有时候,我觉得人类还真是种擅长画地为牢的动物,因为突然发现,当人们以文化/理念的名义形成团体/圈子的时候,其结局都不可避免地走向了筛选和区分的道路。或许,大家都不约而同地笃信,在成年人的世界里,那条不成文的社交潜规则——“只筛选不教育,只选择不改变”。与千百年前百家争鸣不同,团体/圈子间并不热衷于交流,倒像是一种标签化的分类方式,甚至是一种非黑即白的二元分类方式。比如,通常人们认为男性不能讨论女性主义,可我经常在女性主义视角下看到对男性的讨论。女性朋友们一致认为,女性种种不幸完全是由男性以及男性背后的父权造成的。于是,在小红书上打着不被定义的标签的女性们,自顾自地定义着别人。亦或者,在这个内卷的世界里,人们被互相定义、被资本定义、被用户画像定义、被美颜相机定义……这种种的定义,最终会成为我们所有人的宿命。鲁迅先生说,中国人的性情是喜欢调和折中的,对此我表示怀疑。因为,以如今的现状而言,中国人或许更喜欢玉石俱焚。在我看来,标签是定义、是附和、是选择,无论我们是否知晓,那条路是否能代表未来。
是非善恶
最近,Meta 发布了 Llama3,一时风光无二。微软不甘示弱,紧随其后发布了 Phi-3。曾经,我认为在小红书上检索信息比百度更高效,可当我批评完百度的竞价排名后,我发现小红书上的广告问题更严重,特别是 AI 的加入让这一问题愈发严重。回到 AI 话题,最近人们对于大模型的态度大致可以总结为:对 Llama3 和 Phi-3 寄予厚望,认为它们接近 GPT-4 的水平,而对 OpenAI 以及 GPT-5 的前景则持续看衰。我不太关心这些预期,我在意的是新模型发布以后,各路牛鬼蛇神都可以活跃起来。小红书上有一篇帖子提到,Llama3 的发布使得本地化 RAG 更有意义,并分享了一个使用 LlamaIndex 实现 RAG 的案例,随后是小红书上经典的套路:私信、拉群、发链接。我对帖子中的观点保留态度,因为 Llama3 作为大型模型,主要解决的是推理问题;而 RAG 是检索 + 生成的方案,其核心在于提高检索的召回率,即:问题与文本块之间的相关性。显然,无论 Llama3 是否发布,RAG 都能正常落地。大型模型的推理能力,影响的是最终的生成结果,而非检索的召回率。
故事的结局是我遭到了反驳,对方质疑我对 RAG 的理解,并建议我阅读她主页的某个帖子,据说是 RAG 论文作者在斯坦福的讲课内容。我原本是打算去学习的,可戏剧性的是,我被对方拉黑了。我还能再说什么呢?当然选择原谅对方。为了证明我对 RAG 的理解没有偏差,我决定分享我最近对于 Rewrite 和 Rerank 的体悟。我想明确指出的是,无需使用 Llama3,只要提升检索部分的召回率,RAG 方案完全可以实施。实际上,我们甚至都不需要 GPT-4 级别的模型,选择一个合适的小模型足矣。我意识到,我最大的错误在于,试图在一个以信息差为生意的人面前打破信息壁垒,帮助他人摆脱知识的诅咒。正如我之前所述,某些团体或圈子的目的并非促进信息流通和交流,而是为了向特定的人群提供通行证,以便在来来往往的人群中筛选和区分同类。或许,你会认为你已经筛选出你想要的人,但从更广阔的视角来看,这不过是另一种傲慢与偏见。当然,你们权利忽视这些问题,就像我不在乎周围环境如何一样。作为一个崇尚科学的人,我只关心真理,除非你的真理更为真实。
