最近,我一直在体验 Cursor 这款产品,与先前的 CodeGeex、通义灵码 等 “插件类” 产品相比,Cursor 在产品形态上更接近 Github Copilot。在多项测评中,Cursor 甚至一度超越了 Github Copilot。尽管我没有体验过 Github Copilot,但从用户体验的角度来看,Cursor 基于 VS Code 进行了深度定制。除了基础的代码自动补全功能外,它还可以允许你从原型图生成代码、将整个工程作为 Codebase、一键应用代码到本地。最令我印象深刻的是,它指导我完成了一个 Vue 的小项目,从零开始。诚然,“幻觉” 的存在让它在 Vue 2 和 Vue 3 之间反复横跳,其编程能力的提升主要得益于 Claude 3.5 系列模型,可我还是像《三体》中的杨冬一样感到震惊:物理学不存在了,那前端呢?有人说,程序员真正的护城河是沟通能力,因为执行层面的工作可以交给 AI。实际上,我并不担心 AI 取代人类,我更倾向于与 AI 沟通和合作,你可能想象不到,这篇文章中的思考正是来自于我和 Claude 老师的日常交流。
CRUD Boys 的日常
程序员普遍喜欢自嘲,以博主为例,作为一名后端工程师,我的日常工作主要就是 CRUD,因此,你可以叫我们 CRUD Boys。鲁迅先生曾作《自嘲》一诗,“破帽遮颜过闹市,漏船载酒泛中流”。面对软件世界里里的复杂性和不确定性,如果没有乐观的心态和耐心,哪怕是最基础的 CRUD,你不见得就能做到得心应手。你可能听说过这样一句话,“上岸第一剑,先斩意中人”,AI 领域的第一把火,永远烧向程序员自己,自打一众 AI 辅助编程工具问世以来,各种程序员被 AI 取代的声音不绝于耳,甚至 Cursor 可以在 45 分钟内让一个 8 岁小孩搭建出聊天网站,更不必说,在 OpenAI 发布全新的 o1 模型后,很多人觉得连提示工程、Agent 这些东西都不存在了。其实,代码生成、低代码/无代码相关的技术一直都存在,在很久以前,我们就在通过 T4 模板生成业务代码,自不必说各种代码生成器。截止到目前,Excel 依然是这个地球上最强大的低代码工具,可又有谁能掌握 Excel 的全部功能呢?

退一步讲,即使的最简单的 CRUD,虽然业务的推进会不断地演化出新的问题。譬如,当你为了加快查询效率引入了缓存,你需要去解决数据库和缓存一致性、缓存失效等问题;当你发现数据库读/写不平衡引入读写分离、分库分表,你就需要去解决主从一致、分布式事务、跨库查询等问题;当你发现单点性能不足引入了多机器、多线程,你需要去解决负载均衡、线程同步等问题……单单一个查询就如此棘手,你还会觉得后端的 CRUD 简单吗?我承认,后端的确都是 CRUD,可在不同的维度上这些 CRUD 并不完全相同,譬如,分布式的相关算法如 Paxos、Raft 等,难道不是针对分布式环境中的节点做 CRUD 吗?可此时你还会觉得它简单吗?Cursor 的确可以帮你生成代码,但真正让它出圈的是背后的 Claude 模型。我始终相信某位前辈曾经讲过的话:“没有银弹”,在软件行业里,复杂度永远不会消失,它只会以一种新的方式出现。如果你觉得 CRUD 简单,或许是你从未接触过那些千姿百态的查询接口:
// OData 风格
Products?$filter=Category eq 'Electronics'&$orderby=Price desc&$top=10&$skip=20
// GraphQL 风格
{
