随着 ChatGPT 的兴起及其背后的 AIGC 产业不断升温,向量数据库已成为备受业界瞩目的领域。FAISS、Milvus、Pinecone、Chroma、Qdrant 等产品层出不穷。市场调研公司 MarketsandMarkets 的数据显示,全球向量数据库市场规模预计将从 2020 年的 3.2 亿美元增长至 2025 年的 10.5 亿美元,年均复合增长率高达 26.8%。这表明向量数据库正从最初的不温不火逐步演变为大模型的 “超级大脑”。向量数据库,不仅解决了大模型在 “事实性” 和 “实时性” 方面的固有缺陷,还为企业重新定义了知识库管理方式。此外,与传统关系型数据库相比,向量数据库在处理大规模高维数据方面具有更高的查询效率和更强的处理能力。因此,向量数据库被认为是未来极具潜力的数据库产品。然而,面对非结构化数据的挑战,传统的关系型/非关系型数据库并未坐以待毙,开始支持向量数据库的特性,PostgrelSQL 就是其中的佼佼者。本文探讨的主题是:如何利用 PostgreSQL 实现向量检索以及全文检索。
从大模型的内卷说起
截止目前,OpenAI 官方支持的上下文长度上限为 128K,即 128000 个 token,这意味着它最多可支持约 64000 个汉字的内容。当然,如果考虑到输入、输出两部分的 token 消耗数量,这 64000 个汉字多少要大打折扣。除此以外,国外的 Claude 2、国内的 Moonshot AI,先后将上下文长度提升到 200K 量级,这似乎预示着大模型正在朝着 “更多参数” 和 “更长上下文” 两个方向“内卷”。众所周知的是,现阶段大模型的训练往往需要成百上千的显卡,不论是“更多参数”还是“更长上下文”,本质上都意味着成本增加,这一点,从 Kimi 近期的宕机事件就可以看出。

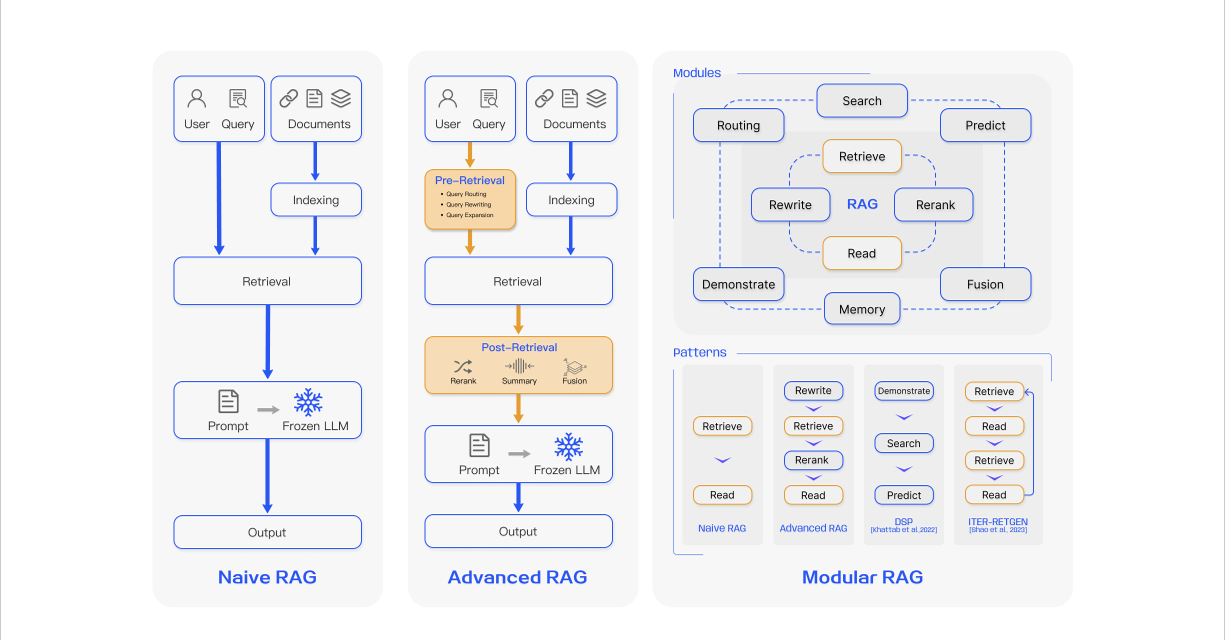
所以,为什么说 RAG(Retrieval-Augmented Generation) 是目前最为经济的 AI 应用开发方向呢?因为它在通过外挂知识库 “丰富” 大模型的同时,能更好地适应当前 “上下文长度受限” 这一背景。诚然,如果有一天,随着技术的不断发展,芯片的价格可以变得低廉起来,大模型可以天然地支持更长的上下文长度,或许大家就不需要 RAG 了。可至少在 2024 年这个时间节点下,不管是企业还是个人,如果你更看重知识库私有化和数据安全,RAG 始终是绕不过去的一个点。同济大学在 Retrieval-Augmented Generation for Large Language Models: A Survey 这篇论文中提出了 RAG 的三种不同范式,如下图所示:
实现向量检索
