《诗经》有言:七月流火,九月授衣,这句话常被用来描绘夏秋交替、天气由热转凉的季节变化。西安的雨季,自六月下旬悄然而至、连绵不绝,不由地令人感慨:古人诚不欺我。或许,七月注定是个多事之“秋”,前有萝卜快跑及其背后的无人驾驶引发热议,后有特朗普在宾夕法尼亚州竞选集会时遇刺,更遑论洞庭湖决口、西二环塌方。杨绛先生说,成长就是学会心平气和地去面对这世界的兵荒马乱,可真正的战争“俄乌冲突”至今已经持续800多天。有时候,我不免怀疑,历史可是被诅咒了的时间?两年前的此时此刻,日本前首相安倍晋三遇刺身亡,我专门写过一篇文章《杂感·七月寄望》 。现在,回想起两人长达19秒的史诗级握手画面,一时间居然有种“一笑泯恩仇”的错觉。因为,从某种意义上来说,他们似乎成为了共患难的“战友”。雍正之于万历,如同特朗普之于肯尼迪,虽时过境迁,而又似曾相识,大概世间万物总逃不出某种循环。最近一个月,从 RAG 到 Agent,再到微软 GraphRAG 的爆火,诸如 Graph、NER、知识图谱等知识点再次被激活。我突然觉得,我需要一篇文章来整理我当下的思绪。
实现 Agent 以后
参照复旦大学的 RAG 综述论文实现 Advance RAG 以后,我开始将目标转向 Agent。一般来说,一个 Agent 至少应该具备三种基本能力:规划(Planning)、记忆(Memory)以及工具使用(Tool Use),即:Agent = LLM + Planning + Memory + Tool Use。如果说,使用工具是人类文明的起点,那么,Agent 则标志着大模型从 “说话” 进化到 “做事”。目前的 Agent 或者是说智能体,本质上都是将大模型视作数字大脑,通过反思、CoT、ReAct 等提示工程模拟人类思考过程,再通过任务规划、工具使用来扩展其能力的边界,使其能够感知和连接真实世界。从早期的 AutoGPT 到全球首个 AI 程序员智能体 Devin,人们对于 AI 的期望值,正肉眼可见地一路水涨船高。
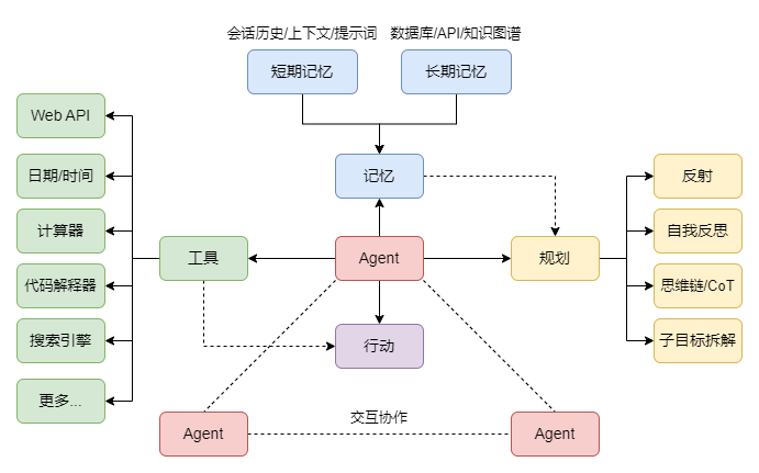