products(category: "Electronics", first: 10, skip: 20, orderBy: {field: PRICE, direction: DESC}) {
name
price
}
}
// RESTful 风格
products?category=Electronics&sort=-price&limit=10&offset=20
products?filter[category]=Electronics&sort=-price&page[limit]=10&page[offset]=20
从 Gridify 中得到的启发
Gridify 是一个卓越的动态 LINQ 库,它可以将字符串转化为 LINQ 查询。因此,它非常适合处理分页、过滤、排序等问题。如以下代码示例所示,你只需要在控制器方法中添加一个 GridifyQuery 类型的参数,即可实现一个通用的分页查询接口,可以说是非常的 Amazing 啊!👌
[HttpGet]
public Paging<Product> GetPagingProducts([FromQuery]GridifyQuery query) {
var queryable = _context.Products.AsQueryable();
return queryable.Gridify(query);
}
事实上,Gridify 为 IQueryable 接口提供了丰富的扩展方法,这使得我们可以如此优雅地实现分页查询功能。此时,我们可以使用类似下面这样的语法来查询产品信息:
// 查询品牌中含有 Nick 的产品
api/products?page=1&pageSize=10&filter=brand=*Nike
// 查询价格大于或等于 10 元的产品
api/products?page=1&pageSize=10&filter=price>=10
// 查询名称以 Nick 开头的产品
api/products?page=1&pageSize=10&filter=name=^Nick
// 查询品牌中含有 Nick 的产品,并按 SKU 降序排列
api/products?page=1&pageSize=10&filter=brand=*Nike&orderBy=sku desc
你可以理解为,Gridify 定义了一套过滤和排序的语法,这些语法将会被解析、编译为表达式,并最终应用到 IQueryable 接口上面。对于 .NET 开发者来说,常见的做法是:使用 Where() 筛选数据,使用 Skip() 和 Take() 实现分页查询,以及使用 OrderBy()、OrderByDescending()、ThenBy() 和 ThenByDescending() 对数据进行排序。目前,Gridify 支持的操作符如下所示:
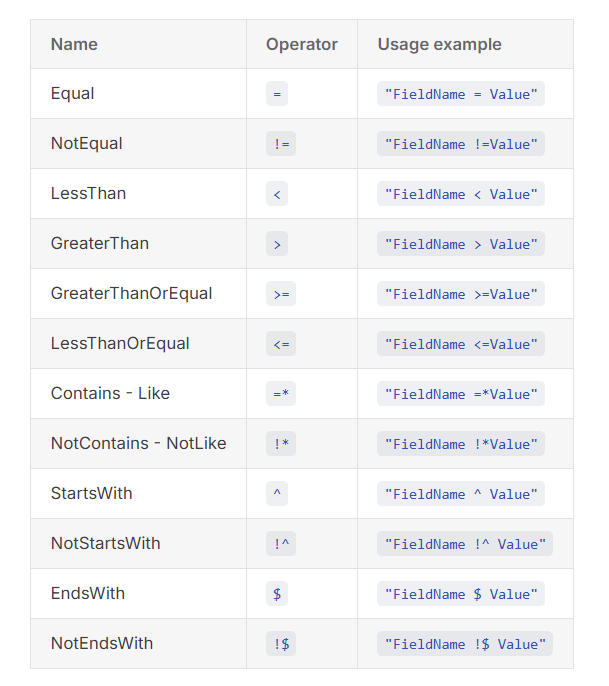
这个方案在某种程度上与我过去开源的项目 DynamicSearch 非常相似,都是通过构建表达式实现动态查询。事实上,之前已经有一个名为 System.Linq.Dynamic 的项目专门解决这类动态查询问题。唯一的挑战是,这些方案对前端同事来说过于复杂了,即便 Gridify 中非常贴心的提供了前端实现。当然,一个更要的原因是,我更倾向于避免解析字符串信息。那么,是否有更好的解决方案呢?诸如 Java 程序员在 XML 里写 SQL 的做法,窃为我所不取也!
