引言
最近看到一个有趣的观点:当你试图对 AI 进行某种界定时,会发现诸如知识密集型、资本密集型、劳动密集型、资源密集型这些类别,似乎都适用于它。首先,AI 无疑是知识密集型和资本密集型的。然而,考虑到数据标注等工作需要投入大量人力,AI 表现出劳动密集型的特征。与此同时,AI 的训练和推理依赖庞大的算力,而这背后离不开巨大的资源支持,所以它还具备资源密集型的属性。这种“什么都是,又什么都不是”、难以简单归类的状态,恰恰构成了 AI 产业最根本的特性。在持续使用 Claude Code 两个月以后,一切都归于寂静,曾经的 Cursor 和 Windsurf 亦是如此。秋风渐起,天气转凉,最近发布的 GPT-5 和 DeepSeek-v3.1 表现不温不火,反倒是谷歌凭借 Nano Banana 再次成为焦点。当然,相比于讨论这些无关紧要的事情,我更关注 AI 技术在实际场景中的落地。因此,在这篇博客中,我想和大家分享如何基于 Supabase 快速构建一个可用的 AI 应用。
为什么选择 Supabase?
时间来到 2025 年,横亘在我们面前的最大危机,已从「怎么做」变成「做什么」。Know-How 里的 Know 与 How,正在逐渐被 AI 接管,留给我们的只剩下 What——我们究竟该让技术指向何方。放眼望去,市面上可供开发 AI 应用的工具琳琅满目,令人目不暇接。以笔者为例,Cursor、Windsurf、Cline、Claude Code、Gemini CLI,各种工具几乎都尝试了一遍,而如今最常用的,反而是 VSCode 内置的 GitHub Copilot。结合我有限的认知,我对这些工具做了如下划分,大家可以按图索骥,选择适合自己的工具进行尝试:
- 编辑器/IDE/插件类:Cursor、Windsurf、Cline、GitHub Copilot 等
- CLI/工具类: Claude Code、Gemini CLI 等
- 一站式部署类:Bolt.New、v0 等
- 低代码/工作流:Coze、Dify、n8n 等
- 代码框架:LangGraph、Semantic Kernel、AutoGen、CrewAI 等
那么,相对于这些这些方案,Supabase 有什么优势呢?开发 AI 应用时,我们真正需要的,是一个既能满足 AI 应用需求,又能快速开发和部署的平台。而 Supabase 正是这样一个理想的平台,它具有以下优势:
开箱即用的后端即服务(BaaS)
Supabase 提供了一套完整的后端服务,囊括了数据库、认证、存储、实时数据、边缘函数、向量、定时任务、队列等功能。这意味着开发者无需从头搭建后端架构,可以将更多精力专注于 AI 应用本身的开发。例如,Supabase 内置的 PostgreSQL 数据库具备强大的查询能力,可以高效地处理 AI 应用中的数据存储和检索需求。此外,它还免费提供 500M 的数据库容量、500M 内存、每月5万活跃用户的额度,且支持不限次数的 API 调用。因此,如果你想快速部署和验证产品,Supabase 无疑是一个理想的起点。
天然契合 AI
Supabase 天然契合 AI 时代的核心需求。首先,其内置的 PostgreSQL 数据库支持向量存储与检索,可通过 pgvector 扩展实现最高 2000 维的向量索引。其次,Supabase 在 Edge Runtime 中内置了一个 384 个维度的向量模型 gte-small,这使开发者能够快速在边缘函数中构建 RAG 应用。此外,它还支持集成第三方 AI 工具如 LangChain、Hugging Face、LlamaIndex 等等。最后,结合 Text2SQL 技术,你可以构建以数据为核心的 AI 应用。下图展示了一个基于 Supabase 实现的 AI 应用示例,它能够对本博客中的文章进行智能检索:

开源社区支持
Supabase 是一个开源项目,拥有活跃的社区和丰富的文档资源。开发者可以在社区中寻求帮助或分享经验。例如:
- Babelfish.ai:该项目结合 Huggingface Transformer.js 和 Supabase Realtime,实现了实时语音转录和翻译功能。
- Huggingface Image Captioning:通过 Edge Function 调用 HuggingFace Inference API,自动为图片生成标题。
需要注意的是,目前 Supabase 的商业版与开源版在功能上存在差异,因此,我们主要针对商业版进行后续探索。
Supabase 与 AI
接下来,我们将聚焦 Supabase 在 AI 方面的核心特性,并尝试从三个不同的维度展开叙述,即:支撑语义搜索的向量数据库、构建复杂 Agent 的 LangGraph,以及统一管理模型调用的 AI 网关。
向量数据库
如果说,AI 应用的核心是数据。那么, Supabase 内置的 PostgreSQL 则是存储和管理这些数据的理想选择。现在,让我们从构建一个 RAG 应用开始,第一步是为 PostgreSQL 启用以下扩展:
create extension if not exists pgcrypto;
create extension if not exists vector;
