
image = image[y:y + h, x:x + w]
当然,这里你会发现一个问题,裁切出来的图片带着黑色背景,这显然不利于我们和“熊猫人”进行融合。这里,博主提供的解决方案是:创建一张同样大小的图片,再把除了黑色以外的颜色全部复制过来,因为黑色再在 NumPy 中使用一个元素全部为 0 的数组来表示。那么,这样就简单多啦:
def create_white_image(image):
white = np.zeros(image.shape, dtype=np.uint8)
for i in range(0, image.shape[0]):
for j in range(0, image.shape[1]):
white[ i, j ] = np.uint8(255)
return white
# 创建一张背景色为白色的图片,复制除黑色以外的每一个像素
white = create_white_image(image)
for i in range(0, image.shape[0]):
for j in range(0, image.shape[1]):
if ((image[i, j] != 0).all()):
white[i, j] = image[i, j]
接下来,为了让雅人叔的脸更贴近“熊猫人”的气质,我们对图片运用一次 threshold() 函数。事实上,到这一步为止,博主一直没有找到特别好的方法,因为人脸上可能会有阴影造成的深浅变化,这样就没有办法 100% 的转化为黑白图片。除了这种固定阈值的方案,博主同样尝试自适应阈值的方案,即 adaptiveThreshold() 函数。不过,从最终效果来看,自适应阈值的方案表现并不好,下面是这两种方案的效果对比:
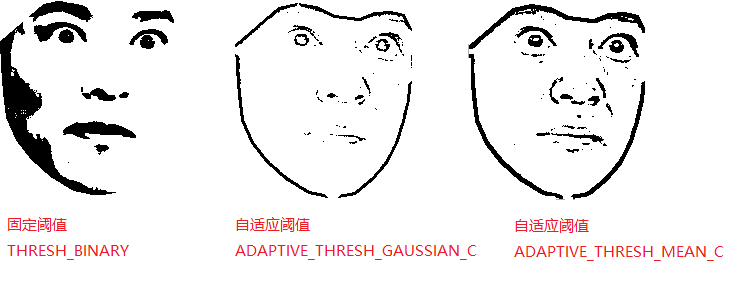
代码层面没什么悬念,转灰度图再调用相应的函数即可:
# 转灰度图
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 固定阈值 + THRESH_BINARY
_, image1 = cv2.threshold(image, 45, 255, cv2.THRESH_BINARY)
# 自适应阈值 + ADAPTIVE_THRESH_GAUSSIAN_C
image2 = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY,9,7)
# 自适应阈值 + ADAPTIVE_THRESH_MEAN_C
image3 = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY,9,7)
如果抛开最终呈现出来的效果的好坏不谈,到这里我们勉强算是达到了预期目的,我们将这个结果以图片的形式保存下来。接下来,我们只需要把雅人叔的脸和“熊猫人”组合在一起即可:
# 读取熊猫人和人脸图片
panda = Image.open("PandaMan.jpg")
face = Image.open("face.jpg")
w_g, h_g = bg.size
w_f, h_f = face.size
ratio = h_f / w_f
# 根据熊猫人的大小对人脸进行缩放
w_new = int(w_g * 0.4)
h_new = int(ratio * w_new)
resized = face.resize((w_new, h_new),Image.ANTIALIAS)
# 计算左上角坐标
left = int((w_g - w_new) / 2)
top = int((h_g / 2 - h_new) / 2)
# 把人脸贴到指定位置
panda.paste(resized, (left, top, left + w_new, top + h_new))
panda.save('output.jpg')
那么,对不起了,雅人叔,我实在是太喜欢你在不同的剧里呈现出来的形象,半泽直树、古美门、德川家定、山南敬助、真田信繁…,每一个角色都能让人惊呼这居然是同一个人,更不用说,有那种根植于文学和话剧的清澈感,能在演绎角色的同时加入个人的理解。雅人叔,请变成我的表情包吧,哈哈!

本文小结
其实,一开始在规划这篇文章的时候,我原本是打算写一写“换脸”这个话题的。可是后来发现,换脸涉及的那些知识,对现在的我而言,实在是一座难以逾越的高山,所以,最后不得不退而求其次,写一个相对简单的话题,可即使这样,写这篇文章还是花费了我挺长时间,因为一直没有找到更好的方法来处理人脸。所以,这篇文章写到这种程度,其实是因为我不想一直拖延下去。简单总结一下,这篇文章介绍了 dlib 的用法,相对于 OpenCV 而言,它可以拿到人脸的 68 个特征点,而基于特征点我们可以对人脸检测/识别做进一步的探索,比如驾驶过程中司机的疲劳检测、表情分析、活体检测等等,而这篇文章主要利用了其中的轮廓点来生成多边形掩膜,来达到抠取人脸的目的。在这个基础上,我们实现了通过照片制作表情包的想法,虽然目前实用性并不强,可我觉得处理图像的这个过程还是特别有意思。以前,有人讲过程序员的三大浪漫,即操作系统、编译原理 和 图像学,这种浪漫大概只有程序员能理解。好了,以上就是这篇博客的全部内容啦,如果大家对人脸的处理还有更好的方案,欢迎大家在评论区积极留言。