一个通用查询方案的实现
首先,我们参照 GridifyQuery 定义一个泛型类 QueryParameter:
class QueryParameter<TEntity,TFilter> where TFilter : class, IQueryableFilter<TEntity> {
public int PageIndex { get; set; }
public int PageSize { get; set; }
public TFilter Filter { get; set; }
public string SortBy { get; set; }
public bool IsDescending { get; set; }
}
其中,参数 TFilter 需要满足一定的约束条件,即:实现 IQueryableFilter 接口,该接口定义如下:
interface IQueryableFilter<TEntity> {
ISugarQueryable<TEntity> Apply(ISugarQueryable<TEntity> queryable);
}
博主这里使用的 ORM 是 SqlSugar,因此,这个接口需要依赖 ISugarQueryable 接口,如果你使用 EntityFramework,可以将其替换为 IQueryable。当我们需要对特定数据进行筛选时,我们只需要为其定义一个或者多个过滤条件即可。例如,通过下面的 LlmModelQueryableFilter 类,即可完成对大模型信息的检索:
class LlmModelQueryableFilter : IQueryableFilter<LlmModel> {
public string ModelName { get; set; }
public int? ModelType { get; set; }
public int? ServiceProvider { get; set; }
public ISugarQueryable<LlmModel> Apply(ISugarQueryable<LlmModel> queryable) {
if (!string.IsNullOrEmpty(ModelName))
queryable = queryable.Where(x => x.ModelName.Contains(ModelName));
if (ModelType.HasValue)
queryable = queryable.Where(x => x.ModelType == ModelType);
if (ServiceProvider.HasValue)
queryable = queryable.Where(x => x.ServiceProvider == ServiceProvider);
return queryable;
}
}
通常情况下,你只需要继承 CrudBaseController,并将其与实体类关联起来即可:
[Route("api/[controller]")]
[ApiController]
class LlmModelController : CrudBaseController<LlmModel,LlmModelQueryableFilter> {
private readonly IRepository<LlmModel> _llmModelRepository;