为了实现语义检索功能,我们将创建两张核心表:documents(文档表)和 document_embeddings(向量表):
--创建文档表
create table if not exists documents (
id uuid primary key default gen_random_uuid(),
url text not null,
content text not null,
hash text generated always as (encode(digest(content, 'sha256'), 'hex')) stored,
metadata jsonb null,
created_at timestamp with time zone default now()
);
--创建向量表
create table if not exists document_embeddings (
id uuid primary key default gen_random_uuid(),
document_id uuid not null references documents(id) on delete cascade,
chunk text not null,
embedding vector(384) not null,
created_at timestamp with time zone default now()
);
为了提高查询效率,我们在关键字段上建立索引,这里使用余弦相似度来衡量向量之间的距离:
--创建 IVFFlat 索引
create index if not exists idx_document_embeddings_embedding
on document_embeddings using ivfflat (embedding vector_cosine_ops)
with (lists = 100);
--为 document_id 添加索引
create index if not exists idx_document_embeddings_document_id
on document_embeddings (document_id);
现在,我们可以来编写一个数据库函数 match_documents,它可以检索出数据库中与当前向量最接近的文档:
--创建函数 match_documents
create or replace function match_documents(
query_embedding vector(384),
match_count int default 5,
min_score float default 0
)
returns table (
id uuid,
document_id uuid,
chunk text,
score float
)
language sql stable
as $$
select de.id, de.document_id, de.chunk,
1 - (de.embedding <=> query_embedding) as score
from document_embeddings de
where (1 - (de.embedding <=> query_embedding)) >= min_score
order by de.embedding <=> query_embedding
limit greatest(match_count, 1);
$$;
至此,一个最简单的 RAG 应用跃然纸上,下面是核心代码片段:
import { createClient } from 'https://esm.sh/@supabase/supabase-js@2';
// 初始化 Supabase 客户端
const url = Deno.env.get('SUPABASE_URL');
const key = Deno.env.get('SUPABASE_SERVICE_ROLE_KEY');
const supa = createClient(url, key, { auth: { persistSession: false }});
// 初始化向量模型
const session = new Supabase.ai.Session('gte-small');
// 生成向量
const embedding = await session.run("Supabase 的优缺点都有哪些", {
mean_pool: true,
normalize: true
});
// 向量检索
const { data: matches, error } = await supa.rpc("match_documents", {
query_embedding: embedding,
match_count: 5,
min_score: 0.75
});
// 上下文构建
const context = (matches ?? [])
.map((m, i)=>`# Chunk ${i + 1} (score=${m.score.toFixed(3)})\n${m.chunk}`)
.join('\n\n');
// ...
// 调用 LLM
// ...