实现 Rewrite
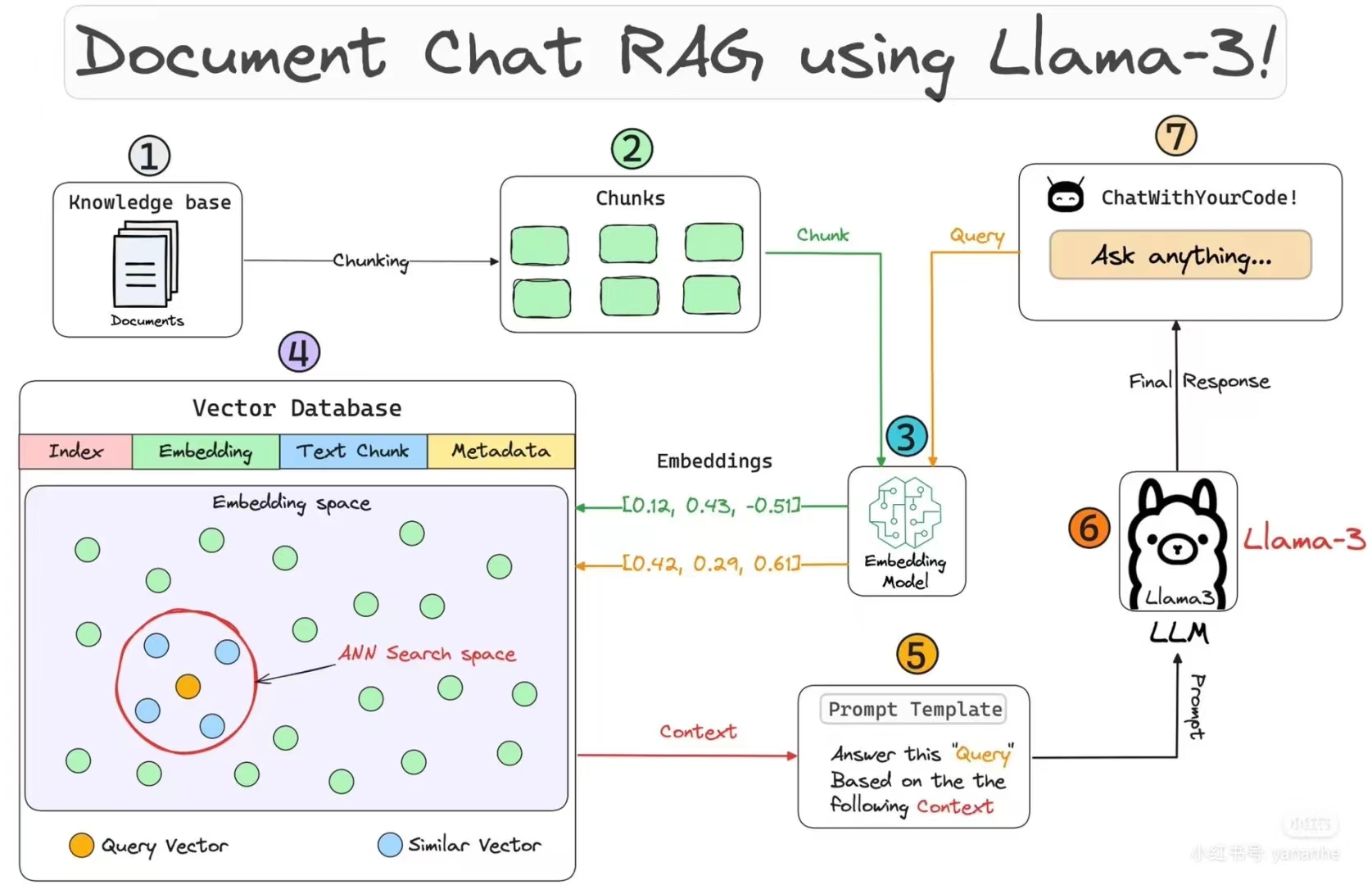
在 RAG 的语境中,Rewrite 是重写或者改写的意思。此时,诸位或许会困惑,为什么需要对用户输入的问题进行二次加工呢?在程序员群体中,有一本非常经典的书 ——《提问的智慧》,其核心观点是:在技术的世界里,当你提出一个问题时,最终能否得到有用的答案,往往取决于你提问和追问的方式。以此作为类比,众所周知,人类的输入通常随性而模糊,特别是在使用自然语言作为交互媒介的时候。在这种情况下,大语言模型难以准确理解人类的真实意图。因此,就需要对用户的原始查询进行改写,通过生成多个语义相似但是表述不同的问题,来提高或增强检索的多样性和覆盖面。由于重写后的查询会变得更为具体,故而,Rewrite 在缩小检索范围、提高检索相关性方面有一定的优势。例如,下面的提示词实现了对用户输入的改写:
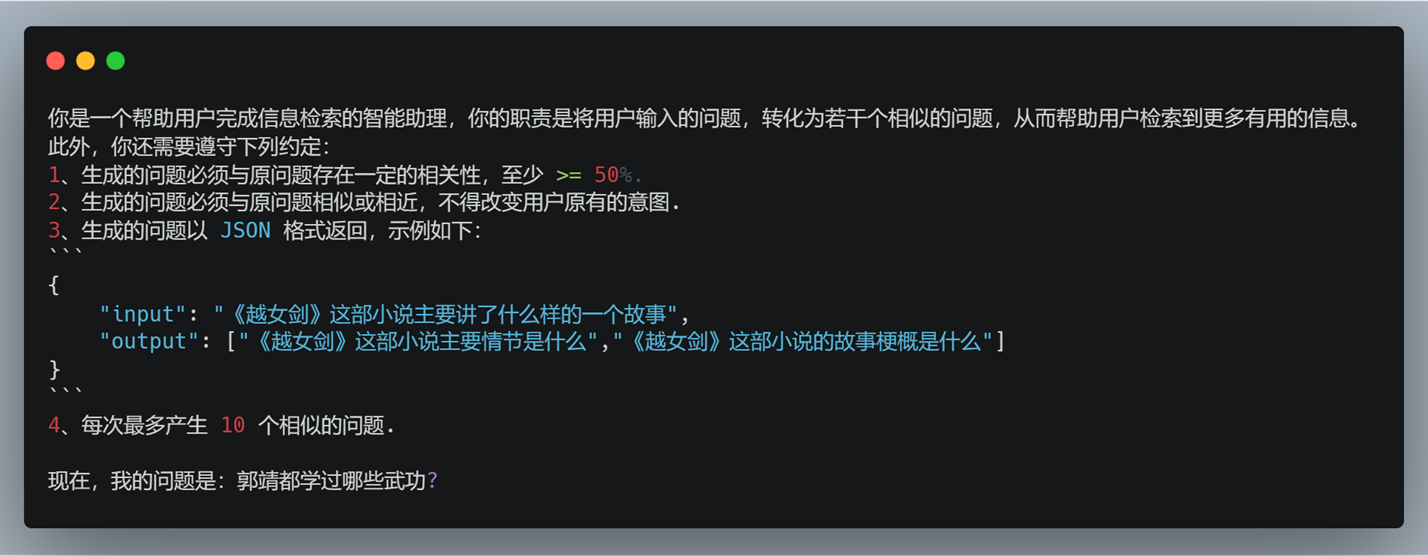
实际效果如何呢?我们可以分别在 Kimi 和 ChatGPT 中进行测试。如下图所示,左边为 Kimi,右边为 ChatGPT:
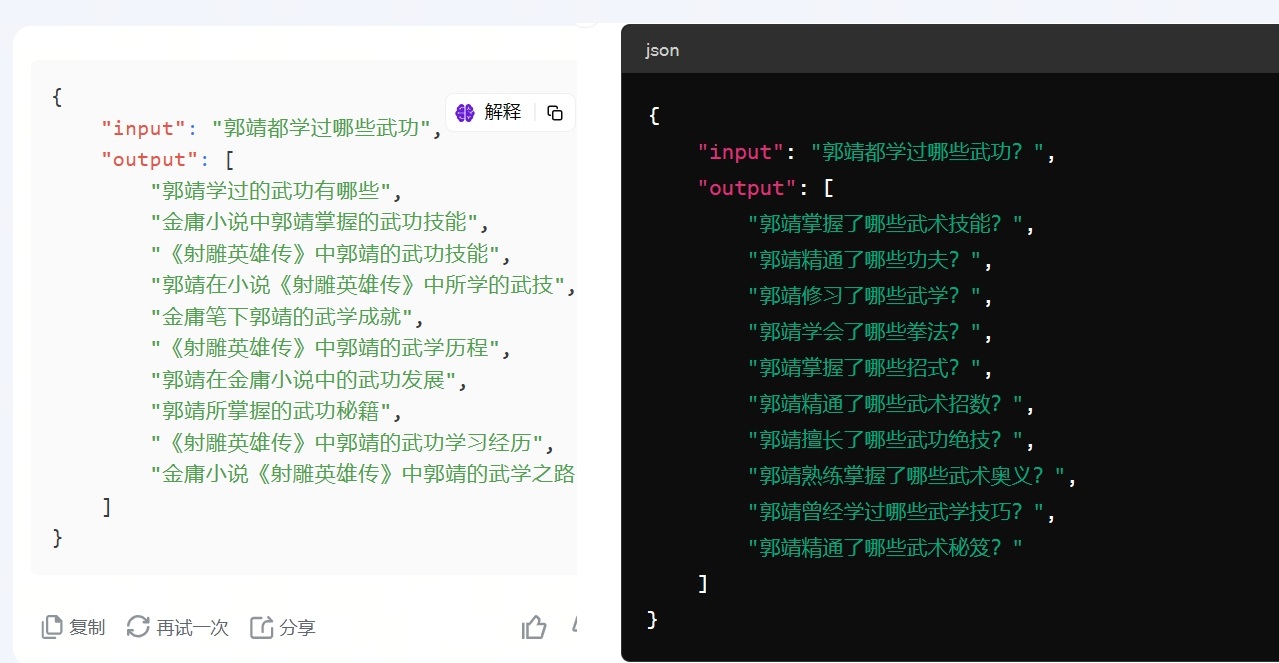
可以发现,Kimi 在改写的过程中,补充了更多的上下文,比如 “金庸”、“射雕英雄传”,而 ChatGPT 给出的答案则相对保守,甚至出现了 “奥义” 这种动漫作品中的元素。我承认,模型的推理能力是会影响到答案的生成,可这一切与 RAG 中的 Retrieval 无关,因为在那篇帖子里,对方分享的是最简单的 RAG 范式,自然就不包含 Rewrite 与 Rerank。所以,即便 Llama3 的推理能力得到了大幅度提升,它并不会对 RAG 有任何实质性的影响。不知这位女性朋友在评论区大杀四方的时候,是否想明白了这个道理?
# 对问题进行重写的提示词
rewrite_prompt_template = '''
你是一个帮助用户完成信息检索的智能助理,你的职责是将用户输入的问题,转化为若干个相似的问题,从而帮助用户检索到更多有用的信息。
此外,你还需要遵守下列约定:
1、生成的问题必须与原问题存在一定的相关性,至少 >= 50%
2、生成的问题必须与原问题相似或相近,不得改变用户原有的意图
3、生成的问题以 JSON 格式返回,示例如下:
```
{{
"input": "《越女剑》这部小说主要讲了什么样的一个故事",