目前,市场上主流新能源汽车的智驾系统都大多处于 L2 或 L3 级别,萝卜快跑则率迈进 L4 级别。尽管我可以理解这一发展趋势的必然性,可当我意识到碳基生命自身的偶然性,我想知道,那些可能导致成千上万的人失业的失业的科技创新,是否是显得过于残酷和冰冷?在2024年的上半年,我接触到了多种 Agent 产品,例如 FastGPT、Coze、Dify 等等。这些产品基本都是基于工作流编排的思路,这实际上是一种对大型模型不稳定输出和多轮对话调用成本的妥协。受到过往工作经历影响,我对于工作流和低代码非常反感。因此,我坚信大模型动态地规划和执行任务的能力才是未来。在实现 Agent 的过程中,我参考 Semantic Kernel 的一个 PR 实现了一个支持 ReAct 模式的 Planner,这证明了我从去年开始接触大型模型时的种种想法,到目前为止基本上都是正确的。
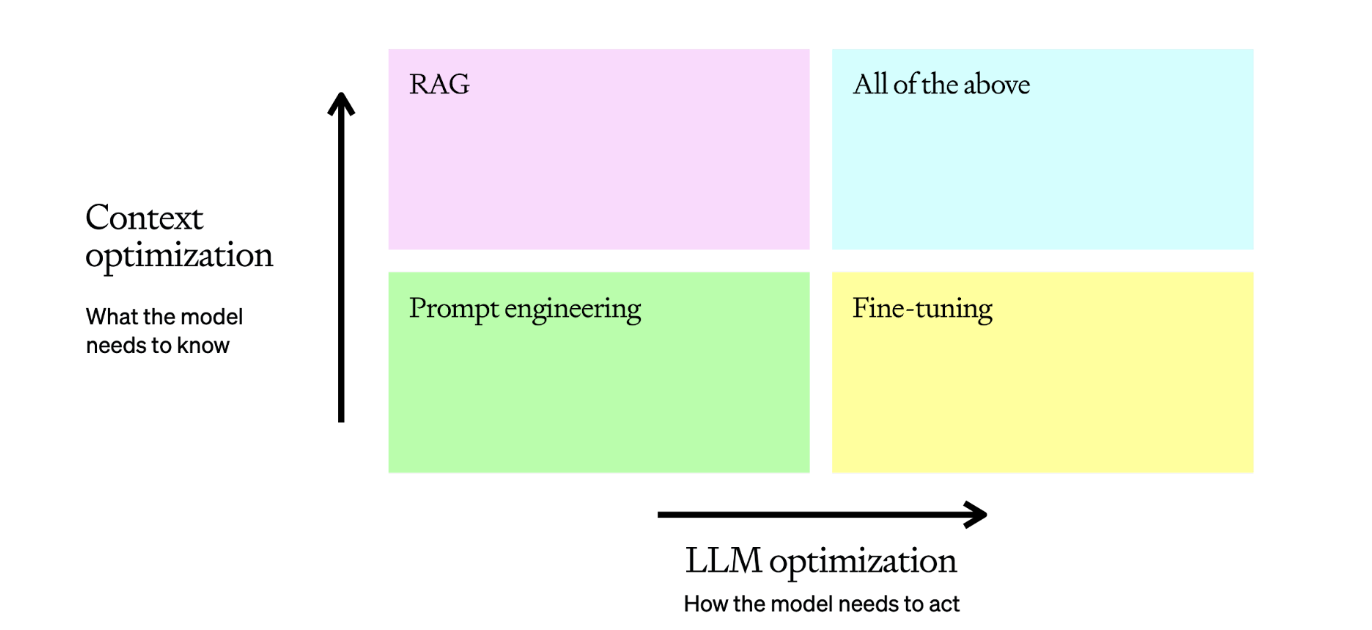
我主张采用小模型结合插件的方式,推进 AI 服务的本地化,因为一味地追求参数规模或上下文长度,只会陷入永无休止的百模大战。在技术和成本之间,你必须要找到一个平衡点。例如,最近大火的 GraphRAG,知识图谱结合大模型的理念虽好,但构建知识图谱的成本相对较高,运行一个简单示例的费用大约在5到10美元左右。在实现 Agent 的过程中,我发现,使用阿里的 Qwen2-7B 模型完全可以支持任务规划以及参数提取,唯一的问题是 Ollama 推理速度较慢,尤其是在纯 CPU 推理的情况下。此外,目前的 Agent 的反思功能大多依赖于多轮对话,其效果易受上下文长度的影响。即便使用 OpenAI、Moonshot 等厂商的服务,它们的 TPM/RPM 通常不会太高,导致公共 API 难以满足 Agent 的运行需求。如果增加接口调用间隔,无疑又会让屏幕前的用户失去耐心。因此,即便是在 token 价格越来越便宜的情况下,以任务为导向的 Agent,其 token 消耗量依然是一笔不小的开销。
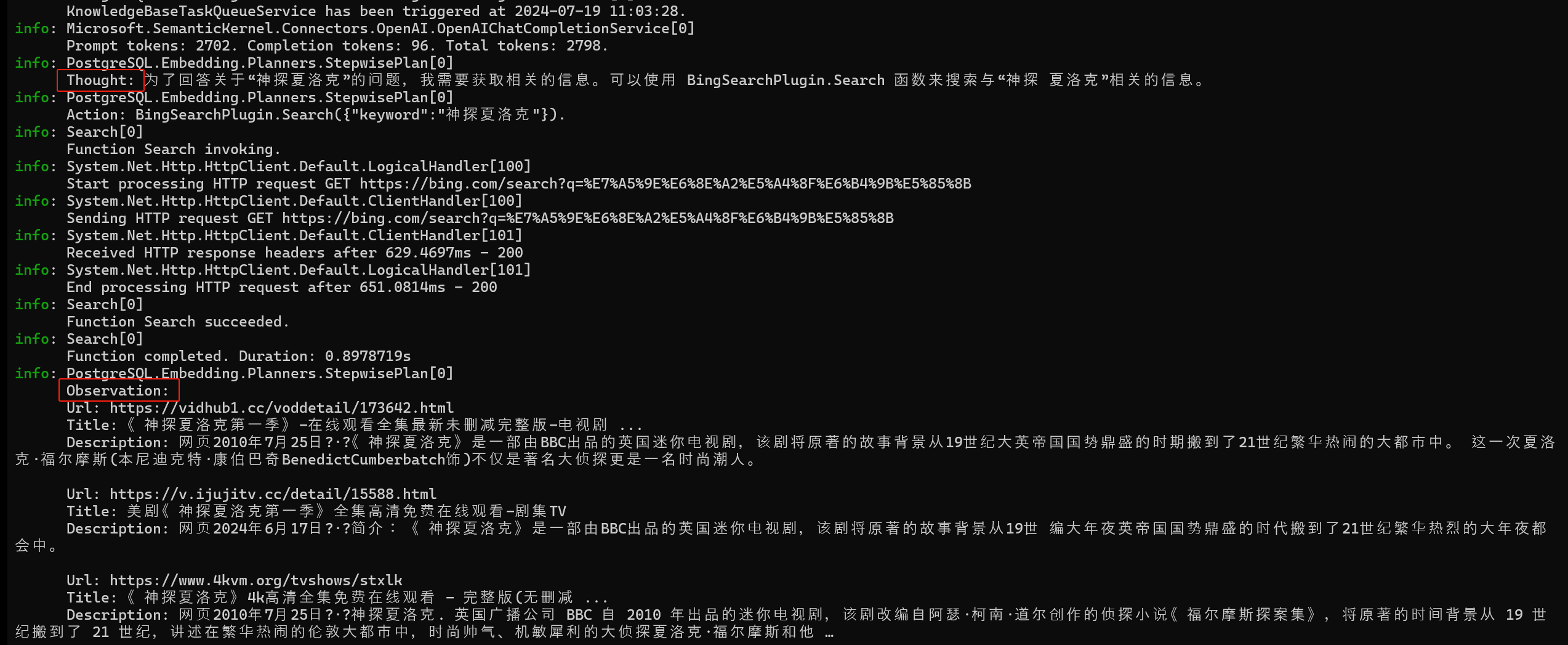
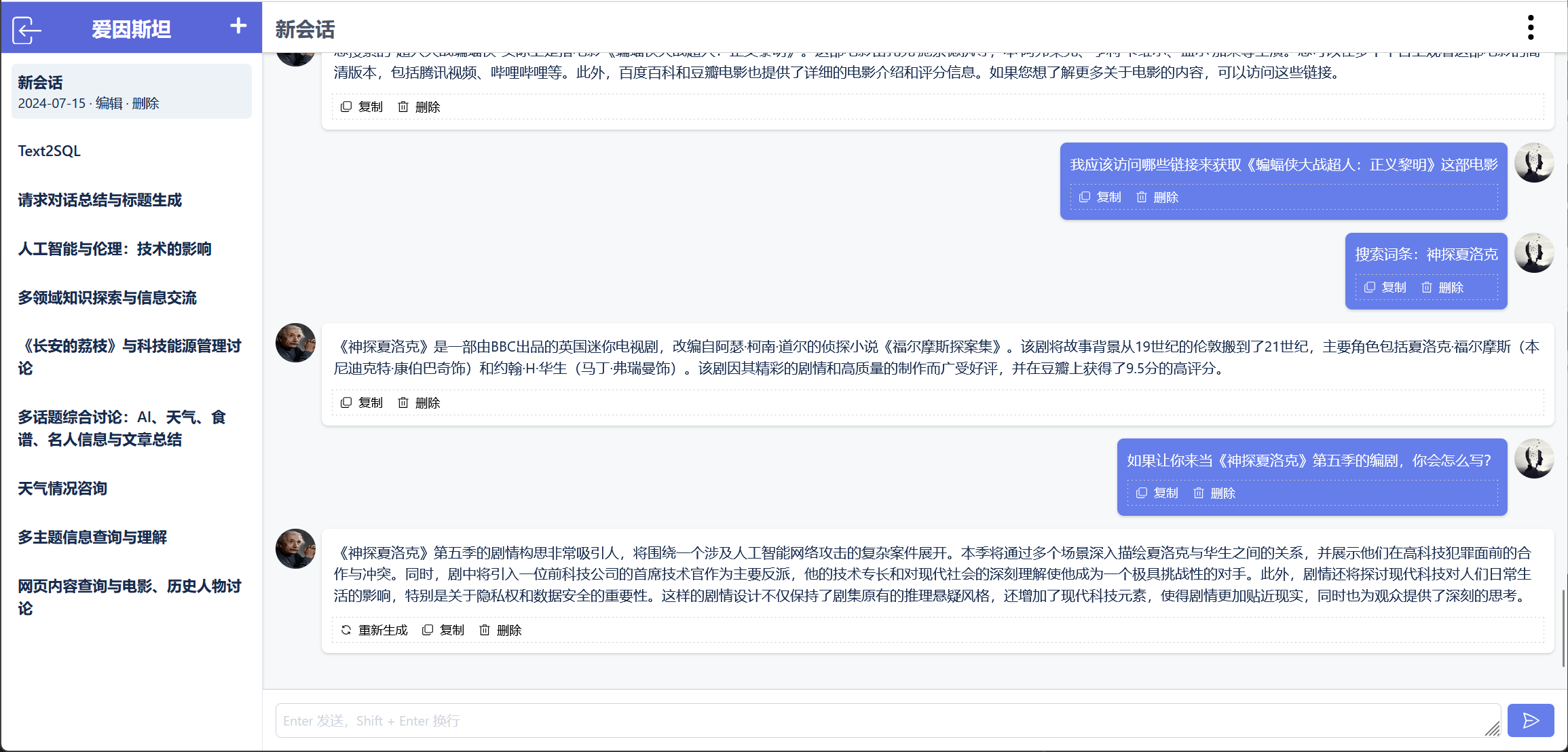