以此为基础,后续只需要将上下文传递给 LLM 即可。Supabase 的 Edge Runtime 基于 Deno 环境,因此你可以直接使用 Fetch API 调用 OpenAI 或 DeepSeek 等相关接口。需要注意的是,当前 Edge Runtime 只支持 gte-small 模型,这是一个 384 维的向量模型。如果你需要生成更高维数的向量,可考虑使用 HuggingFace 或者 OpenAI 的 Embedding API。下图展示了一个正在开发中的应用示例:

在实际项目中,为提高检索召回率,通常需要融合多种检索方案。Supabase 主要支持以下两种方式:
- 全文检索:基于关键字匹配,需要结合
to_tsvector、to_tsquery、ts_rank_cd等函数,中文需要安装pg_jieba扩展。 - 向量检索:基于语义相似性计算,需要启用
pgvector扩展以支持向量存储与检索。
笔者在 《使用 EFCore 和 PostgreSQL 实现向量存储及检索》一文中曾对相关技术做过介绍,如果大家不熟悉上述内容,建议先阅读这篇文章。本文将重点聚焦于 Supabase 的相关实现,故而 PostgreSQL 部分不再详细展开。
LangGraph
不可否认,RAG 是目前最基础、最普遍的 AI 应用之一,但它更像一个“热身”阶段。业界的最终演进方向,是开发出能够理解并执行复杂指令的智能体(Agent)。在 Supabase 中,我们可以借助 Edge Functions 与 LangGraph 实现这一目标。例如,可将上文中的 RAG 应用封装为工具,再结合 Text2SQL 与 Tavily 等技术,打造能够从多种数据源中检索信息的智能体。核心代码片段如下所示:
import { ChatOpenAI } from "npm:@langchain/openai";
import { MemorySaver } from "npm:@langchain/langgraph";
import { createReactAgent } from "npm:@langchain/langgraph/prebuilt";
import { loadTools } from "./tools.ts";
// 加载工具
const agentTools = loadTools();
// 初始化 LLM
const agentModel = new ChatOpenAI({