"output": ["《越女剑》这部小说主要情节是什么","《越女剑》这部小说的故事梗概是什么"]
}}
```
4、每次最多产生 5 个相似的问题
现在,我的问题是:{question}
'''
好了,下面我们结合 LangChain 来做具体的工程实践。继续沿用上面的提示词模板,唯一需要注意的是,这里的 JSON 示例需要转义,因为它与变量 question 前后的花括号存在冲突,解决方案是使用两对花括号。方便起见,这里使用 LLMChain 来调用月之暗面的 API 接口,尽可能避免给大家增加心智负担:
llm = ChatOpenAI(
model_name='moonshot-v1-8k',
temperature=0.75,
openai_api_base='https://api.moonshot.cn/v1',
openai_api_key='<Moonshot API_KEY>',
streaming=False,
)
rewrite_chain = LLMChain(
llm=llm,
prompt=PromptTemplate(template=rewrite_prompt_template, input_variables=["question"]),
)
此时,问题就变得非常简单啦,下面是一个基本的实现思路:
def rewrite(question):
try:
result = rewrite_chain.invoke({'question': question})
text = result['text'].replace('```json','').replace('```','').replace('\n','').replace(' ','')
return json.loads(text)
except:
return {'input': question, 'output':[]}
因为,大模型返回的 JSON 是类似 Markdown 的语法格式,即:使用一对 ``` 符号包裹着,并且前面还有 “json” 字眼。所以,我们只需要对字符串做简单地替换即可。博主特别想吐槽的是,Python 内置的 json 模块在反序列化的时候,居然不允许里面有空格、换行符这种形式的字符存在。当然,LangChain 中提供了 输出解析器 来解决这个问题。这里,我们使用 PydanticOutputParser 即可处理 JSON 形式的返回值:
from langchain.output_parsers import PydanticOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
class RewriteResult(BaseModel):
input: str = Field(),
output: List[str] = Field(),