在调试 Agent 的过程中,博主曾先后将 OpenAI 和 Moonshot 用至“欠费”,最终不得不转向更为经济的 DeepSeek。最近,有朋友同我抱怨,“召回精度是提升了,可生成答案时间同样变长了”。这个问题在 Agent 中同样存在,当大模型观察到当前结果差强人意时,会尝试使用不同的工具来解决问题,可往往是花费了时间和金钱,最后还是没能得到满意答案。归根到底,最关键的推理能力来自模型本身,提示词不过是锦上添花,你是可以持续地“反思”和“观察”,可如果面对的是完全未知的事物,这一切又有什么意义呢?以电商业务为例,其特点是数据链路长、牵涉多个微服务,这使得我无法同时满足强一致性和低延迟。这一道理同样适用于 Agent,不论是大模型动态规划的工作流,还是人工编排的工作流,如果你想要一个逻辑上闭环的流程,就要接受其可能耗费大量时间的现实。对于类似 RAG 这样的检索型的任务,你必须要检索精度和响应时间之间找到平衡点。

在为大模型接入了日期/时间、天气预报、新闻报道、搜索引擎、网络爬虫等工具以后,我突然感到一切索然无味,甚至有时会觉得,它不再像原来那样“开朗”,甚至变得不苟言笑起来。最终,它变成了一个合格的、帮助我连接真实世界的“工具人”。可大模型应该被这些词汇修饰吗?或许,这只是我的一厢情愿。因为从某种角度来看,这一切的元凶,在于我的外部知识“污染”了它的先验知识,无论我怎么努力,它并不会比市面上的 AI 助手强大多少。
Text2SQL 实践
OK,现在让我们讨论Text2SQL Text2SQL,这是将大型模型与关系型数据库连接起来的一种尝试。实现 Agent 后,你会发现 RAG 实际上是 Agent 中的一个工具,并且广义上的 RAG 并不仅仅局限于向量数据库,它还可以扩展到搜索引擎、知识图谱、第三方 API、各种数据源(网页/SQL/文档)以及聊天的上下文。这样,我们便会意识到,如果大模型可以从数据库中读取信息,它便掌握了世界上使用最广泛的数据源。在 RAG 应用中,文档中的图像、表格等可能不适合进行向量检索,而数据库中存储的结构化数据对大型模型更为友好。唯一的问题是,关系型数据库通常使用 SQL 来进行查询。因此,如果大模型能生成 SQL 语句,那么,从大模型到数据库的链路便被打通了。从生成式 AI 的角度来看,SQL 和 Python、C# 等编程语言类似,均属于代码生成的范畴,甚至可以说 SQL 更简单,因为 SQL中使用中关键字和指令更少。在这种背景下,Text2SQL 这种从自然语言转化为 SQL 的技术便应运而生。