public LlmModelController(CrudBaseService<LlmModel> crudBaseService, IRepository<LlmModel> llmModelRepository) : base(crudBaseService) {
_llmModelRepository = llmModelRepository;
}
}
此时,你将得到一组 RESTful 风格的 CRUD 接口,如下图所示:
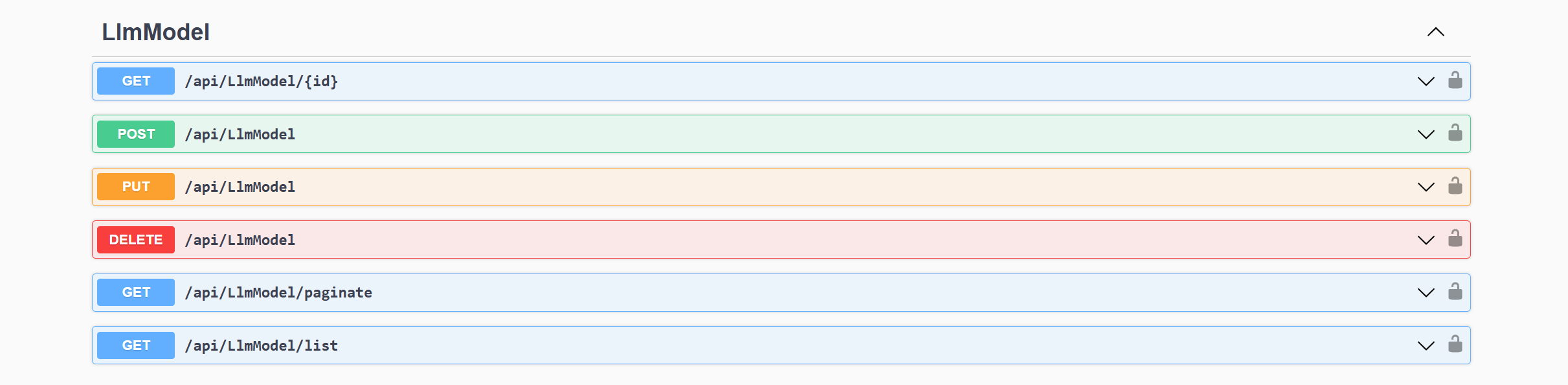
其中, api/LlmModel/paginate 和 api/LlmModel/list 具有相同的过滤条件,真正做到了 “一次编写,到处运行”。关于 CrudBaseController 的具体实现,我认为并不复杂,关键代码片段展示如下:
// 分页查询
async Task<PagedResult<T>> PaginateAsync<TQueryFilter>(
QueryParameter<T, TQueryFilter> queryParameter,
ISugarQueryable<T> queryable = null
)
where TQueryFilter : class, IQueryableFilter<T> {
queryable = queryable ?? base.AsQueryable();
if (queryParameter.Filter != null)
queryable = queryParameter.Filter.Apply(queryable);
var total = await queryable.CountAsync();
queryable = queryable.Skip((queryParameter.PageIndex - 1) * queryParameter.PageSize).Take(queryParameter.PageSize);
if (!string.IsNullOrEmpty(queryParameter.SortBy))
queryable = queryable.OrderByPropertyName(queryParameter.SortBy, queryParameter.IsDescending ? OrderByType.Desc : OrderByType.Asc);
var list = await queryable.ToListAsync();
return new PagedResult<T> { TotalCount = total, Rows = list };
}
// 列表查询
Task<List<T>> FindListAsync<TQueryFilter>(
TQueryFilter filter,
ISugarQueryable<T> queryable = null
)
where TQueryFilter : class, IQueryableFilter<T> {
queryable = queryable ?? base.AsQueryable();
if (filter != null) queryable = filter.Apply(queryable);
return queryable.ToListAsync();
}
大家可能已经注意到,代码本身并没有变,但是它解决了一个关键问题:如何让整个控制器层变得整洁。回想一下,我们过去是如何处理这类问题的?是不是经常不断地向控制器添加参数?虽然我可能只是一个 CRUD Boy,可我并不愿意就此止步,能从这个再熟悉不过的话题中 “温故而知新”、查漏补缺,这是我写这篇博客的主要目标。让我们沿着这个思路继续探索,此时,我们会发现这里的过滤条件并不符合我们的预期:
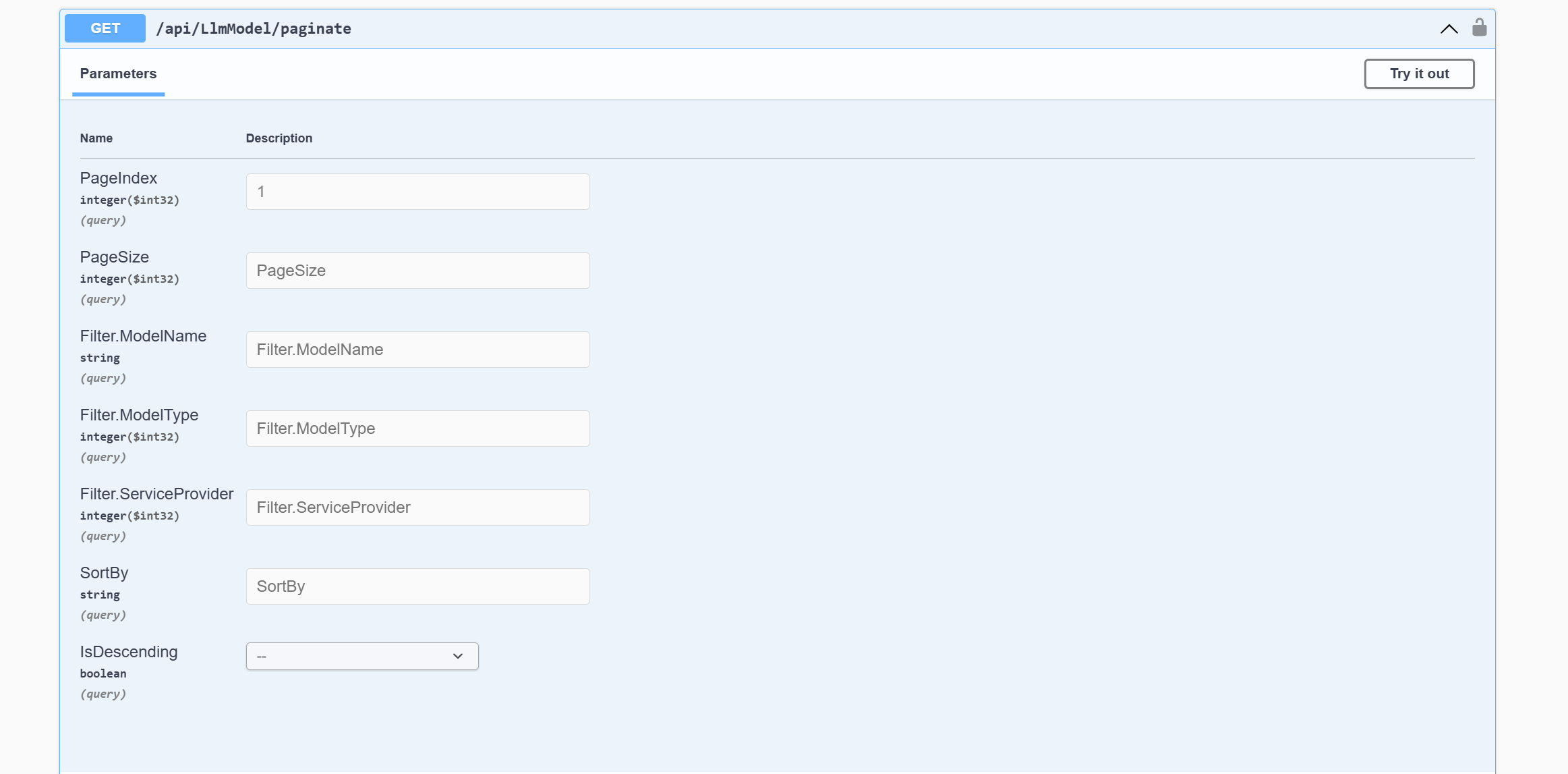
具体来说,博主期待的查询参数应该是下面这种格式:
api/LlmModel/paginate?pageIndex=1&pageSize=10&modelName=llama3&modelType=0
事实上,在真实的请求中,你将会看到的下面这种格式的查询参数:
api/LlmModel/paginate?pageIndex=1&pageSize=10&filter.modelName=llama3&filter.modelType=0
在某个瞬间,你是否会对这个格式感到困惑呢?实际上,这两种格式都是合理的,前者被称为平铺格式,而后者则被称为嵌套格式。其中,平铺模式对前端友好,缺点是当参数较多时可能会造成混淆,无法区分出哪些是过滤条件;嵌套模式对后端友好,可以直接映射到 QueryParameter 参数的 Filter 属性上,缺点是可能与现有组件不兼容,需要前端在传参时做特殊处理。考虑到,无论是 HTTP 协议还是 RESTful 规范,在这一类问题均未做出强制性约束。因此,在实际工作中,你会看到五花八门的实现方式,如以下代码所示:
// 使用 JSON 编码的查询参数
products?query={"page":{"index":1,"size":10},"sort":{"field":"price","direction":"desc"},"filter":{"name":"laptop","category":"electronics"}}
// 使用组合式的过滤条件
products?page=1&size=10&sort=price&order=desc&filters=name:laptop;category:electronics
结合前文可知,OData 和 Gridify 都选择了组合式的过滤条件写法,而我们期望的是平铺格式的过滤条件写法。由此可见,单单是一个查询就有这么多种写法,秦始皇 “书同文”、“车同轨”、统一度量衡的意义在这一刻终于找到了答案,可是话说回来,正是这种灵活性让我们有了发挥的空间,不是吗?那么,该如何解决这个问题呢?这里的方案是实现一个自定义的 IModelBinder,从而改变 ASP.NET Core 模型绑定的默认行为,关键代码如下:
TFilter BindFilter(ModelBindingContext bindingContext) {
var filter = new TFilter();
var filterType = typeof(TFilter);
var properties = filterType.GetProperties();
foreach (var property in properties) {
var key = property.Name.ToLower();
if (!ReservedParameters.Contains(key)) {
// 同时兼容平铺型以及嵌套型参数
// ?pageIndex=1&pageSize=10&name=xxx&age=xxx
// ?pageIndex=1&pageSize=10&filter.name=xxx&filter.age=xxx
var value = bindingContext.ValueProvider.GetValue(key).FirstValue;
if (value == null) {