temperature: 0,
apiKey: Deno.env.get("DEEPSEEK_API_KEY"),
model: "deepseek-chat",
configuration: {
baseURL: "https://api.deepseek.com"
}
});
// 初始化记忆
const agentCheckpointer = new MemorySaver();
// 创建一个 ReAct 模式的智能体
const agent = createReactAgent({
llm: agentModel,
tools: agentTools,
checkpointSaver: agentCheckpointer
});
在 Supabase 中,边缘函数的基本形态是对外暴露一个 API 接口,并且这个函数可以实时修改、部署。如果你使用过 LeanCloud、Vercel、Cloudflare,相信你会非常熟悉这一切。下面是一个经过简化的 Edge Function 示例:
import { createSSEStream } from "./utils.ts";
// ...
Deno.serve(async (req) => {
const { query,thread_id } = await req.json();
const { stream, send, close } = createSSEStream();
// 调用智能体
const result = await agent.invoke({
messages: [{
role: "system",
content: SYSTEM_PROMPT
}, {
role: "user",
content: query
}]
}, {
configurable: {
thread_id: thread_id ?? "default"
}
});
// ...
// 返回 SSE 数据流
return new Response(stream, {
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
}
})
});
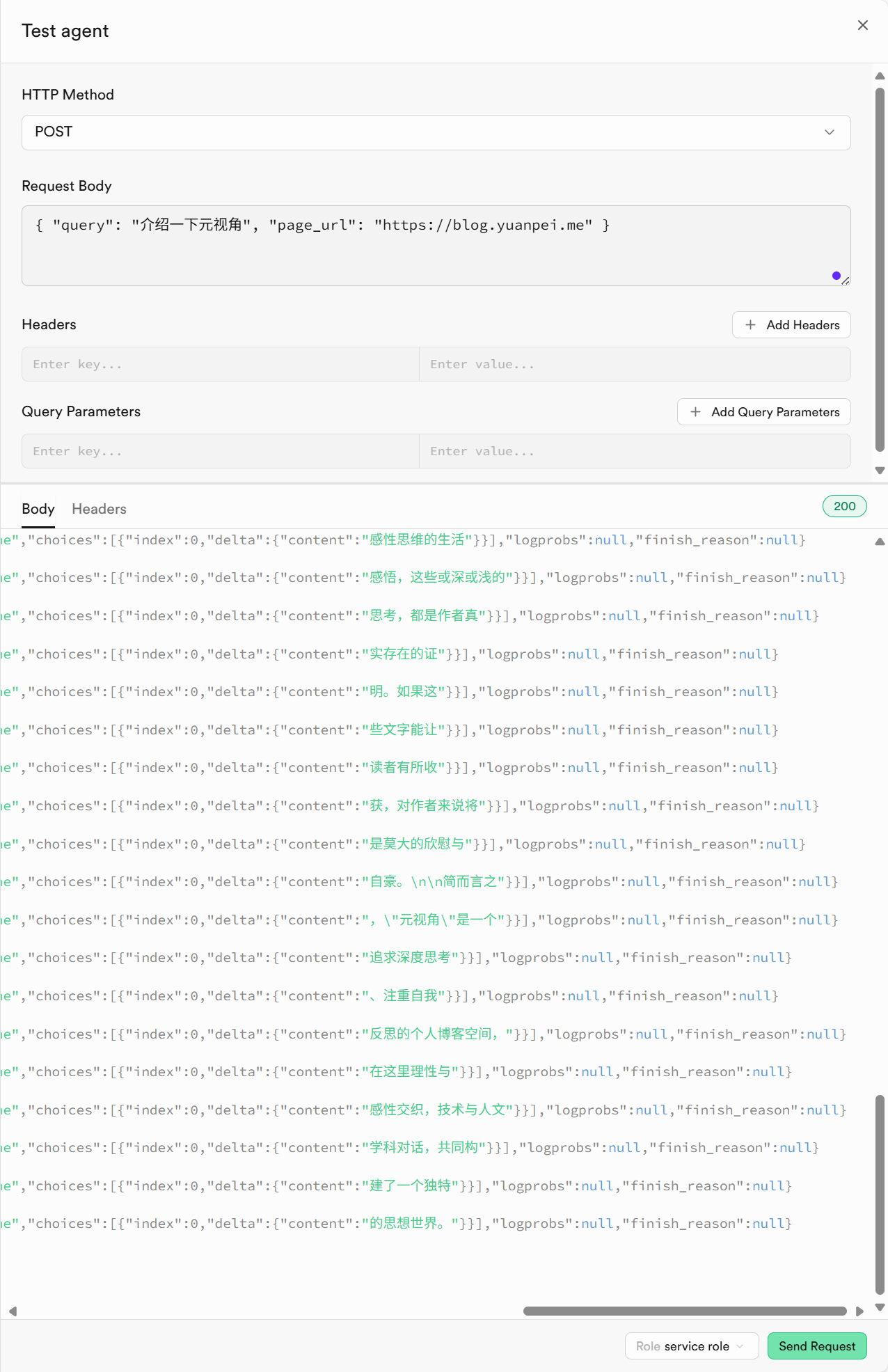