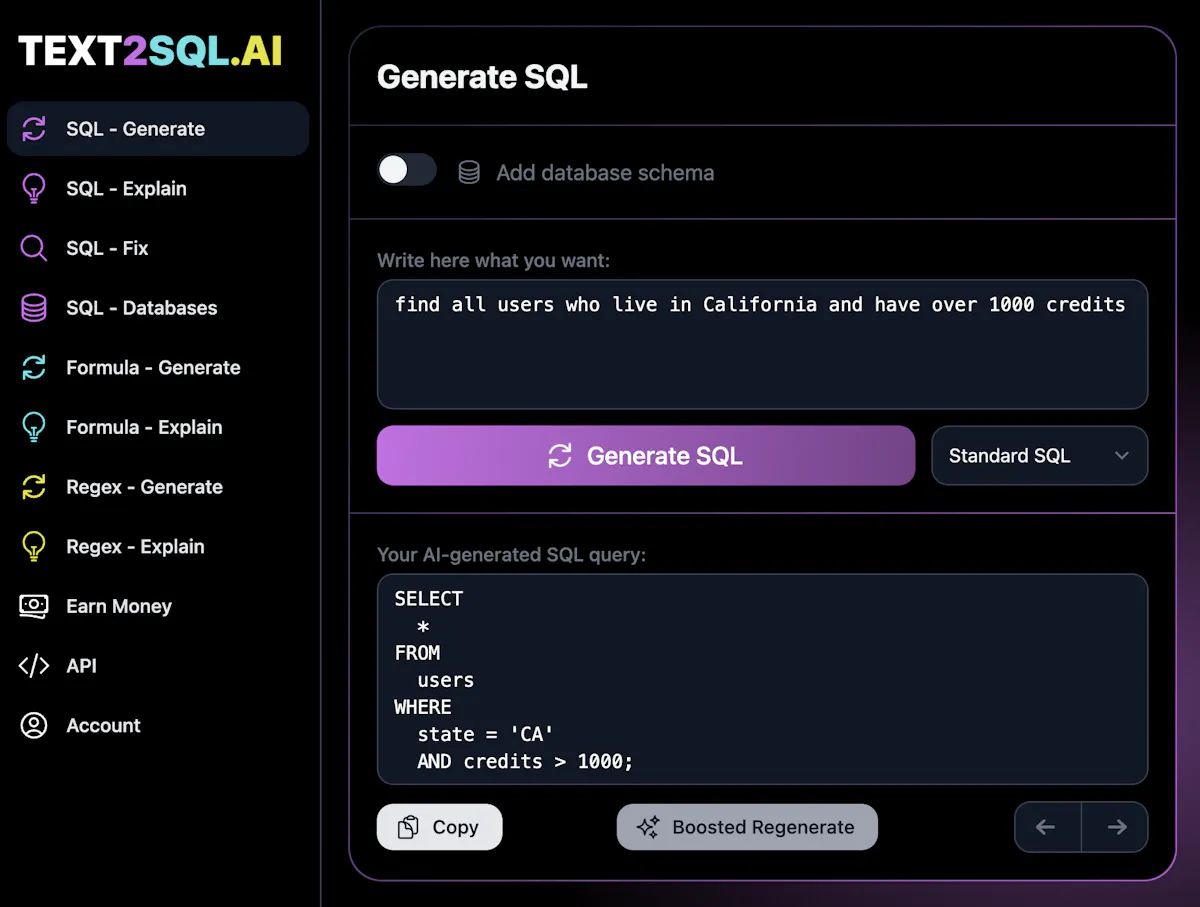
接下来,我们来探究 Text2SQL 的具体实现步骤。目前,AI 应用落地的表里是,Agent 做面子,提示工程做里子。因此,一个直接的方法是将用户需求和数据库的 Schema 一并提交给大型模型,由模型来生成相应的 SQL 语句。对于那些热衷于模型微调和训练的“炼丹术士”,可以关注下 Hrida-T2SQL-3B-V0.1 这个专门为 Text2SQL 设计的小模型。对于像我这样的 NLP 民科,自然不会去挑战这种高难度任务。按照这个思路,第一步是获取数据库的 Schema,即:了解数据库里哪些表、每张表里都有哪些字段以及这些字段具体是什么类型。这些信息对于大型模型生成准确的 SQL 语句至关重要。这里以 MySQL 数据库为例进行说明:
SELECT t.TABLE_NAME,
t.TABLE_COMMENT,
c.COLUMN_NAME,
c.COLUMN_COMMENT,
c.DATA_TYPE,
c.IS_NULLABLE
FROM INFORMATION_SCHEMA.TABLES t
LEFT JOIN INFORMATION_SCHEMA.COLUMNS c
ON c.TABLE_NAME = t.TABLE_NAME
WHERE t.TABLE_SCHEMA = 'Chinook'
其中,Chinook 是数据库的名称,此时,我们就可以得到下面的结果:
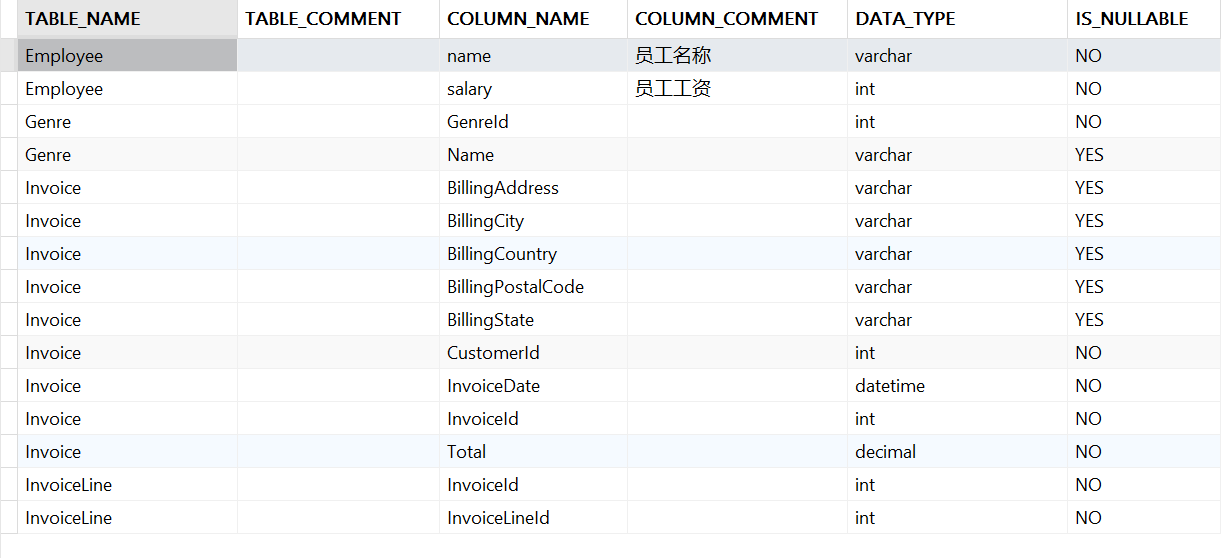
接下来,我们只需按照第一列进行分组,便能获取每张表涵盖的字段。在此过程中,我同时提取了表和列的注释信息。因为在那些喜欢用拼音或是缩写命名的人面前,即使是大模型亦不免相形见绌。如果你的数据库表结构设计本就混乱不堪,不要说大模型,只怕是连神仙都难救。现在,让我们通过代码生成数据库的 Schema 信息:
// 获取表描述信息
private async Task<IEnumerable<TableDescriptor>> GetTableDescriptorsAsync(string databaseName)