value = bindingContext.ValueProvider.GetValue($"filter.{key}").FirstValue;
}
if (value != null) {
object convertedValue = null;
var targetType = Nullable.GetUnderlyingType(property.PropertyType) ?? property.PropertyType;
if (targetType.IsEnum) {
convertedValue = Enum.Parse(targetType, value, true);
} else if (targetType == typeof(bool) && bool.TryParse(value, out var _)) {
convertedValue = bool.Parse(value);
} else if (targetType == typeof(DateTime) && DateTime.TryParse(value, out var _)) {
convertedValue = DateTime.Parse(value);
} else {
if (!string.IsNullOrEmpty(value.ToString()))
convertedValue = Convert.ChangeType(value, targetType);
}
property.SetValue(filter, convertedValue);
}
}
}
return filter;
}
可以注意到,本质上就是对两种类型的查询参数做了兼容,这样做的好处是,现在前后端都可以在各自的舒适区愉快工作,我认为这种效率的提升是有效提升,因为它真正地改善了生产关系,让前后端都能都能从中受益。相反,一味地提升效率而不去改善生产关系,永远都只会造成更多的内卷。这个方案是由我和 Claude 老师一起完成的,我觉得它还有进一步改善的空间,因为现在 IQueryableFilter 与 ISugarQueryable 强耦合,这显然不是我们希望看到的结果。当你使用 EntityFramework 时,你会希望这里变成 IQueryable;当你使用 MongoDB 时,你会希望这里变成 FilterDefinitionBuilder。所以,我认为这里还可以再引入一个中间层,你觉得呢?
本文小结
回顾整个探索过程,我不禁莞尔,从在Gridify 中寻找灵感,到亲自动手设计查询方案,再到深入思考参数传递的细节,对我而言,这个过程中是在一次次的思考和实践中,逐渐接近问题的本质。说到底,我们讨论的并不仅仅是一个查询方案,而是如何在灵活性和规范性之间寻找平衡。这个问题,恐怕从软件开发诞生以来就一直存在,而今天我们依旧在探索。也许,正是这种永无止境的探索,构成了编程的真正魅力。AI 无疑会给程序员带来不小的冲击,可仔细想想,它不过是我们工具箱中的新成员,就像我们并不会因为有了电动螺丝刀,就忘记如何使用普通螺丝刀。作为程序员,我们不应该局限在代码生成这一个点,而是要着眼于解决更复杂的问题、改善生产关系。本文探索的通用查询方案,表面上看是一个技术问题,实则触及了软件工程中的普适性难题,即:灵活性与规范性的取舍。我承认,AI 是可以帮我们快速生成各种代码,可未来的软件开发,决不会仅仅是代码的简单堆砌,为什么我们的目标不能是更高层次的系统设计和问题解决?就像这篇文章里提出的方案并非完美无瑕,它依然有改进和优化的空间。所以,请不要放弃你的主观能动性,让 AI 辅助你思考,而不是替你思考。