RewriteResultParser = PydanticOutputParser(pydantic_object=RewriteResult)
那么,如何使用这个解析器呢?此时,你有两种选择,我将其称之为,自动挡和手动挡:
# 自动挡:在构造 LLMChain 时直接指定 output_parser 参数
# 此时,invoke()方法的返回值中, text 属性是一个对象
rewrite_chain = LLMChain(
llm=llm,
prompt=PromptTemplate(template=rewrite_prompt_template, input_variables=["question"]),
output_parser=RewriteResultParser
)
# 手动挡:在 invoke() 方法调用后,调用 RewriteResultParser 的 parse() 方法
# 此时,处理方式与当前方案基本一致
result = rewrite_chain.invoke({'question': question})
RewriteResultParser.parse(result['text'])
至此,我们就在工程层面上实现了 Rewrite,当我们输入一个问题后,大模型可以帮我们生成 5 个相似的问题:

实现 Rerank
OK,现在我们来考虑一下 Rerank。在 RAG 的语境下,Rerank 表示对结果进行重排,由此便引出第一个问题:为什么需要重排?如果你熟悉 LangChain 中的 VectorStore 类,便会知道它实际上是提供了 similarity_search() 和 similarity_search_with_score() 这样两个方法。继续深究下去,后者本就可以度量出问题与文本间的相关性或者相似度,那么,我们不禁要再次发问,真的需要重排?如果想要回答这两个问题,就不得不提到目前在向量检索中普遍使用的 HNSW 算法。这个算法有什么问题呢?原来,为了实现快速检索,HNSW 算法会存在一点随机性,特别是在创建和维护图结构时,这就导致 Top-K 最邻近搜索中可能得到不准确的结果。此前,博主尝试使用金庸先生的 15 部武侠小说做知识库。当时遇到的问题是,通过向量数据库检索出来的内容与问题本身并不强相关。比如,郭靖这个人物主要登场于射雕三部曲,可是在检索的过程中,不可避免地出现了《雪山飞狐》、《连城诀》等小说的身影,这显然与事实不符。我们需要一种评估问题与文本间相关性的方案,Rerank 应运而生。
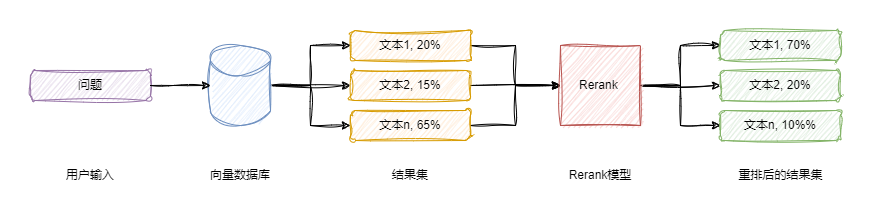
目前,推荐使用的 Rerank 模型主要有:闭源的 CohereAI,以及开源的 bge-reranker-large 和 bge-reranker-base。下面,我们以 BAAI/bge-reranker-large 这个模型为例进行说明,我个人推荐的、最简单的方案是使用 FlagEmbedding 这个库:
python -m pip install -U FlagEmbedding
from FlagEmbedding import FlagReranker
# 构造一个 FlagReranker 实例,设置 use_fp16 为 true 可以加快计算速度
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True)
# 计算两个文本间的相关性评分
score = reranker.compute_score(['夏天到了', '四五月的夏天热到爆炸'])
# 计算多对文本间的相关性评分
scores = reranker.compute_score([
['你好', 'How are you'],
['你好', 'Hello']
])
查阅 FlagReranker 的源代码,你会发现它本质上还是 transformer 库的封装。所以,当你运行上面这些示例代码的时候,你大概率还是会遇到从 HuggingFace 上下载模型失败这种沉疴宿疾。这里,请允许博主隆重介绍 ModelScope,一个由阿里维护的大模型社区,中文名称叫做魔搭社区,从这里下载模型要更为方便一点,并且它完全兼容 transformer 库。以上面的模型为例,我们需要将代码修改成下面这样:
import modelscope
reranker_model_dir = modelscope.snapshot_download('Xorbits/bge-reranker-base', revision='master')
reranker = FlagReranker(reranker_model_dir, use_fp16=True)
可以注意到,ModelScope 上的模型,基本上都是从 HuggingFace 上 fork 过来的,因此模型的名称可能会有差异,使用前建议先到社区里搜索一下,如果一定要找一个最具说服力的理由,那就是这里面的模型对中文更友好一点,相当于是别人重新训练或者微调过的模型,我个人使用起来倒是感觉还好。如下图所示,我们得到每一组文本的相关性评分。我想知道,这个结果是否符合你的心理预期呢?
 使用 bge-reranker-base 模型评估文本相关性-A
使用 bge-reranker-base 模型评估文本相关性-A
事实上,我们可以将 compute_score() 方法中的 normalize 参数设置为 true,使其结果归一化:
 使用 bge-reranker-base 模型评估文本相关性-B
使用 bge-reranker-base 模型评估文本相关性-B
效果展示
在实现了 Rewrite 和 Reranker 以后,我们就可以按照 RAG 常规的做法,将其串联起来,如下面的代码所示:
# 对用户输入的问题进行改写
rewrite_result = rewrite(question)
rewrite_questions = rewrite_result['output']
# 合并问题 & 检索文档
questions = [question]
if len(rewrite_questions) > 0:
questions.extend(rewrite_questions)
documents = retrieve(questions)
# 对文档重新排序,取前十条文本作为上下文
documents = rerank(question, documents)
documents = list(sorted(documents, key=lambda x:x['score'], reverse=True))[:10]
documents = list(map(lambda x:x['document'], documents))
contents = list(map(lambda x:x.page_content, documents))
context = '\n'.join(contents)
# 生成答案
answer = generate(question, context)
下面是博主在本地调试时实际生成的答案,站在我的角度,这个结果相比于从前,可谓是云泥之别:

源代码参考:https://github.com/Regularly-Archive/2024/blob/main/KnowledgeBase/others/rewrite_rerank.py
本文小结
当写完这篇文章的时候,我终于意识到,相比于剖析抽象的社科文化,我果然还是喜欢更喜欢逻辑推理。正如文科生更侧重于表达感受,而理科生更倾向于陈述事实。思维方式上的差异,最终造成了双方在行动上的差异。所以,在文科生那里你听到的都是批判、质疑,而在理科生这里你听到的则是论证、实验。前者强调人文关怀,比如人类的情感、价值观、道德感、历史等等;而后者强调逻辑思维,比如可观测的事实、可量化的数据等等。当然,对我个人而言,无论是否发生此次小红书事件,我都会去尝试将 Rewrite 和 Rerank 这两个步骤整合进 RAG 里,真正令我感到沮丧的,是社交媒体上对第一性原理的无视。如你所见,通过实际的 Python 代码示例以及 LangChain 库的应用,我们展示了如何实现 Rewrite 和 Rerank。最终,我们得到的结论是:这两个步骤对于提高检索的多样性、准确性,以及生成答案的相关性至关重要。当然,如果单单从信息检索的角度来看,RAG 里其实并没有多少创新的东西,只不过在搭上 AI 这辆顺风车以后,一切都显得瞬间高级了起来。但是,希望大家能够明白一件事情,那就是:RAG 的核心永远都是 Retrieval,本文完。