PostgreSQL,可以说是目前世界上功能最强大的数据库系统之一。针对这个观点,请你先不要急着反驳我。因为,你可以利用这个时间来阅读下面这篇文章《技术极简主义:一切皆用 Postgres》。更不必说,这篇文章里的内容,对于整个 PostgreSQL 生态而言,不过是沧海一粟。单单是向量检索这个话题,你可以看到诸如 pase、pgvector、pg_embedding、pg_vectorize 等解决方案。这里,博主以 pgvector 这个插件为例来进行说明。
pgvector 基本使用
CREATE EXTENSION IF NOT EXISTS vector;
首先,我们使用上面的 SQL 语句来启用 pgvector 插件。此时,我们可以创建一张表来存储向量数据:
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));
接下来,准备若干条数据进行查询测试,可以注意到,这里的向量为三维向量:
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'), ('[7,8,9]');
现在,假设我们有一个向量为:[3,2,1],如何查询距离该向量最近的数据呢?
# L2/欧式距离
SELECT *, embedding <-> '[3,2,1]' AS distance FROM items ORDER BY distance ASC;
# 向量内积
SELECT *, (embedding <#> '[3,2,1]') * -1 AS distance FROM items ORDER BY distance ASC;
# 余弦相似
SELECT *, (1 - (embedding <=> '[3,1,2]')) AS distance FROM items ORDER BY distance ASC;
注意到,这里我们有三种表示距离的方法,即:欧式距离、向量内积和余弦相似,下面是对应的查询结果:
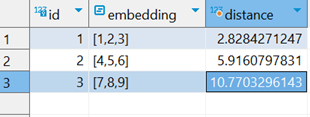
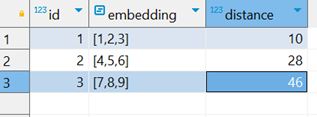
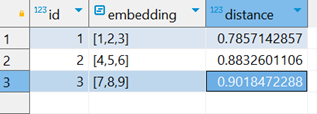
可以注意到,不管是哪一种方案,距离 [3,2,1] 最近的向量始终都是 [1,2,3],这完全符合我们的预期。在 RAG 的场景中,向量通常由 Embedding 模型来生成,其维度可能会达到 1024 甚至更高。考虑到,pgvector 最多支持 16000 个维度的向量,所以,当你准备开发一款 AI 应用时,PostgreSQL 可以兼顾关系型数据库和向量数据库。对于高维度的向量计算,你可以使用索引来加快查询速度,pgvector 支持 HNSW 和 IVFFlat 两种索引:
| 索引 | HNSW | IVFFlat |
|---|---|---|