{
var sqlText =
@"SELECT t.TABLE_NAME,
t.TABLE_COMMENT,
c.COLUMN_NAME,
c.COLUMN_COMMENT,
c.DATA_TYPE,
c.IS_NULLABLE
FROM INFORMATION_SCHEMA.TABLES t
LEFT JOIN INFORMATION_SCHEMA.COLUMNS c
ON c.TABLE_NAME = t.TABLE_NAME
WHERE t.TABLE_SCHEMA = '{0}'";
using var sqlClient = new SqlSugarClient(_connectionConfig);
var rows = await sqlClient.Ado.SqlQueryAsync<dynamic>(string.Format(sqlText, databaseName));
if (rows.Count == 0) return Enumerable.Empty<TableDescriptor>();
return rows.GroupBy(x => x.TABLE_NAME).Select(g =>
{
return new TableDescriptor()
{
Name = g.ToList()[0].TABLE_NAME,
Description = g.ToList()[0].TABLE_COMMENT,
Columns = AsColumnDescriptors(g.ToList())
};
}).ToList();
}
// 获取列描述信息
private IEnumerable<ColumnDescriptor> AsColumnDescriptors(List<dynamic> rows)
{
return rows.Select(x => new ColumnDescriptor()
{
Name = x.COLUMN_NAME,
DataType = x.DATA_TYPE,
Description = x.COLUMN_COMMENT,
IsNullable = x.IS_NULLABLE == "YES"