如下图所示,我们可直接在 Supabase 中编写和测试边缘函数。当笔者询问“元视角”时,程序以 Server-Sent Events(SSE)的形式返回答案。这恰恰印证了 Supabase 的核心优势:它可以让我们专注于 AI 应用本身,而无需分心于后端基础设施的构建与维护。作为一名后端开发者,在体验到这种高效的 Serverless 模式之后,我的心情变得复杂。我不禁想起第一次使用 Cursor 完成任务时的经历,AI 带来的效率提升固然令人惊叹,可失去对底层代码的掌控更令我感到隐隐的不安。如果说,代码是一种负债,那么,Vibe Coding 或许更接近于某种借贷。
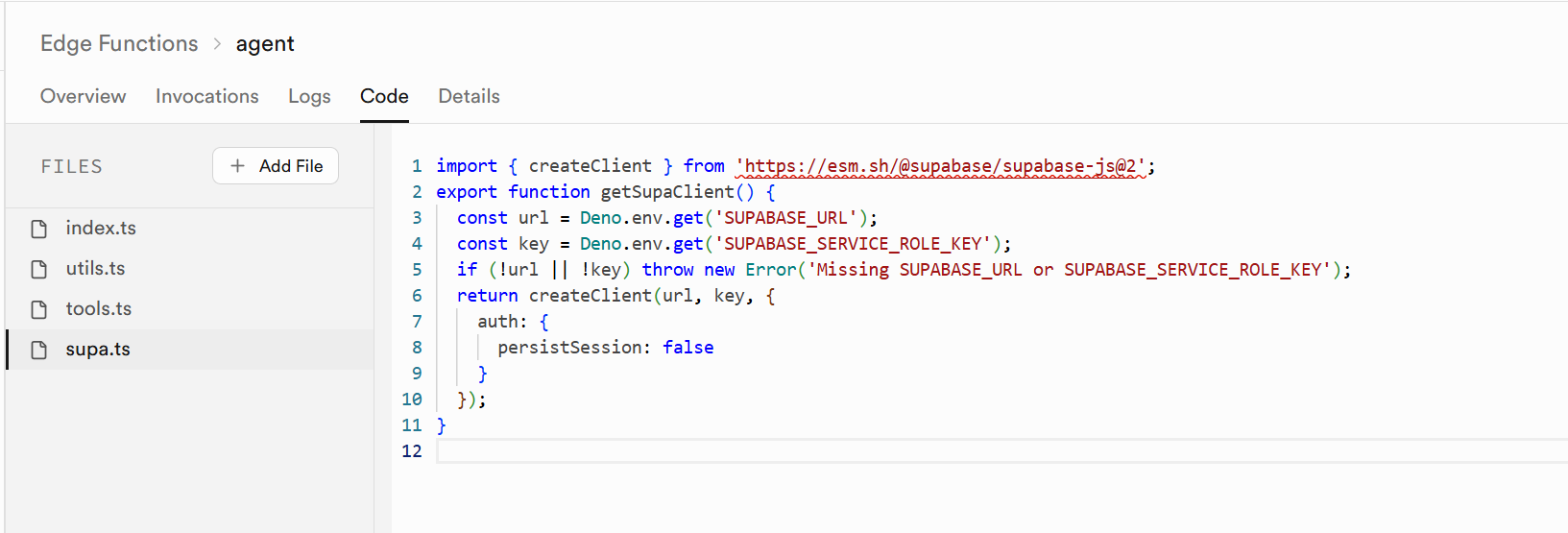
对于相对简单的业务需求,可以直接在 Supabase 中编写边缘函数;而当业务逻辑较为复杂,或更注重工程化实践时,则建议通过 Supabase CLI 实现更精细化的开发和维护。下面是一个 Edge Function 从开发到部署的完整流程:
# Initialize Your Project
supabase init my-edge-functions-project
cd my-edge-functions-project
# Create Your Function
supabase functions new hello-world
# Test Your Function
supabase functions serve hello-world
# Deolpy Your Function
supabase login
supabase projects list
supabase link --project-ref [YOUR_PROJECT_ID]
supabase functions deploy hello-world
关于 Edge Function 工程化实践的更多细节,请查阅以下链接:
AI 网关
到目前为止,我认为 AI 应用并不存在所谓的“护城河”,真正的壁垒,可以是高质量的数据、独特的业务洞见、高效的流程,唯独不能是 AI 本身。以 Windsurf 为例,早期它依靠价格优势尚能与 Cursor 分庭抗礼。然而,当 Anthropic 对其采取模型“断供”措施后,Windsurf 的核心竞争力和用户黏性迅速发生衰减。一个不争的事实是,在 AI 时代,用户的注意力无时无刻不再被更新、更强大的模型所吸引。更何况,模型与智能体之间的边界,如今正在变得越来越模糊。所以,接下来,我想进一步延伸出一个话题:AI 网关。既然在 AI 时代,AI 并非护城河本身,那么,什么才是我们真正应该构建的能力呢?在我看来,这种能力,是一种随时可以离开的能力,是一种随时可以从一种模型平滑切换到另一种模型的能力,我愿意将其称之为“一种架构上的从容与自由”。