| 特点 | 查询性能较好;构建时间慢、占用内存多 | 查询性能较差;构建时间快、占用内存少 |
| 原理 | 多层图查询 | 将向量划分为列表,搜索距离最近的子列表 |
| 支持类型 | vector, halfvec、bit、sparsevec | vector |
这里要注意的是,虽然 pgvector 最多支持 16000 个维度的向量,但不管是 HNSW 还是 IVFFlat 索引,它们最多支持 2000 个维度的向量。此外,halfvec、bit、sparsevec 这三种类型目前都还是 unreleased 状态,所以,两种索引算是平分秋色。下面是创建索引的 SQL 语句语法说明:
# HNSW 索引
## L2/欧式距离索引
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops);
## 向量内积索引
CREATE INDEX ON items USING hnsw (embedding vector_ip_ops);
## 余弦相似索引
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops);
# IVFFlat 索引
## L2/欧式距离索引
CREATE INDEX ON items USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);
## 向量内积索引
CREATE INDEX ON items USING ivfflat (embedding vector_ip_ops) WITH (lists = 100);
## 余弦相似索引
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
pgvector 与 EFCore 集成
对于像博主这样使用 C#/.NET 进行开发的朋友,我们可以使用 pgvector-dotnet 这个项目,这里以 Entity Framework Core 为例:
dotnet add package Pgvector.EntityFrameworkCore
为了继续沿用上面的例子,为此,我们定义下面的实体类。一个非常实用的小技巧是:如果你不确定向量的维数,可以不用写这个 [Column] 特性。当然,整张表中的向量维数应该是相同的,就像两个矩阵在相乘时应该满足特定的条件一样,你还记得是什么样的条件吗?:smile:
class Item
{
public int Id { get; set; }
[Column(TypeName = "vector(3)")]
public Vector? Embedding { get; set; }
}
此时,我们就可以像平时一样向数据库中插入一个向量:
ctx.Items.Add(new Item { Embedding = new Vector(new float[] { 1, 2, 3 }) });
ctx.SaveChanges();
当然,查询会稍微不同,因为 LINQ 中没有计算距离相关的表达式:
var embedding = new Vector(new float[] { 1, 1, 1 });
var items = await ctx.Items
.OrderBy(x => x.Embedding!.L2Distance(embedding))
.Take(5)
.ToListAsync();
除了上面的 L2Distance,我们还可以使用 MaxInnerProduct 和 CosineDistance 两个函数,它们都属于 Vector 类型的扩展方法,这里不再详细展开说明。
// HNSW 索引
modelBuilder.Entity<Item>()
.HasIndex(i => i.Embedding)
.HasMethod("hnsw")
.HasOperators("vector_l2_ops")
.HasStorageParameter("m", 16)
.HasStorageParameter("ef_construction", 64);
// IVFFlat 索引
modelBuilder.Entity<Item>()
.HasIndex(i => i.Embedding)
.HasMethod("ivfflat")
.HasOperators("vector_l2_ops")
.HasStorageParameter("lists", 100);
可以注意到,我们依然可以使用 HNSW 和 IVFFlat 这两种索引,并且其参数与 pgvector 完全一致。实际上,如果你使用过 LangChain 或者 Semantic Kernel 这类 LLM 框架,你就会发现没有银弹,它们正在做的事情,无非就是屏幕前的你和我,想要去努力搞清楚的东西。如下图所示,LangChain 和 Semantic Kernel 均支持使用 PostgreSQL 作为其向量数据库:
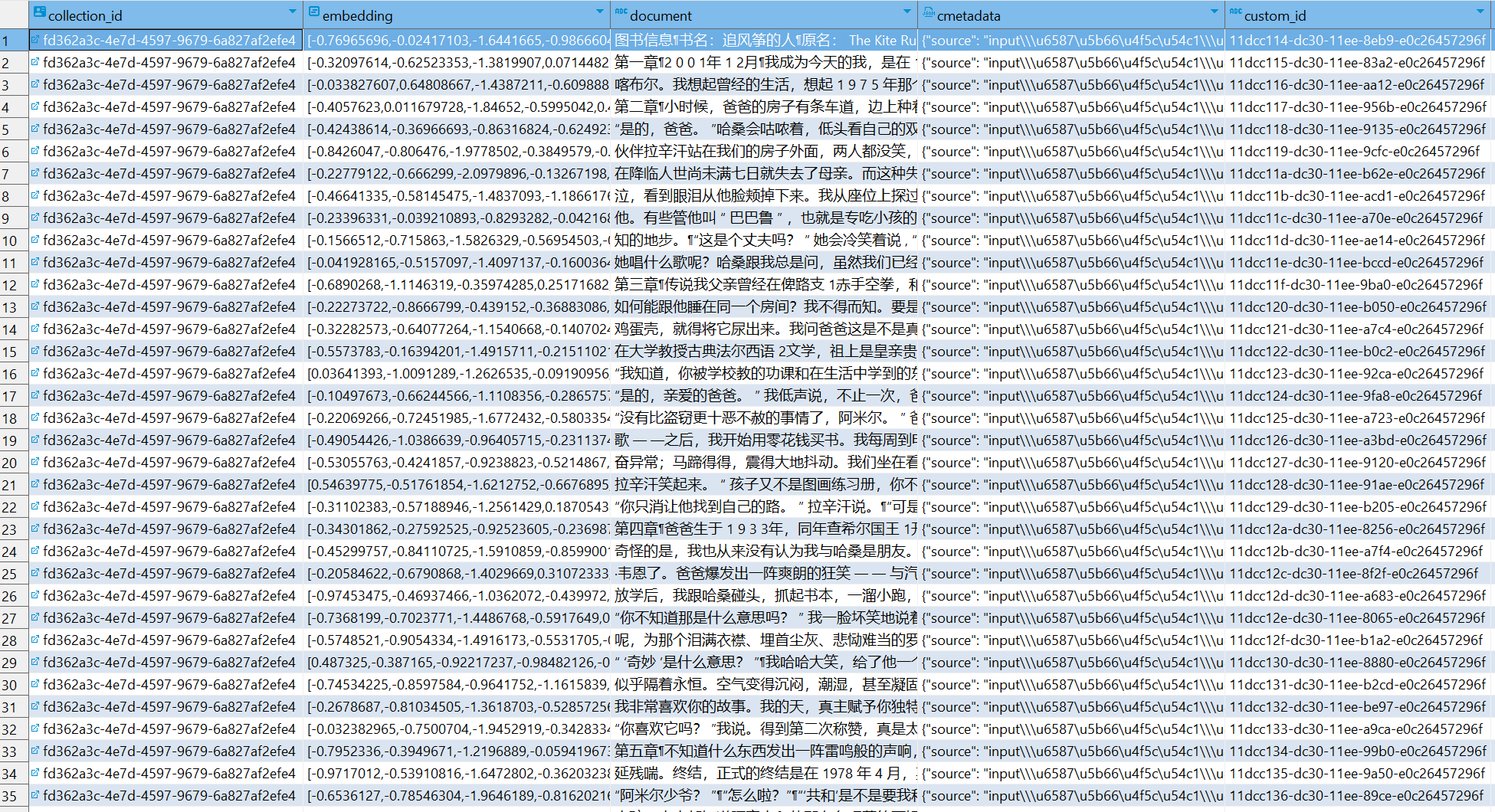
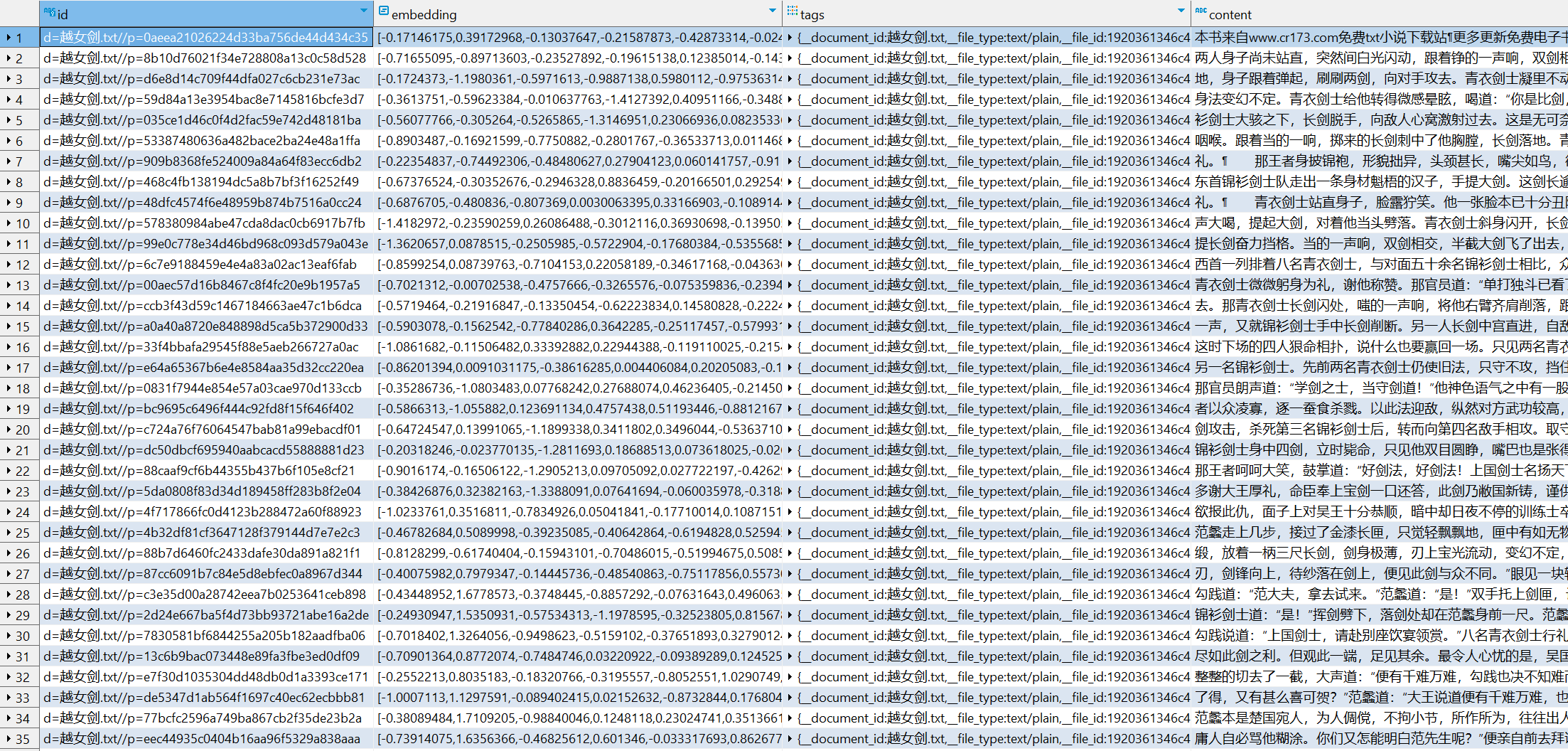 PostgreSQL 在 Semantic Kernel 中的应用
PostgreSQL 在 Semantic Kernel 中的应用
此时此刻,想来你应该明白了 RAG 的工作原理。当我们输入一个问题后,首先会由 Embedding 模型将其转化为一个向量,然后我们从向量数据库中找出距离该向量最近的若干条记录,并将这些记录对应的文本信息作为 LLM 的上下文。此时,LLM 就会整合这些信息并输出最终答案。