});
}
// 生成 Schema
private string GeneratorDatabaseSchema(IEnumerable<TableDescriptor> tableDescriptors)
{
var stringBuilder = new StringBuilder();
foreach (var tableDescriptor in tableDescriptors)
{
stringBuilder.AppendLine($"{tableDescriptor.Name}, {tableDescriptor.Description}");
foreach (var columnDescriptor in tableDescriptor.Columns)
{
stringBuilder.AppendLine($" - {columnDescriptor.Name}, {columnDescriptor.DataType}, {columnDescriptor.Description}");
}
stringBuilder.AppendLine();
}
return stringBuilder.ToString();
}
最终,通过 GenerateDatabaseSchema() 方法,我们可以得到下面这样的结果:
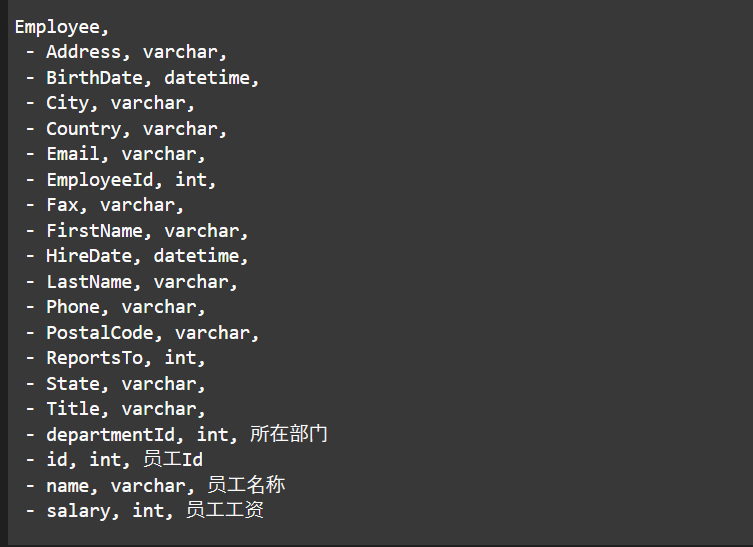
接下来,就非常简单啦,我们只需要将这份 Schema 作为参数传入提示词模板即可,这份提示词可以在 这里 找到:
[KernelFunction]
[Description("根据用户的输入生成和执行 SQL 并返回 Markdown 形式的表格数据")]
public async Task<string> QueryAsync([Description("用户输入")] string input, Kernel kernel)
{
var tableDescriptor = await GetTableDescriptorsAsync("Chinook");
var databaseSchema = GeneratorDatabaseSchema(tableDescriptor);