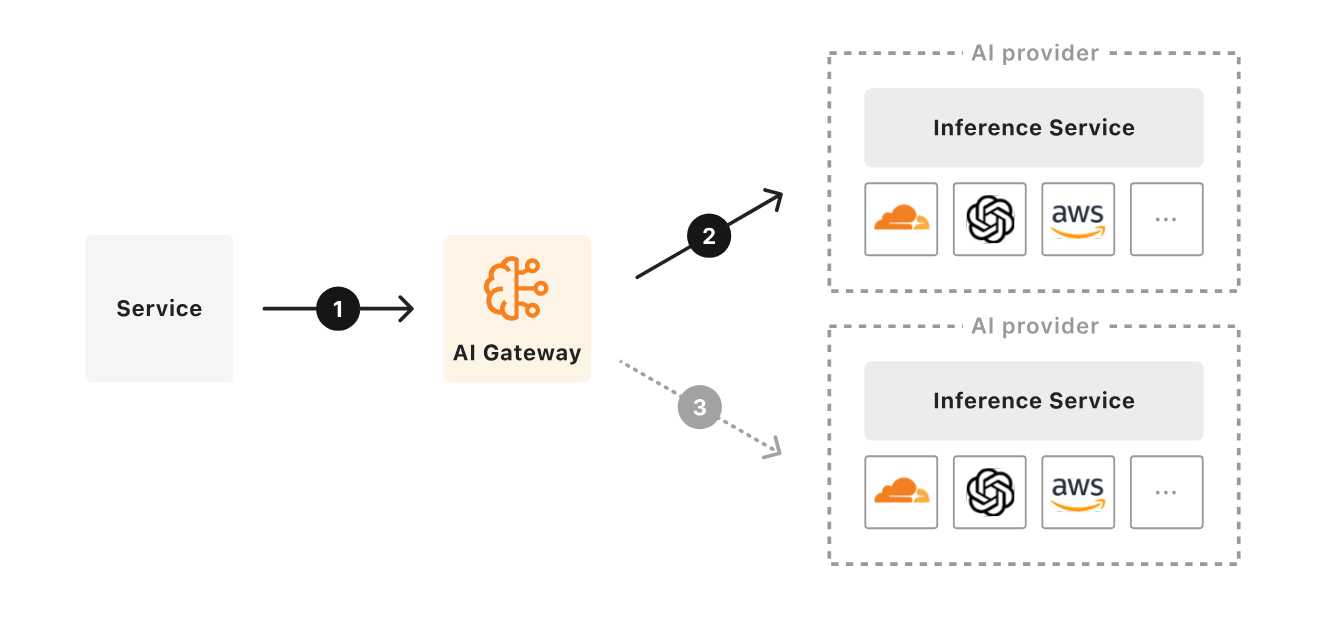
去年,你可能听说过一个名为 One API 的开源项目,它致力于通过统一的 API 格式兼容主流大语言模型(LLM)。目前,对于市面上的大部分模型而言,只要它的 API 兼容 OpenAI 的 API,理论上你都可以用相同的方式接入。然而,自从 DeepSeek-R1 引入“思考”过程以后,不同模型之间的差异正在逐步扩大。当然,你可以选择像 OpenRouter 这样的第三方模型聚合平台。但对于一个完整的 AI 应用而言,仅仅实现模型层面的集成还远远不够,你还需要统一的工具(MCP)注册于发现机制、以及更加透明的、可以精细到每一个 token 的可观测能力。正因为如此,我们看到诸如 Vercel AI Gateway、Higress、Cloudflare AI Gateway、腾讯云 EdgeOne 等产品正在不断涌现。其中,不乏传统网关厂商积极开展这一新兴赛道的布局。我的想法是,或许我们可以借助 Edge Functions 开发一个轻量级的 AI 网关,将 Claude、HuggingFace、ModelScope 以及 Gemini 等服务整合起来。
本文小结
其实,基于 Supabase 构建 AI 应用这个想法,早在两三个月前就已经在我心里悄悄酝酿了。最初,我只是打算将本地数据库迁移到 Supabase 上,可随着对它的进一步了解,我逐渐意识到,它并不只是一个简单的 PostgreSQL 替代品。所以,我对它的定位,从最初的“数据存储方案”转向了“应用开发平台”。之后,我开始尝试用 Edge Functions 编写一些简单的业务逻辑,并在其中实现了一个 RAG 应用,接着又引入 LangGraph 来构建智能体(Agent)。而你在这篇文章中所看到的,正是这一系列探索的结果。虽然 Cloudflare 的 Workers AI 提供了类似的功能,但我个人感觉 Supabase 更加纯粹、更容易上手一点,因此,它更贴合我当前全栈开发的节奏和习惯。对我而言,Serverless 为后端开发带来了全新的体验,而对前端和 JavaScript 而言,它或许正意味着一个新的机遇。