可是这样就足够了吗?我想,或许还不太够。因为如果你按照这个思路实践下来,你会发现通过向量检索出来的内容,其相关性或许并不强,所以,现在业界主要的精力都放在了 Retrieval 上,提出了诸如 Rerank、Rewrite 的方案,例如针对相关性排序、对输入的问题进行重写或者同时生成多个相似问题等。
实现全文检索
在开发基于 Semantic Kernel 的 AI 应用时,其实我对于 PostgreSQL 的认知完全是渐进式的,在熟悉了 pgvector 插件的使用以后,我开始尝试去了解 PostgreSQL 中的类型。最终,它们促使我实现了某些 Semantic Kernel 中没有的功能。此前关注 FastGPT 这个项目的时候,我注意到,它除了支持常规的向量检索外,还支持全文检索。因此,我想知道基于全文检索的检索方案,相比于向量检索的检索方案是否更具有性价比。毕竟,通过 LLM 生成向量需要消耗 token 以及时间,并且当文件内容发生变化时更新向量很麻烦。所以,下面我们来聊一聊如何利用 PostgreSQL 实现全文检索,即:在对输入的问题进行分词处理后,直接去检索含有该关键字的内容。
PostgreSQL 对全文检索的支持
与 pg_vector 不同,PostgreSQL 天然支持全文检索特性,唯一不同的地方在于分词器。比如,中文和英文的分词规则显然不同。此时,我们就可以使用 zhparser、pg_jieba、nlpbamboo、SCWS 等支持中文分词的插件。不用这些插件是否可以呢?经过博主测试,官方自带的分词器,在处理类似 “西施”、“勾践” 的关键字时,无法检索到相关的内容,可见分词器的影响还是很大的。可惜,插件丰富的 PostgreSQL 和 Nginx 一样,安装第三方模块总避免不了折腾一番。下面,博主将以 pg_jieba 为例进行说明:

如图所示,PostgreSQL 自带了一个分词器 default ,你可以使用下面的 SQL 语句进行查询:
select * from pg_ts_parser
在此基础上,PostgreSQL 创建一组用于全文检索的配置,使用下面的 SQL 语句进行查询:
select * from pg_ts_config
此时,你会得到看到下面的结果:
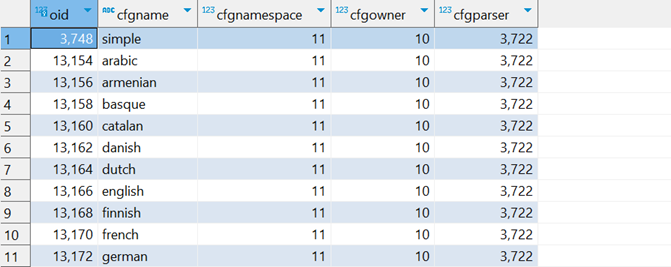
其中:3722 是 default 这个分词器的唯一标识,并且这里面目前没有针对中文的配置。PostgreSQL 主要提供三类函数来支持全文检索,它们分别是文档解析函数、查询解析函数以及排序函数:
- 文档解析函数:即 to_tsvector() 函数,负责对指定的字符进行分词。例如,当输入下列命令时,将返回字符串中的每个单词及其序号:
SELECT to_tsvector('simple','nothing is true everything is permitted')

- 查询解析函数:即 to_tsquery()、plainto_tsquery()、phraseto_tsquery() 和 websearch_to_tsquery() 这四个函数,它们负责将指定的字符串转化为表达式。例如,以下命令表示,包含 nothing 或者同时包含 is 和 true:
SELECT to_tsquery('simple','nothing | (is & true)')

更多的细节,请参考官方文档:http://www.postgres.cn/docs/12/textsearch-controls.html
- 排序函数:即 ts_rank() 和 ts_rank_cd(),它们负责计算给定文档与特定查询中的相关性。例如,下面的例子展示了内容与关键词间的相关性:
select
'nothing is true everything is permitted' as content,
'nothing | true' as keywords,
ts_rank_cd(
to_tsvector('english','nothing is true everything is permitted'),
to_tsquery('english','nothing | true')
) as relevance
现在,结合以上知识,假设我们希望从数据中查询符合特定关键字的内容,我们可以像下面这样编写 SQL 语句:
SELECT
t.*,
ts_rank_cd(
to_tsvector('english', t.content),
to_tsquery('english', '范蠡 & 阿青 | 夫差')
) AS relevance
FROM
"sk-default" t
WHERE
t.content @@ to_tsquery('english', '范蠡 & 阿青 | 夫差')
ORDER BY
relevance DESC;
其中, @@ 操作符的作用是将待检索的字段与检索条件连接起来。此时,结果如下图所示:

结果显示,我们给定的关键词与内容之间的相关性为:0.025,通过这个信息,理论上我们就可以找出我们真正需要的信息。而这便是目前 PostgreSQL 在全文检索方面能达到的程度。对此,大家是否感到满意呢?
使用 pg_jieba 增强中文检索
《越女剑》是金庸先生创作的短篇武侠小说,以春秋末期的吴越争霸作为历史背景,讲述了阿青被范蠡引荐到宫中教授士兵剑术,最终帮助越王勾践复仇雪耻的故事。在教授剑术的过程中,阿青暗自喜欢上了范蠡,而范蠡则喜欢西施,内心深感不忿的阿青找上范蠡和西施,在相互争执的过程中,阿青竹棒上的劲力伤及西施,自此后世留下了 “西子捧心” 的传奇佳话。从这个故事中,我们不难发现,范蠡、阿青、夫差等历史人物悉数登场。但是,我们通过全文检索仅仅得到了一条记录,这是为什么呢?答案便在于上面提到的分词器。所以,下面我们尝试使用 pg_jieba 这个插件来强化检索效果,关于这个插件的安装请参考官方文档,博主这里提供一个开箱即用的方案供大家参考:

接下来,我们首先需要启用 pg_jieba 插件:
CREATE EXTENSION IF NOT EXISTS pg_jieba;
现在,如果我们再次查询分词器信息:
select * from pg_ts_parser
你会注意到,这里多了几个分词器,这些便是 pg_jieba 插件提供的分词器:

如果你继续查询全文检索的配置信息,你将会由类似的发现:
select * from pg_ts_config
此时,你会看到下面的结果:

现在,我们就可以直接使用 jiebacfg 这个配置来进行查询:
SELECT
t.*,
ts_rank_cd(
to_tsvector('jiebacfg', t.content),
to_tsquery('jiebacfg', '范蠡 & 阿青 | 夫差')
) AS relevance
FROM
"sk-default" t
WHERE
t.content @@ to_tsquery('jiebacfg', '范蠡 & 阿青 | 夫差')
ORDER BY
relevance DESC;
有时候,你可能希望创建自己的全文检索配置,此时,你可以使用下面的 SQL 语句:
# 拷贝一个现有配置
CREATE TEXT SEARCH CONFIGURATION my_english (copy = english);
# 创建一个全新的配置
CREATE TEXT SEARCH CONFIGURATION my_jieba (parser = 'jieba');
当然,你还可以通过创建索引来提升全文检索的效率,使用下面的 SQL 语句即可:
CREATE INDEX idx_full_text_search ON "sk-default" USING GIN(to_tsvector('jiebacfg', content));
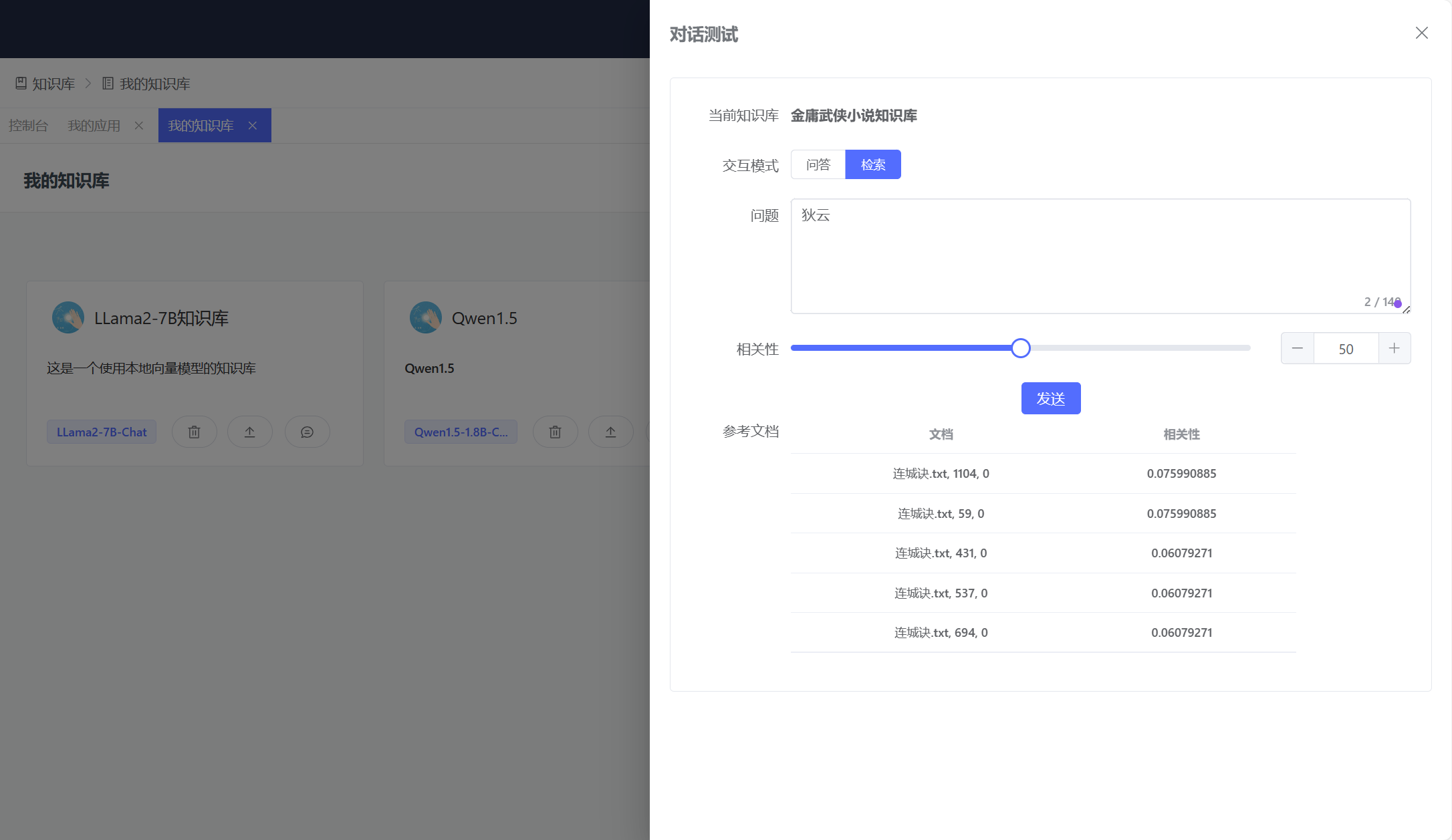
最终,博主采用全文检索 + 模糊匹配(LIKE) 的方式完成了整个设想,因为其中包含相关性及检索数目的控制,所以,我个人感觉这个方案比单纯的向量检索要更为经济一点,毕竟,通过 Embedding 模型生成向量需要时间和金钱,除非你使用一个本地的离线模型来完成这个工作。到目前为止,知识库可以使用向量检索或者全文检索,我认为,在实际场景中完全可以将这两种方案结合起来使用。如下图所示,当博主向知识库提问的时候,它已经可以给出非常接近事实的答案,虽然这个答案依然令人捧腹,哈哈!