var promptTemplate = _promptTemplateService.LoadTemplate("Text2SQL.txt");
promptTemplate.AddVariable("input", input);
promptTemplate.AddVariable("schema", databaseSchema);
var functionResult = await promptTemplate.InvokeAsync(kernel);
var generatedSQL = functionResult.GetValue<string>().Replace("```sql", "").Replace("```", "");
_logger.LogInformation("Generated SQL: {0}", generatedSQL);
var queryResult = await ExecuteSQLAsync(generatedSQL);
return queryResult;
}
当我们拥有可以 “思考” 的 Agent 以后,可以非常容易地为其扩展出 Text2SQL 能力。如下图所示,当用户给定一个查询时,首先是通过大模型生成 SQL 语句,其次是执行 SQL 语句返回结果,最后是大模型观察结果生成最终答案:
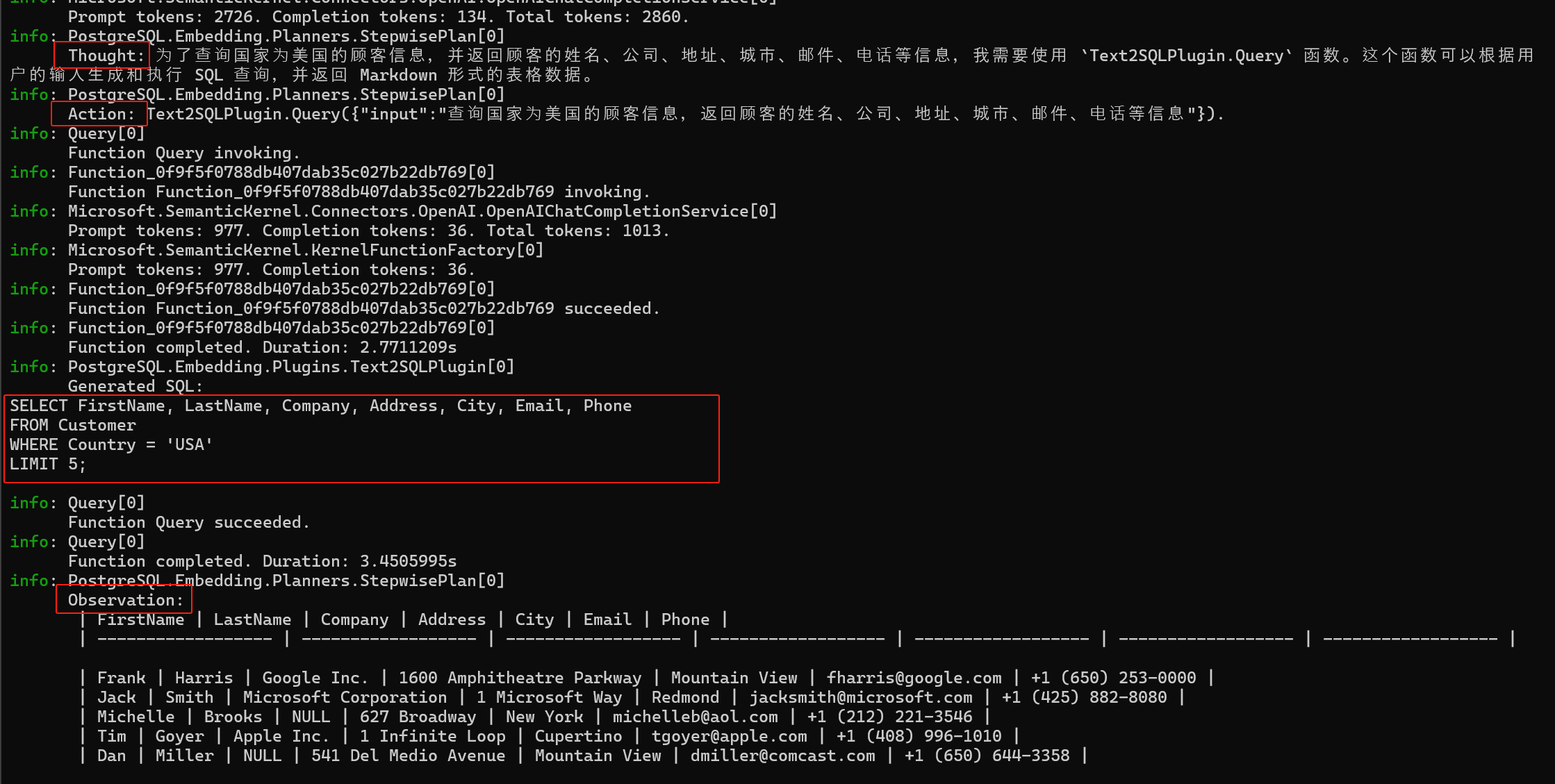
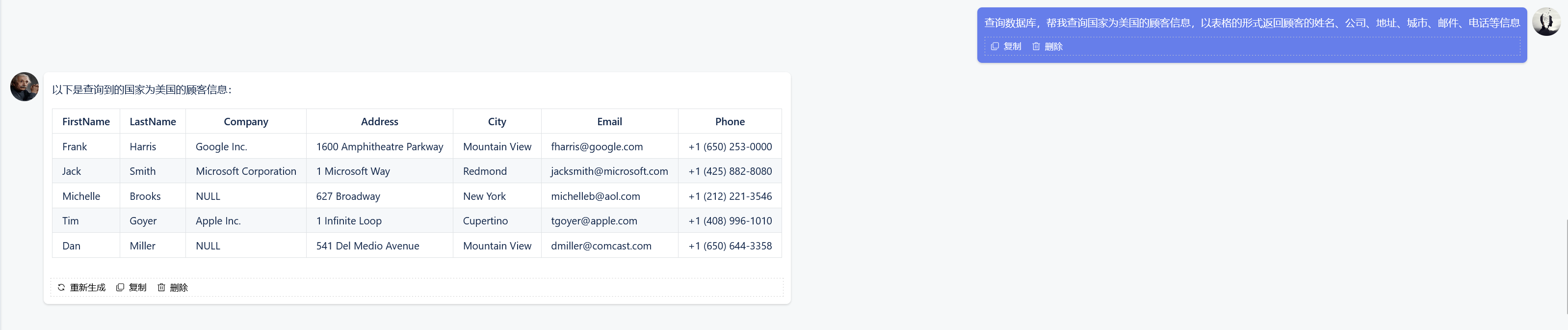
当然,这种方案本质上依赖于模型的推理能力。对于常规查询,大模型通常可以做到游刃有余。然而,对于复杂的查询,如子查询、窗口函数、LeetCode 等,大模型往往开始显得力不从心,经常出现下面这几类问题:
- 生成的 SQL 有语法错误
- 使用了未定义的函数/变量
- 查询结果重复
我个人认为,总体而言,Text2SQL 技术虽有不足,但谓瑕不掩瑜,它让大模型有了连接关系型数据库的可能。当人工智能成为一种通用能力和基础设置,它便不应该再成为普通人使用和学习的门槛。从这个角度出发,我们应该让世间万物都和大模型连接在一起,未来它应该会变成得像水、电、天然气一样不可或缺,大家觉得呢?