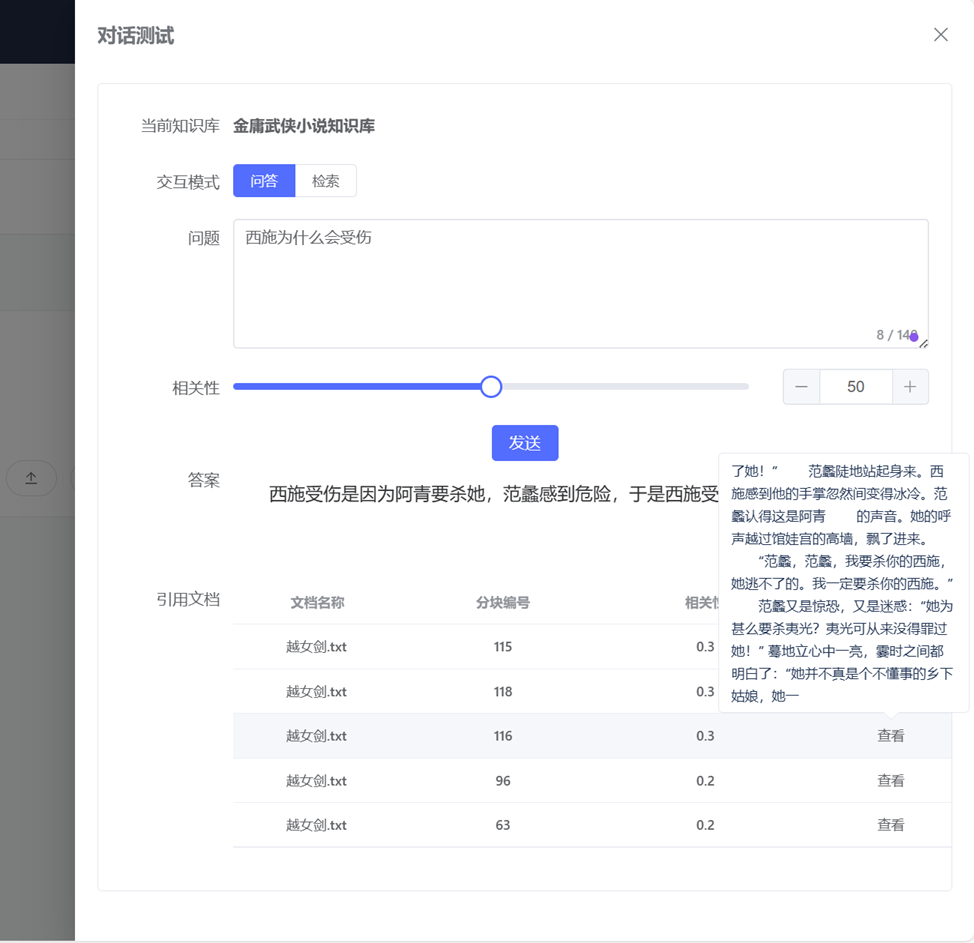
至此,基于 PostgreSQL 的全文检索方案完成落地,大家对这个方案的表现还满意吗?
本文小结
或许,我每次写博客的时候,都没有办法做到 100% 的完全遵从写作计划。就像这篇文章,我一开始的规划仅仅是写 pgvector,但我总感觉这些零零散散的内容,不值得专门去写一篇文章。直到拖延了将近半个月以后,我发觉基于 PostgreSQL 的全文检索方案可以作为 Semantic Kernel 的一个改进点,经过一番权衡和上下求索,总算是完成了这篇文章的写作。本文的核心要点其实只有两个,其一是选择 PostgreSQL 作为当下 AI 应用开发中的向量数据库,其二是利用 PostgreSQL 的全文搜索特性强化知识库检索。其实,采用向量还是文本进行检索,本质上只是一种查询媒介的选择,真正有价值的是在检索过程中的种种思考。比如,如何对搜索结果进行排序、如何根据用户的输入产生相似的问题等等,从表面上看,这是一个 AI 应用开发的问题,然而,从更深刻地角度来看,这其实是一个信息检索的问题。作为李彦宏先生曾经的粉丝,我非常希望百度可以在搜索引擎中引入 AI 技术,毕竟,RAG 这个方向的 AI 应用,其着眼点还是在信息的检索上。虽然大家都在质疑 Kimi 的 200K 上下文到底是不是真的 200K,可如果一件事情能通过 RAG 这种更经济、更环保的方式实现,还能让用户感到心悦诚服的话,何乐而不为呢?最后,请允许我推荐一个最近正在使用的 AI 搜索引擎:秘塔AI搜索,真的比百度好用! 🫡