对效率的反思
作为程序员,或者说是技术人员,我们总是天然地追求着效率的最大化,甚至我们做过的每一个信息化的项目,都在加速着信息在互联网中的流动。可遗憾的是,我们是否掉进了由技术编织而成的名为“效率提升”的陷阱呢?正如我们有各种各样的聊天软件,可我们不见得就知道坐在你对面的那个人此刻在想些什么,甚至于我们在群组中被 @ 的时候,我们不见得有耐心读完、读懂全部信息,但我们还是要礼节性的打上一个:white_check_mark:。如今,无论天涯还是咫尺,都可以顺着网线来到你面前,这是“效率提升”这场运动带来的便利。可与此同时,在微博、小红书、抖音等社交媒体的影响下,这个世界亦开始变得不再那么真实。在一个程序员心目中,技术是没有立场、绝对正义的,可如果连正义都只是相对的,那么修饰正义的“绝对”就变得讽刺起来。于是,我们看到,在算法的驱使下,每个人被关进信息茧房,从此只能看到自己想看到的;于是,我们看到,在算法的算计下,外卖员的时间不断压缩,从此只能靠违章来争分夺秒;于是,我们看到,在敏捷的理论下,开发的周期越来越短,从此只能靠加班来卷赢同行……

我当然相信新的技术能带来新的机遇,但我们真正应该追求的效率,是那种可以让大多数人感到幸福的效率。百度发展 L4 级别无人驾驶,这件事情当然是正确的,甚至是非做不可的事情。可至少在当下这个时刻,提升效率并不是唯一正确的事情,就像生成式 AI 可以快速生成文本、图片甚至是视频,但这件事情并没有让我们从繁重的事务性工作中解脱出来,反而造成了人类世界的内卷,并且这种内卷完全没有赢的可能。以最新的 Claude 3.5 Sonnet 模型为例,它在某些情况下甚至可以媲美高级研究人员。这种效率提升对于普通智力水平的职场人来说,无异于降维打击。在当下这样一个充满危机感的职场环境下,像萝卜快跑这样的效率提升,除了断送掉“铁人三项”以外,我认为它并不会让更多的人感到幸福。一句话简单总结,事情是对的,但不合时宜。在职场中有一种潜规则,即:在工作中为员工设置各种障碍,从而使得每一个人都有事可做,这可以认为是职场中的不宣之秘。技术当然没有立场,有立场的从来都是人,如果一部分人坚持要提升效率、破旧立新,那只能说明在某个地方真的是有利可图。
本文小结
我有一个不太好的习惯:当感觉心中的想法不足以填满一篇博客时,我总想释放出脑中的所有念头,并试图将它们全部塞进同一篇文章中。这样做的后果是,我写出的文章题目与文章内容间只有松散的联系。如果你读到这里,依旧感到困惑,请允许我在此表达歉意。可能是因为我每天都在接触大量碎片化信息,难以在短时间内整理出清晰的知识体系。特别是在我实现 StepwisePlanner 这段时间,我突然觉得 LLM Agent 索然无味。尽管,我每天都能在微信群里看到大量 AI 资讯,整个行业看起来一派繁荣,但现实中频频传来的失业潮、AI行业无的放矢的普遍现象,再加上西安持续下了半个多月的雨,绵绵不绝,让我深切感受到现实与理想之间的鸿沟。因此,当我开始写这篇博客时,我想表达的远不止 Text2SQL 这样简单,可一时间我只能找到这样一个话题;正如我想做的是 Agent,可是目前我只能做到这种程度。当我向同事演示 Text2SQL 时,他安慰我说:“这不是你能力问题,现在模型就这样”。我开始有些分辨不出这句话的真假,人类是如此地渴望情绪价值,可如果 AI 满足了你所有的情绪需求,你真的会感到满足吗?人类明明拥有足够的上下文信息来推导出答案,但人们不见得就会主动说出来,不是吗?


